Untuk layanan inferensi model bahasa besar (LLM) dalam kluster Kubernetes, metode penyeimbangan beban tradisional sering kali mengandalkan alokasi trafik sederhana yang tidak dapat menangani permintaan kompleks dan beban lalu lintas dinamis selama proses inferensi LLM. Topik ini menjelaskan cara mengonfigurasi ekstensi layanan inferensi menggunakan Gateway dengan Ekstensi Inferensi untuk mencapai perutean cerdas dan manajemen trafik yang efisien.
Informasi latar belakang
Model bahasa besar (LLM)
Model bahasa besar (LLM) adalah model berbasis jaringan saraf dengan miliaran parameter, seperti GPT, Qwen, dan Llama. Model-model ini dilatih pada dataset pra-pelatihan yang luas, termasuk teks web, literatur profesional, dan kode, serta digunakan terutama untuk tugas-tugas generasi teks seperti penyelesaian dan dialog.
Untuk memanfaatkan LLM dalam membangun aplikasi, Anda dapat:
Memanfaatkan layanan API LLM eksternal dari platform seperti OpenAI, Alibaba Cloud Model Studio, atau Moonshot.
Membangun layanan inferensi LLM Anda sendiri menggunakan model dan kerangka kerja open-source atau proprietary seperti vLLM, dan menerapkannya di kluster Kubernetes. Pendekatan ini cocok untuk skenario yang memerlukan kontrol atas layanan inferensi atau penyesuaian tinggi kemampuan inferensi LLM.
vLLM
vLLM adalah kerangka kerja yang dirancang untuk konstruksi layanan inferensi LLM yang efisien dan ramah pengguna. Ini mendukung berbagai model bahasa besar, termasuk Qwen, dan mengoptimalkan efisiensi inferensi LLM melalui teknik seperti PagedAttention, inferensi batch dinamis (Continuous Batching), dan kuantisasi model.
Cache KV
Prosedur
Gambar berikut adalah bagan alur.
Di inference-gateway, port 8080 diatur dengan rute HTTP standar untuk meneruskan permintaan ke layanan inferensi backend. Port 8081 merutekan permintaan ke ekstensi layanan inferensi (LLM Route), yang kemudian meneruskan permintaan ke layanan inferensi backend.
Di HTTP Route, sumber daya InferencePool digunakan untuk mendeklarasikan sekelompok beban kerja layanan inferensi LLM di kluster. Konfigurasikan InferenceModel untuk menentukan kebijakan distribusi trafik untuk model yang dipilih dalam InferencePool. Dengan cara ini, permintaan yang dirutekan melalui komponen inference-gateway pada port 8081 diarahkan ke beban kerja layanan inferensi yang ditentukan oleh InferencePool menggunakan algoritma penyeimbangan beban canggih yang dirancang untuk layanan inferensi.
Prasyarat
Sebuah kluster ACK dikelola dengan kumpulan node GPU dibuat. Anda dapat menginstal komponen ACK Virtual Node di kluster ACK dikelola untuk menggunakan daya komputasi ACS dalam kluster ACK Pro.
Prosedur
Langkah 1: Terapkan layanan inferensi contoh
Buat file bernama vllm-service.yaml dan salin konten berikut ke file tersebut:
CatatanUntuk gambar yang digunakan dalam topik ini, kami merekomendasikan Anda menggunakan kartu A10 untuk kluster ACK dan kartu GN8IS untuk daya komputasi GPU Layanan Komputasi Kontainer Alibaba Cloud (ACS).
Karena ukuran gambar LLM yang besar, kami merekomendasikan Anda mentransfernya ke Container Registry terlebih dahulu dan menariknya menggunakan alamat jaringan internal. Kecepatan menarik dari jaringan publik bergantung pada konfigurasi bandwidth alamat IP elastis (EIP) kluster, yang dapat mengakibatkan waktu tunggu lebih lama.
Terapkan layanan inferensi contoh.
kubectl apply -f vllm-service.yaml
Langkah 2: Instal komponen Gateway dengan Ekstensi Inferensi
Instal komponen ACK Gateway dengan Ekstensi Inferensi dan pilih Enable Gateway API Inference Extension.
Langkah 3: Terapkan perutean inferensi
Langkah ini melibatkan pembuatan sumber daya InferencePool dan InferenceModel.
