Instal komponen AI/ML, pantau resource GPU, dan kelola kuota tim pada kluster ACK Pro.
Tiga tugas inti: instal suite, lihat dasbor resource, dan kelola pengguna serta kuota dengan penjadwalan kapasitas.
Prasyarat
Sebelum memulai:
-
Kluster ACK Pro yang menjalankan Kubernetes 1.18 atau versi lebih baru
-
add-on monitoring dan Simple Log Service diaktifkan pada halaman Component Configurations selama pembuatan kluster
Konsep utama
Batas keamanan
Kubernetes adalah orchestrator single-tenant: satu control plane melayani semua tenant dalam sebuah kluster. Kluster merupakan satu-satunya batas keamanan yang bersifat mutlak. Struktur pohon kuota, grup pengguna, dan namespace menyediakan pembatas organisasi dan isolasi logis—bukan jaminan keamanan yang setara dengan pemisahan tingkat kluster. Rancang arsitektur multi-tenant Anda sesuai dengan prinsip ini.
Cara kerja penjadwalan kapasitas
Setiap node kuota dalam pohon kuota memiliki dua parameter:
-
Min: resource minimum yang dijamin dapat selalu diklaim oleh namespace, bahkan ketika kluster mengalami tekanan
-
Max: resource maksimum yang dapat digunakan namespace saat kapasitas idle tersedia
Namespace lain dapat meminjam kapasitas idle hingga mencapai nilai Max-nya. Ketika namespace pemilik membutuhkan kembali alokasi minimumnya, penjadwal akan menarik kembali resource tersebut dengan mempertimbangkan prioritas workload, ketersediaan, dan waktu pembuatan.
Objek sumber daya
| Object | Role |
|---|---|
| Quota tree | Struktur alokasi resource hierarkis |
| Quota node | Node dalam pohon; setiap leaf node dipetakan ke satu atau beberapa namespace |
| User group | Unit alokasi terkecil; dipetakan ke leaf quota node |
| User | Memiliki akun layanan Kubernetes untuk mengirim pekerjaan dan mengakses konsol |
| Namespace | Namespace Kubernetes yang di-bind ke leaf quota node |
Peran pengguna
| Role | Permissions |
|---|---|
| admin | Masuk ke AI Dashboard, kelola komponen kluster, dan memiliki semua izin peneliti |
| researcher | Kirim pekerjaan, gunakan resource kluster, masuk ke AI Developer Console |
Langkah 1: Instal Cloud-native AI Suite
Suite ini memiliki enam kategori komponen—instal hanya yang dibutuhkan oleh workload Anda. Arena dipilih secara default dan wajib diinstal.
| Component category | Purpose | Install separately? |
|---|---|---|
| Task elasticity | Skalakan workload AI secara dinamis | Tidak |
| Data acceleration | Percepat akses dataset | Tidak |
| AI task scheduling | Jadwalkan workload AI dengan kebijakan yang mempertimbangkan kapasitas | Tidak |
| AI task lifecycle management | Kelola siklus hidup pekerjaan pelatihan | Tidak |
| AI Dashboard | Pantau resource GPU dan kuota | Ya (memerlukan izin RAM) |
| AI Developer Console | Kirim dan kelola pekerjaan AI | Ya (memerlukan izin RAM) |
Deploy suite
-
Masuk ke Konsol ACK, lalu klik Clusters di panel navigasi kiri.
-
Klik nama kluster, lalu pilih Applications > Cloud-native AI Suite di panel kiri.
-
Klik Deploy.
-
Pilih komponen dan klik Deploy Cloud-native AI Suite. Sistem akan memeriksa dependensi sebelum melakukan deployment. Setelah instalasi, daftar Components memungkinkan Anda untuk Deploy, Upgrade, atau Uninstall komponen individual.