Buat file bernama inference-pool.yaml.
apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferencePool metadata: name: vllm-qwen-pool spec: targetPortNumber: 8000 selector: app: qwen extensionRef: name: inference-gateway-ext-proc --- apiVersion: inference.networking.x-k8s.io/v1alpha2 kind: InferenceModel metadata: name: inferencemodel-qwen spec: modelName: /model/qwen criticality: Critical poolRef: group: inference.networking.x-k8s.io kind: InferencePool name: vllm-qwen-pool targetModels: - name: /model/qwen weight: 100Terapkan perutean inferensi.
kubectl apply -f inference-gateway-llm.yaml
Langkah 4: Terapkan dan verifikasi gateway
Langkah ini membuat gateway yang mencakup port 8080 dan 8081.
Buat file bernama inference-gateway.yaml.
apiVersion: gateway.networking.k8s.io/v1 kind: GatewayClass metadata: name: qwen-inference-gateway-class spec: controllerName: gateway.envoyproxy.io/gatewayclass-controller --- apiVersion: gateway.networking.k8s.io/v1 kind: Gateway metadata: name: qwen-inference-gateway spec: gatewayClassName: qwen-inference-gateway-class listeners: - name: http protocol: HTTP port: 8080 - name: llm-gw protocol: HTTP port: 8081 --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: qwen-backend spec: parentRefs: - name: qwen-inference-gateway sectionName: llm-gw rules: - backendRefs: - group: inference.networking.x-k8s.io kind: InferencePool name: vllm-qwen-pool matches: - path: type: PathPrefix value: / --- apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: qwen-backend-no-inference spec: parentRefs: - group: gateway.networking.k8s.io kind: Gateway name: qwen-inference-gateway sectionName: http rules: - backendRefs: - group: "" kind: Service name: qwen port: 8000 weight: 1 matches: - path: type: PathPrefix value: / --- apiVersion: gateway.envoyproxy.io/v1alpha1 kind: BackendTrafficPolicy metadata: name: backend-timeout spec: timeout: http: requestTimeout: 1h targetRef: group: gateway.networking.k8s.io kind: Gateway name: qwen-inference-gatewayTerapkan gateway.
kubectl apply -f inference-gateway.yamlLangkah ini membuat namespace bernama
envoy-gateway-systemdan layanan bernamaenvoy-default-inference-gateway-645xxxxxdi kluster.Dapatkan alamat IP publik gateway.
export GATEWAY_HOST=$(kubectl get gateway/qwen-inference-gateway -o jsonpath='{.status.addresses[0].value}')Verifikasi bahwa gateway merutekan ke layanan inferensi melalui perutean HTTP standar pada port 8080.
curl -X POST ${GATEWAY_HOST}:8080/v1/chat/completions -H 'Content-Type: application/json' -d '{ "model": "/model/qwen", "max_completion_tokens": 100, "temperature": 0, "messages": [ { "role": "user", "content": "Tulis seolah-olah Anda seorang kritikus: San Francisco" } ] }'Output yang diharapkan:
{"id":"chatcmpl-aa6438e2-d65b-4211-afb8-ae8e76e7a692","object":"chat.completion","created":1747191180,"model":"/model/qwen","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":"San Francisco, sebuah kota yang telah lama menjadi mercusuar inovasi, budaya, dan keberagaman, terus memikat dunia dengan pesona dan karakter uniknya. Sebagai seorang kritikus, saya merasa diri saya baik terpesona maupun sesekali bingung oleh kepribadian multifaset kota ini.\n\nArsitektur San Francisco adalah bukti sejarah kaya dan semangat progresifnya. Kereta kabel ikonik, rumah-rumah Victoria, dan Jembatan Golden Gate bukan hanya atraksi turis tetapi simbol daya tarik abadi kota ini. Namun, ","tool_calls":[]},"logprobs":null,"finish_reason":"length","stop_reason":null}],"usage":{"prompt_tokens":39,"total_tokens":139,"completion_tokens":100,"prompt_tokens_details":null},"prompt_logprobs":null}Verifikasi bahwa gateway merutekan ke layanan inferensi melalui ekstensi layanan inferensi pada port 8081.
curl -X POST ${GATEWAY_HOST}:8081/v1/chat/completions -H 'Content-Type: application/json' -d '{ "model": "/model/qwen", "max_completion_tokens": 100, "temperature": 0, "messages": [ { "role": "user", "content": "Tulis seolah-olah Anda seorang kritikus: Los Angeles" } ] }'Output yang diharapkan:
{"id":"chatcmpl-cc4fcd0a-6a66-4684-8dc9-284d4eb77bb7","object":"chat.completion","created":1747191969,"model":"/model/qwen","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":"Los Angeles, metropolitan yang luas sering disebut sebagai \"L.A.,\" adalah sebuah kota yang sulit dideskripsikan dengan mudah. Ini adalah tempat di mana mimpi dibuat dan hancur, di mana matahari tak pernah tenggelam, dan di mana batas antara realitas dan fantasi sama kaburnya dengan polusi yang sering menggantung di lembah-lembahnya. Sebagai seorang kritikus, saya merasa diri saya baik terpesona maupun bingung oleh kota ini yang merupakan sebanyak keadaan pikiran seperti halnya tempat fisik.\n\nDi satu sisi, Los","tool_calls":[]},"logprobs":null,"finish_reason":"length","stop_reason":null}],"usage":{"prompt_tokens":39,"total_tokens":139,"completion_tokens":100,"prompt_tokens_details":null},"prompt_logprobs":null}
(Opsional) Langkah 5: Konfigurasikan metrik observabilitas layanan LLM dan dasbor
Anda harus mengaktifkan dan menggunakan Managed Service for Prometheus di kluster, yang mungkin mengakibatkan biaya tambahan.
Tambahkan anotasi pengumpulan metrik Prometheus ke pod layanan vLLM untuk mengumpulkan metrik menggunakan mekanisme penemuan layanan default dari instance Prometheus. Ini memantau status internal layanan vLLM.
... annotations: prometheus.io/path: /metrics # Jalur HTTP tempat Anda ingin mengekspos metrik. prometheus.io/port: "8000" # Port yang diekspos untuk metrik, yaitu port mendengarkan server vLLM. prometheus.io/scrape: "true" # Menentukan apakah akan mengambil metrik pod saat ini. ...Tabel berikut menampilkan beberapa metrik pemantauan yang disediakan oleh layanan vLLM:
Metrik
Deskripsi
vllm:gpu_cache_usage_perc
Persentase penggunaan cache GPU oleh vLLM. Saat vLLM dimulai, ia secara proaktif menempati sebanyak mungkin memori video GPU untuk Cache KV. Untuk server vLLM, semakin rendah utilitas, semakin banyak ruang yang dimiliki GPU untuk mengalokasikan sumber daya ke permintaan baru.
vllm:request_queue_time_seconds_sum
Waktu yang dihabiskan dalam antrian dalam keadaan menunggu. Setelah permintaan inferensi LLM tiba di server vLLM, mereka mungkin tidak diproses segera dan perlu menunggu penjadwal vLLM untuk menjadwalkan prefill dan decode.
vllm:num_requests_running
vllm:num_requests_waiting
vllm:num_requests_swapped
Jumlah permintaan yang menjalankan inferensi, menunggu, dan dipindahkan ke memori. Ini dapat digunakan untuk menilai tekanan permintaan saat ini pada layanan vLLM.
vllm:avg_generation_throughput_toks_per_s
vllm:avg_prompt_throughput_toks_per_s
Jumlah token yang dikonsumsi per detik selama tahap prefill dan dihasilkan selama tahap decode.
vllm:time_to_first_token_seconds_bucket
Tingkat latensi dari saat permintaan dikirim ke layanan vLLM hingga token pertama direspons. Metrik ini biasanya mewakili waktu yang diperlukan bagi klien untuk menerima respons pertama setelah mengeluarkan konten permintaan dan merupakan metrik penting yang memengaruhi pengalaman pengguna LLM.
Berdasarkan metrik ini, Anda dapat menetapkan aturan peringatan tertentu untuk memungkinkan pemantauan real-time dan deteksi anomali kinerja layanan LLM.
Konfigurasikan dasbor Grafana untuk pemantauan real-time layanan inferensi LLM. Anda dapat menggunakan dasbor Grafana untuk mengamati layanan inferensi LLM yang diterapkan berdasarkan vLLM:
Monitor laju permintaan dan throughput token total untuk layanan LLM.
Monitor status internal beban kerja inferensi.