-
Setelah menginstal
ack-ai-dashboarddanack-ai-dev-console, tautan ke AI Dashboard dan AI Developer Console akan muncul di halaman Cloud-native AI Suite.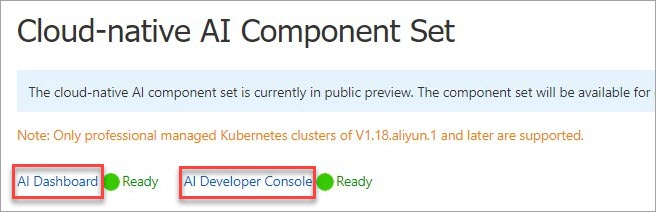
Konfigurasi AI Dashboard
Sejak 22 Januari 2025, AI Console (AI Dashboard dan AI Developer Console) memerlukan akses daftar putih. Deployment yang dilakukan sebelum tanggal tersebut tidak terpengaruh. Pengguna yang tidak termasuk dalam daftar putih dapat menggunakan Open-source AI Console sebagai gantinya.
Berikan izin RAM ke peran pekerja
Sebelum AI Dashboard dapat mengakses data kluster, sambungkan kebijakan RAM kustom ke peran worker kluster.
-
Buat kebijakan kustom.
-
Masuk ke Konsol RAM, lalu pilih Permissions > Policies pada panel navigasi kiri.
-
Klik Create Policy, pilih tab JSON, lalu tambahkan kebijakan berikut:
{ "Version": "1", "Statement": [ { "Effect": "Allow", "Action": [ "cs:*", "log:GetProject", "log:GetLogStore", "log:GetConfig", "log:GetMachineGroup", "log:GetAppliedMachineGroups", "log:GetAppliedConfigs", "log:GetIndex", "log:GetSavedSearch", "log:GetDashboard", "log:GetJob", "ecs:DescribeInstances", "ecs:DescribeSpotPriceHistory", "ecs:DescribePrice", "eci:DescribeContainerGroups", "eci:DescribeContainerGroupPrice", "log:GetLogStoreLogs", "ims:CreateApplication", "ims:UpdateApplication", "ims:GetApplication", "ims:ListApplications", "ims:DeleteApplication", "ims:CreateAppSecret", "ims:GetAppSecret", "ims:ListAppSecretIds", "ims:ListUsers" ], "Resource": "*" } ] } -
Beri nama kebijakan
k8sWorkerRolePolicy-{ClusterID}dan klik OK.
-
-
Sambungkan kebijakan ke peran worker kluster.
-
Di Konsol RAM, pilih Identities > Roles dan cari
KubernetesWorkerRole-{ClusterID}. -
Klik Grant Permission.
-
Di Select Policy, klik Custom Policy, cari
k8sWorkerRolePolicy-{ClusterID}, pilih, lalu klik OK.
-
Selesaikan penyiapan AI Dashboard
-
Di halaman Cloud-native AI Suite, pilih Sample Console untuk Interaction Mode. Kotak dialog Note akan muncul.
-
Jika ditampilkan Authorized, lanjutkan ke langkah 3.
-
Jika muncul Unauthorized berwarna merah, lengkapi izin RAM seperti di atas dan klik Authorization Check. Setelah otorisasi berhasil, status Authorized akan ditampilkan.
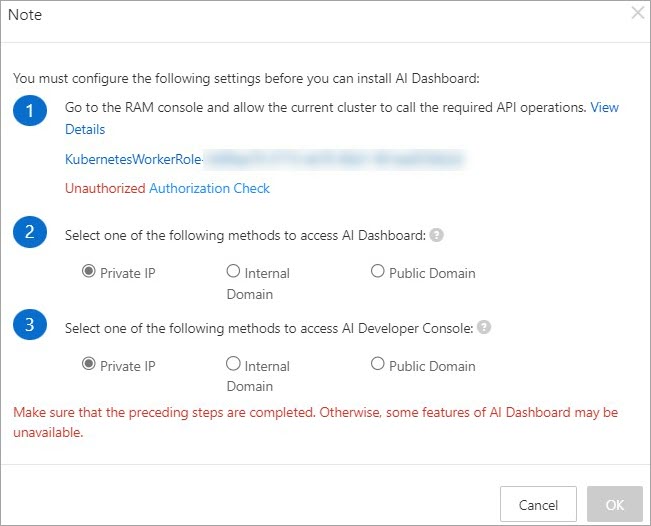
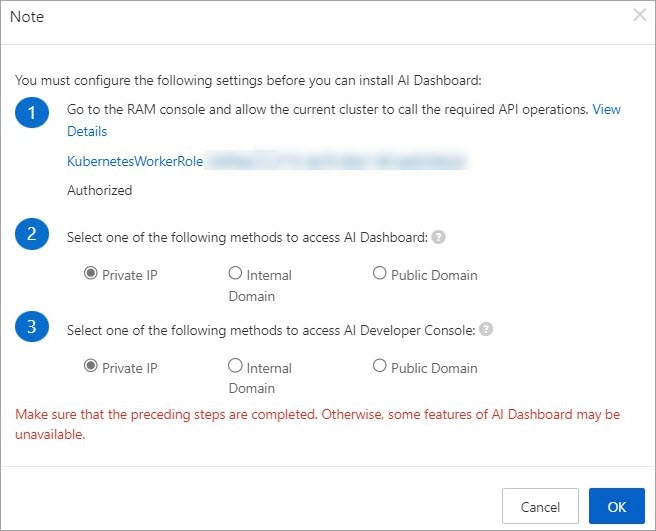
-
-
Atur Console Data Storage: Pre-installed MySQL untuk pengujian atau ApsaraDB RDS untuk produksi. Lihat Instal dan konfigurasi AI Dashboard dan AI Developer Console.
-
Klik Deploy Cloud-native AI Suite. AI Dashboard siap digunakan ketika statusnya menunjukkan Ready.
(Opsional) Buat dan percepat dataset
Mount dataset dari Object Storage Service (OSS) sebagai persistent volume (PV) dan percepat aksesnya di AI Dashboard.
Buat PV dan PVC
-
Buat namespace:
kubectl create ns demo-ns -
Buat file bernama
fashion-mnist.yaml:Placeholder Description Example fashion-mnistNama bucket OSS my-dataset-bucket oss-cn-beijing.aliyuncs.comTitik akhir OSS untuk wilayah bucket oss-cn-hangzhou.aliyuncs.com AKIDAccessKey ID LTAI5tXxx AKSECRETRahasia AccessKey xXxXxXx apiVersion: v1 kind: PersistentVolume metadata: name: fashion-demo-pv spec: accessModes: - ReadWriteMany capacity: storage: 10Gi csi: driver: ossplugin.csi.alibabacloud.com volumeAttributes: bucket: fashion-mnist otherOpts: "-o max_stat_cache_size=0 -o allow_other" url: oss-cn-beijing.aliyuncs.com akId: "AKID" akSecret: "AKSECRET" volumeHandle: fashion-demo-pv persistentVolumeReclaimPolicy: Retain storageClassName: oss volumeMode: Filesystem --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: fashion-demo-pvc namespace: demo-ns spec: accessModes: - ReadWriteMany resources: requests: storage: 10Gi selector: matchLabels: alicloud-pvname: fashion-demo-pv storageClassName: oss volumeMode: Filesystem volumeName: fashion-demo-pvGanti placeholder berikut:
-
Terapkan manifes:
kubectl create -f fashion-mnist.yaml -
Verifikasi PV dan PVC telah terikat:
kubectl get pv fashion-demo-pv kubectl get pvc fashion-demo-pvc -n demo-nsOutput yang diharapkan untuk PV:
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS AGE fashion-demo-pv 10Gi RWX Retain Bound demo-ns/fashion-demo-pvc oss 8hOutput yang diharapkan untuk PVC:
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE fashion-demo-pvc Bound fashion-demo-pv 10Gi RWX oss 8h
Accelerate the dataset
-
Masuk ke AI Dashboard sebagai administrator.
-
Pilih Dataset > Dataset List di panel navigasi kiri.
-
Temukan dataset (
fashion-demo-pvc) dan klik Accelerate di kolom ActionsOperator.
Langkah 2: Lihat dasbor resource
AI Dashboard menyediakan empat tampilan, masing-masing mencakup aspek berbeda dari kondisi resource GPU.
Batasan daftar putih AI Console berlaku di sini. Pengguna yang tidak termasuk dalam daftar putih dapat mengakses dasbor melalui Open-source AI Console.