Pastikan bahwa instance Prometheus, yang berfungsi sebagai sumber data untuk Grafana, telah mengumpulkan metrik pemantauan untuk vLLM. Untuk membuat dasbor yang dapat diamati untuk layanan inferensi LLM, Anda dapat mengimpor konten berikut ke Grafana:
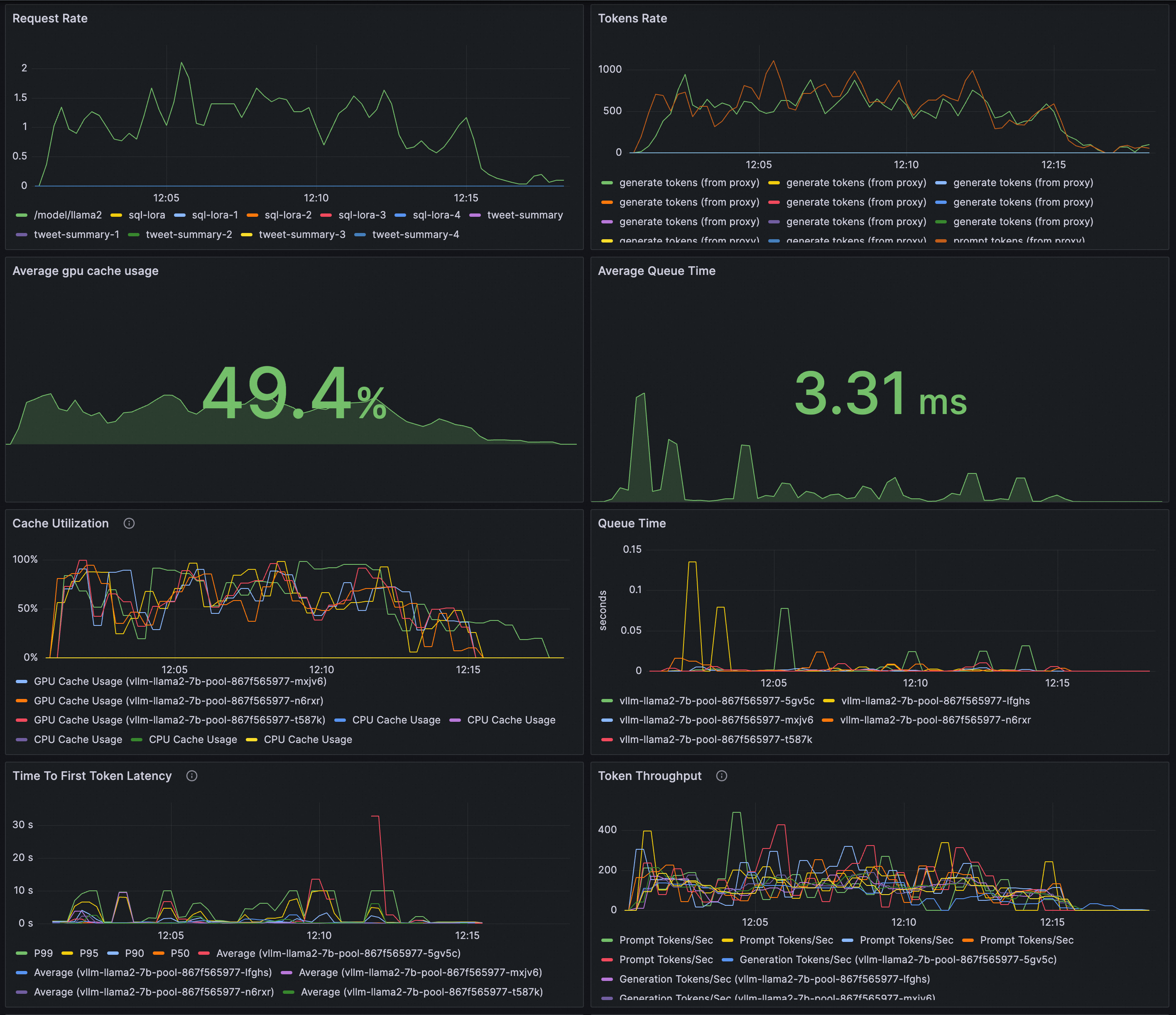
Pratinjau:
Untuk kluster ACK, gunakan benchmark vllm untuk melakukan pengujian stres pada layanan inferensi dan membandingkan kemampuan penyeimbangan beban dari perutean HTTP standar dan perutean ekstensi inferensi.