Dasbor kluster
AI Dashboard membuka dasbor kluster secara default, menampilkan kondisi dan alokasi GPU secara keseluruhan kluster.
| Metric | What it shows |
|---|---|
| GPU Summary Of Cluster | Total node GPU, node GPU yang dialokasikan, node GPU tidak sehat |
| Total GPU Nodes | Total node berakselerasi GPU |
| Unhealthy GPU Nodes | Node GPU dengan isu terdeteksi |
| GPU Memory (Used/Total) | Memori GPU yang digunakan / total memori GPU |
| GPU Memory (Allocated/Total) | Memori GPU yang dialokasikan / total memori GPU |
| GPU Utilization | Rata-rata pemanfaatan GPU secara keseluruhan kluster |
| GPUs (Allocated/Total) | GPU yang dialokasikan / total GPU |
| Training Job Summary Of Cluster | Pekerjaan pelatihan berdasarkan status: Running, Pending, Succeeded, Failed |
GPU Utilization menunjukkan apakah GPU menjalankan pekerjaan apa pun selama jendela sampel, bukan seberapa efisien. Node dengan 100% mungkin menjalankan kernel ringan alih-alih beban kerja paralel berat. Gabungkan dengan GPU Memory (Used/Total) untuk gambaran yang lebih lengkap.
Dasbor node
Klik Nodes di pojok kanan atas halaman Cluster untuk melihat metrik GPU per node dan per perangkat GPU.
| Metric | What it shows |
|---|---|
| GPU Node Details | Tabel per node: nama, IP, peran, mode GPU (eksklusif atau bersama), jumlah GPU, total memori GPU, GPU yang dialokasikan, memori GPU yang dialokasikan, memori GPU yang digunakan, rata-rata pemanfaatan GPU |
| GPU Duty Cycle | Pemanfaatan per perangkat GPU per node |
| GPU Memory Usage | Memori yang digunakan per perangkat GPU per node |
| GPU Memory Usage Percentage | Persentase penggunaan memori per GPU per node |
| Allocated GPUs Per Node | GPU yang dialokasikan per node |
| GPU Number Per Node | Total GPU per node |
| Total GPU Memory Per Node | Total memori GPU per node |
Dasbor pekerjaan pelatihan
Klik TrainingJobs di pojok kanan atas halaman Nodes untuk melihat konsumsi resource dan efisiensi GPU per pekerjaan.
| Metric | What it shows |
|---|---|
| Training Jobs | Tabel per pekerjaan: namespace, nama, jenis, status, durasi, GPU yang diminta, memori GPU yang diminta, memori GPU yang digunakan, rata-rata pemanfaatan GPU |
| Job Instance Used GPU Memory | Memori GPU yang digunakan per instans pekerjaan |
| Job Instance Used GPU Memory Percentage | Persentase memori GPU yang digunakan per instans pekerjaan |
| Job Instance GPU Duty Cycle | Pemanfaatan GPU per instans pekerjaan |
Dasbor kuota resource
Klik Quota di pojok kanan atas halaman Training Jobs untuk melihat konsumsi kuota berdasarkan jenis resource (CPU, memori, nvidia.com/gpu, aliyun.com/gpu-mem, aliyun.com/gpu).
| Column | What it shows |
|---|---|
| Elastic Quota Name | Nama grup kuota |
| Namespace | Namespace tempat kuota diterapkan |
| Resource Name | Jenis resource |
| Max Quota | Resource maksimum yang tersedia |
| Min Quota | Minimum yang dijamin, diprioritaskan saat kluster mengalami tekanan |
| Used Quota | Resource yang sedang digunakan |
Langkah 3: Kelola pengguna dan kuota
Cloud-native AI Suite menggunakan pohon kuota untuk memberlakukan batasan resource hierarkis dan berbagi resource antar tim.
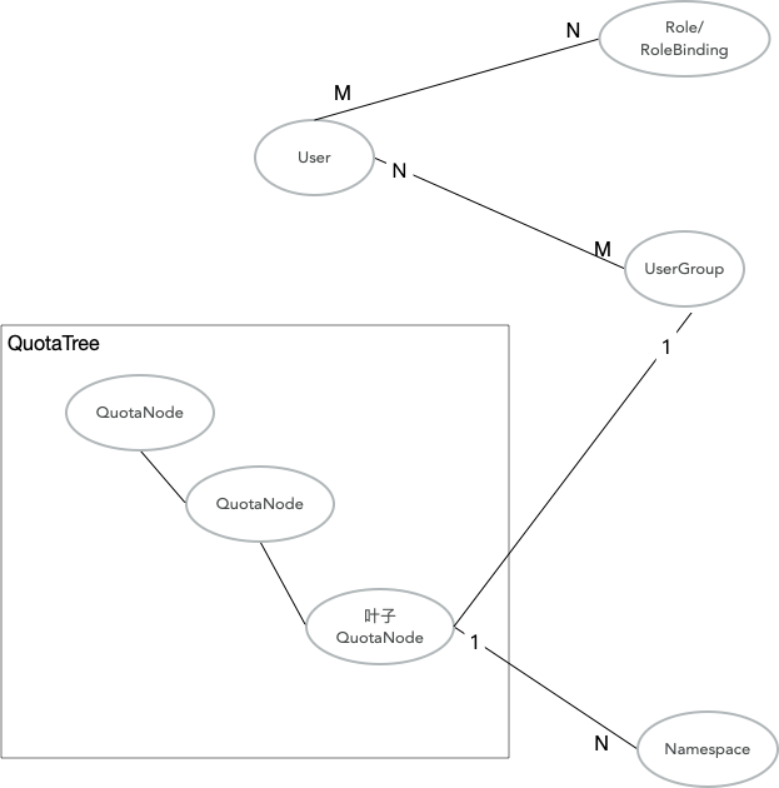
Struktur organisasi dipetakan ke pohon kuota:
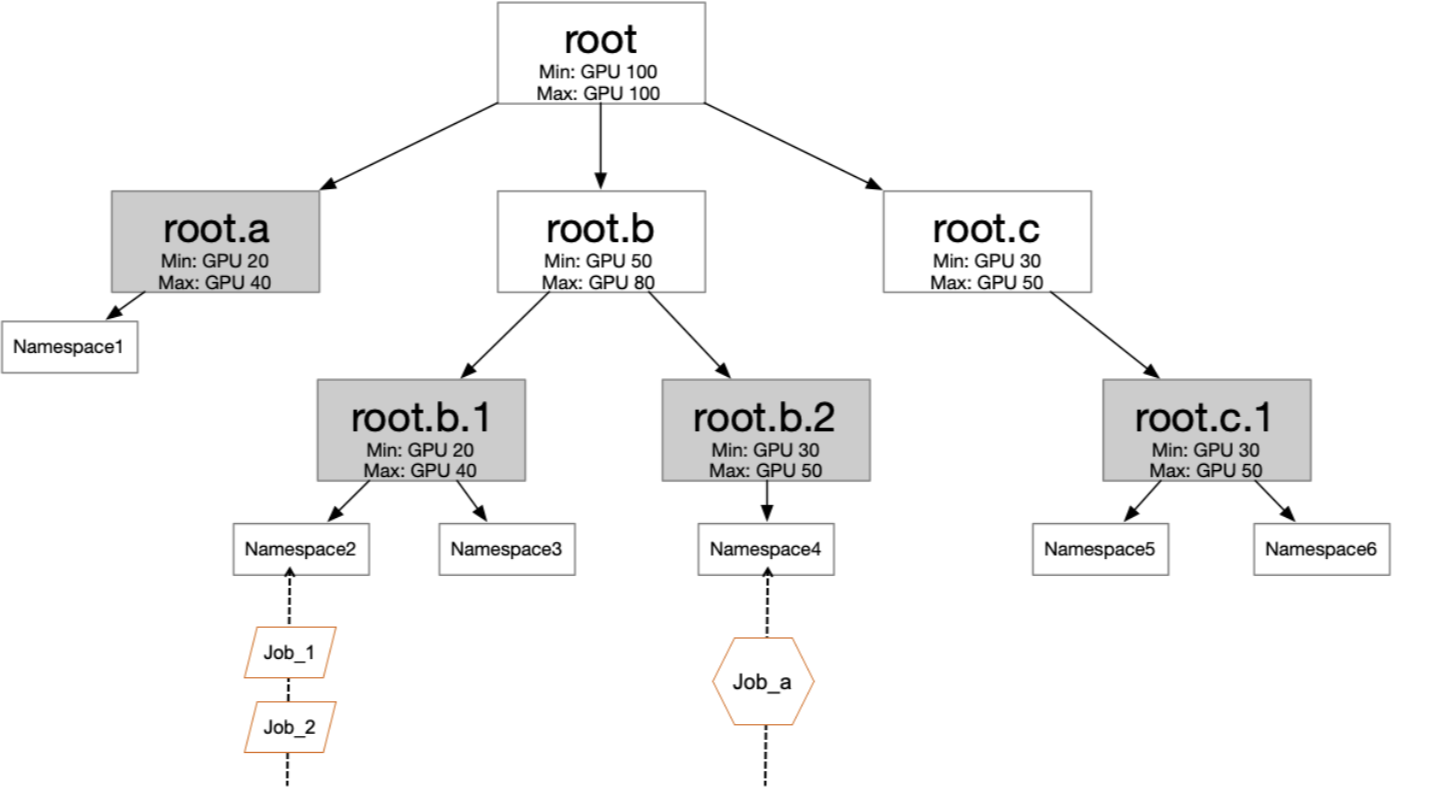
Setiap departemen atau tim dipetakan ke cabang pohon kuota; leaf node di-bind ke namespace. Menetapkan Min dan Max di setiap level memungkinkan tim berbagi resource idle sekaligus menjamin alokasi minimum.