Terapkan beban kerja pengujian stres.
kubectl apply -f- <<EOF apiVersion: apps/v1 kind: Deployment metadata: labels: app: vllm-benchmark name: vllm-benchmark namespace: default spec: progressDeadlineSeconds: 600 replicas: 1 revisionHistoryLimit: 10 selector: matchLabels: app: vllm-benchmark strategy: rollingUpdate: maxSurge: 25% maxUnavailable: 25% type: RollingUpdate template: metadata: creationTimestamp: null labels: app: vllm-benchmark spec: containers: - command: - sh - -c - sleep inf image: registry-cn-hangzhou.ack.aliyuncs.com/dev/llm-benchmark:random-and-qa imagePullPolicy: IfNotPresent name: vllm-benchmark resources: {} terminationMessagePath: /dev/termination-log terminationMessagePolicy: File dnsPolicy: ClusterFirst restartPolicy: Always schedulerName: default-scheduler securityContext: {} terminationGracePeriodSeconds: 30 EOFMulai pengujian stres.
Dapatkan alamat IP internal Gateway.
export GW_IP=$(kubectl get svc -n envoy-gateway-system -l gateway.envoyproxy.io/owning-gateway-namespace=default,gateway.envoyproxy.io/owning-gateway-name=qwen-inference-gateway -o jsonpath='{.items[0].spec.clusterIP}')Lakukan pengujian stres.
Perutean HTTP Standar
kubectl exec -it deploy/vllm-benchmark -- env GW_IP=${GW_IP} python3 /root/vllm/benchmarks/benchmark_serving.py \ --backend vllm \ --model /models/DeepSeek-R1-Distill-Qwen-7B \ --served-model-name /model/qwen \ --trust-remote-code \ --dataset-name random \ --random-prefix-len 10 \ --random-input-len 1550 \ --random-output-len 1800 \ --random-range-ratio 0.2 \ --num-prompts 3000 \ --max-concurrency 200 \ --host $GW_IP \ --port 8080 \ --endpoint /v1/completions \ --save-result \ 2>&1 | tee benchmark_serving.txtPerutean Layanan Inferensi
kubectl exec -it deploy/vllm-benchmark -- env GW_IP=${GW_IP} python3 /root/vllm/benchmarks/benchmark_serving.py \ --backend vllm \ --model /models/DeepSeek-R1-Distill-Qwen-7B \ --served-model-name /model/qwen \ --trust-remote-code \ --dataset-name random \ --random-prefix-len 10 \ --random-input-len 1550 \ --random-output-len 1800 \ --random-range-ratio 0.2 \ --num-prompts 3000 \ --max-concurrency 200 \ --host $GW_IP \ --port 8081 \ --endpoint /v1/completions \ --save-result \ 2>&1 | tee benchmark_serving.txt