Pohon kuota dan kontrol tingkat namespace menyediakan pembatas organisasi, bukan batas keamanan mutlak. Untuk isolasi tenant yang kuat, gunakan kluster terpisah. Lihat catatan batas keamanan di Konsep utama.
Siapkan pohon kuota
-
Buat namespace untuk setiap tim. Namespace yang sudah ada harus tidak memiliki Pod yang sedang berjalan sebelum dikaitkan dengan node kuota.
kubectl create ns namespace1 kubectl create ns namespace2 kubectl create ns namespace3 kubectl create ns namespace4 -
Di AI Dashboard, buat node kuota dan kaitkan setiap leaf node dengan namespace. Tetapkan Min dan Max untuk setiap node.
Buat pengguna dan grup pengguna
Seorang pengguna dapat menjadi anggota beberapa grup, dan satu grup dapat berisi banyak pengguna. Kaitkan pengguna dengan grup untuk memberikan akses ke resource yang dialokasikan.
-
Buat pengguna. Lihat Buat file kubeconfig dan token login untuk pengguna baru.
-
Buat grup pengguna. Lihat Tambahkan grup pengguna.
Contoh penjadwalan kapasitas
Contoh ini menunjukkan cara penjadwal berbagi dan menarik kembali resource CPU di empat namespace. Pohon kuota memiliki struktur berikut:
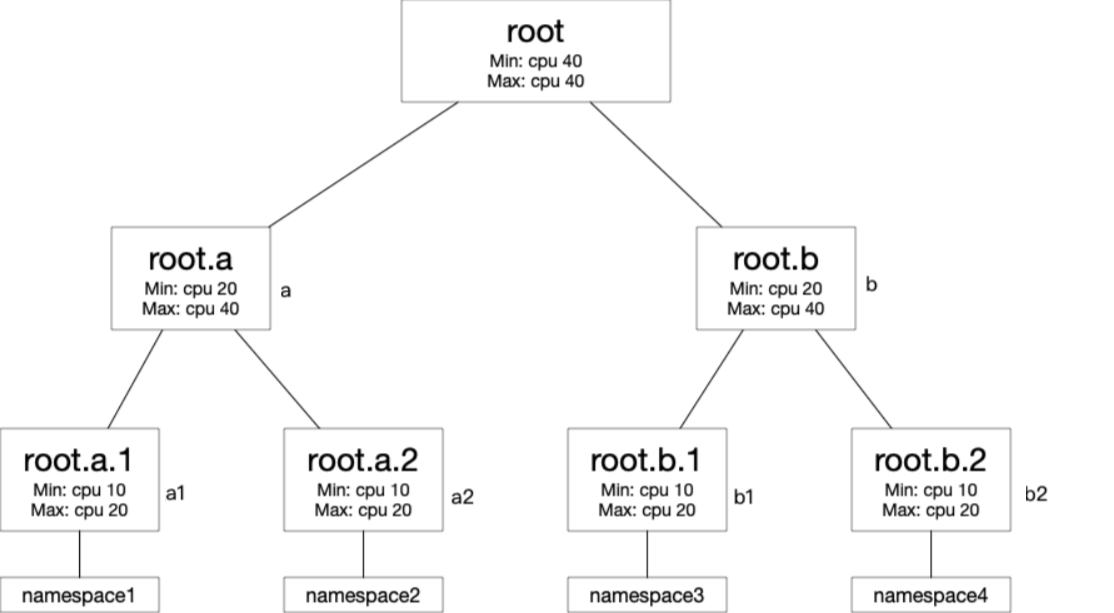
Konfigurasi kuota:
| Quota node | Min (CPU cores) | Max (core CPU) |
|---|---|---|
| root | 40 | 40 |
| root.a | 20 | 40 |
| root.b | 20 | 40 |
| root.a.1 | 10 | 20 |
| root.a.2 | 10 | 20 |
| root.b.1 | 10 | 20 |
| root.b.2 | 10 | 20 |
Panduan:
Tanpa kuota elastis, setiap namespace leaf hanya menggunakan Min-nya (10 core = 2 Pod dengan 5 core/Pod). Dengan kuota elastis dan 40 core kluster tersedia, namespace meminjam kapasitas idle hingga mencapai Max-nya.