Setelah pengujian, Anda dapat membandingkan kemampuan perutean perutean HTTP standar dan perutean ekstensi layanan inferensi melalui dasbor.
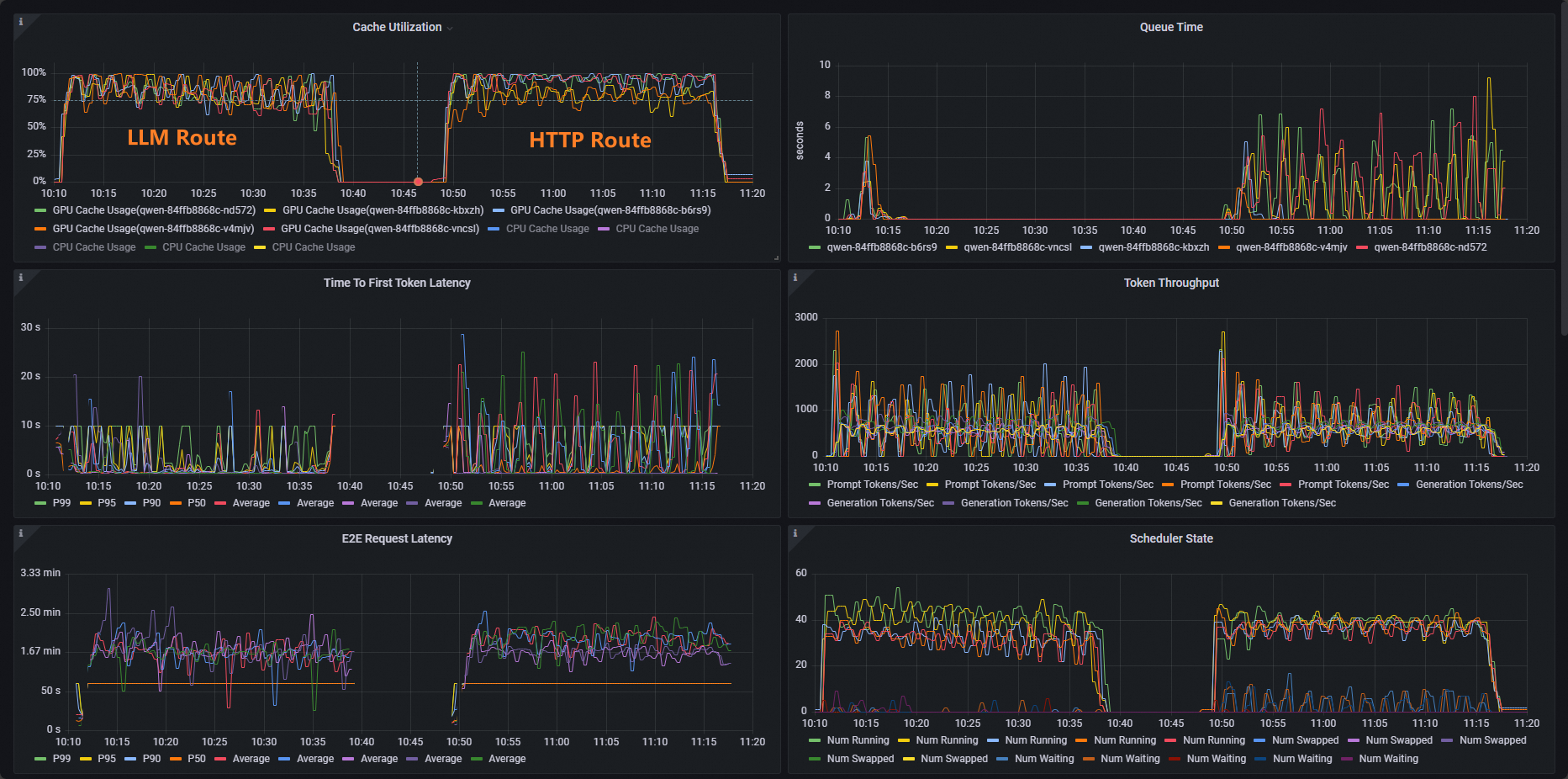
Seperti yang Anda lihat, distribusi pemanfaatan cache beban kerja menggunakan HTTP Route tidak merata, sedangkan distribusi pemanfaatan cache beban kerja menggunakan LLM Route normal.
Apa yang harus dilakukan selanjutnya
Gateway dengan Ekstensi Inferensi menyediakan berbagai kebijakan penyeimbangan beban untuk memenuhi persyaratan dalam skenario inferensi yang berbeda. Untuk mengonfigurasi kebijakan penyeimbangan beban untuk pod di InferencePool, tambahkan anotasi inference.networking.x-k8s.io/routing-strategy ke konfigurasi InferencePool.
Template YAML contoh berikut menggunakan pemilih app: vllm-app untuk memilih pod layanan inferensi dan menggunakan kebijakan penyeimbangan beban default yang bekerja berdasarkan metrik server inferensi.
apiVersion: inference.networking.x-k8s.io/v1alpha2
kind: InferencePool
metadata:
name: vllm-app-pool
annotations:
inference.networking.x-k8s.io/routing-strategy: "DEFAULT"
spec:
targetPortNumber: 8000
selector:
app: vllm-app
extensionRef:
name: inference-gateway-ext-procTabel berikut menjelaskan kebijakan penyeimbangan beban yang disediakan oleh ACK Gateway dengan Ekstensi Inferensi.
Kebijakan | Deskripsi |
DEFAULT | Kebijakan penyeimbangan beban default yang bekerja berdasarkan metrik layanan inferensi. Kebijakan ini mengevaluasi status server inferensi berdasarkan metrik multidimensi dan melakukan penyeimbangan beban berdasarkan status yang dievaluasi. Metrik termasuk panjang antrian permintaan dan pemanfaatan cache GPU. |
PREFIX_CACHE | Kebijakan penyeimbangan beban pencocokan awalan permintaan. Kebijakan ini mencoba mengirimkan permintaan dengan awalan yang sama ke pod pada server inferensi yang sama. Kebijakan ini cocok untuk skenario di mana banyak permintaan dengan awalan yang sama diterima dan server inferensi memiliki fitur auto prefix caching yang diaktifkan. Daftar berikut menjelaskan skenario tipikal:
|