Langkah 1: Deploy lima Pod ke namespace1, masing-masing meminta 5 core CPU (total 25 core).
Dengan Max root.a.1 diatur ke 20 core, 4 Pod berjalan (20 core). Pod kelima tetap dalam status Pending.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx1
namespace: namespace1
labels:
app: nginx1
spec:
replicas: 5
selector:
matchLabels:
app: nginx1
template:
metadata:
name: nginx1
labels:
app: nginx1
spec:
containers:
- name: nginx1
image: nginx
resources:
limits:
cpu: 5
requests:
cpu: 5Langkah 2: Deploy lima Pod ke namespace2, masing-masing meminta 5 core CPU.
Dengan 20 core tersisa (40 - 20 dari namespace1), 4 Pod berjalan. Pod kelima tetap dalam status Pending. Baik namespace1 maupun namespace2 kini mengonsumsi seluruh 40 core root.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx2
namespace: namespace2
labels:
app: nginx2
spec:
replicas: 5
selector:
matchLabels:
app: nginx2
template:
metadata:
name: nginx2
labels:
app: nginx2
spec:
containers:
- name: nginx2
image: nginx
resources:
limits:
cpu: 5
requests:
cpu: 5Langkah 3: Deploy lima Pod ke namespace3, masing-masing meminta 5 core CPU.
Tidak ada kapasitas idle yang tersisa. Penjadwal menarik kembali 10 core dari root.a untuk menjamin minimum root.b.1. Penjadwal menarik 5 core dari root.a.1 (mengurangi namespace1 dari 4 Pod berjalan menjadi 3) dan 5 core dari root.a.2 (mengurangi namespace2 dari 4 Pod berjalan menjadi 3). Dengan 10 core yang ditarik kembali, 2 Pod berjalan di namespace3.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx3
namespace: namespace3
labels:
app: nginx3
spec:
replicas: 5
selector:
matchLabels:
app: nginx3
template:
metadata:
name: nginx3
labels:
app: nginx3
spec:
containers:
- name: nginx3
image: nginx
resources:
limits:
cpu: 5
requests:
cpu: 5Langkah 4: Deploy lima Pod ke namespace4, masing-masing meminta 5 core CPU.
Penjadwal menarik kembali 10 core lagi dari root.a untuk menjamin minimum root.b.2: 5 core dari root.a.1 dan 5 dari root.a.2. Setelah penarikan kembali, namespace1 dan namespace2 masing-masing memiliki 2 Pod berjalan (10 core), dan namespace4 mendapatkan 2 Pod berjalan.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx4
namespace: namespace4
labels:
app: nginx4
spec:
replicas: 5
selector:
matchLabels:
app: nginx4
template:
metadata:
name: nginx4
labels:
app: nginx4
spec:
containers:
- name: nginx4
image: nginx
resources:
limits:
cpu: 5
requests:
cpu: 5Hasil:
| Namespace | Quota node | Running pods | CPU cores in use |
|---|---|---|---|
| namespace1 | root.a.1 | 2 | 10 |
| namespace2 | root.a.2 | 2 | 10 |
| namespace3 | root.b.1 | 2 | 10 |
| namespace4 | root.b.2 | 2 | 10 |
Jaminan minimum setiap tim dipenuhi. Kapasitas yang dipinjam ditarik kembali ketika tim lain membutuhkan alokasi minimum mereka.