Container Service for Kubernetes menyediakan ketersediaan tinggi (HA) untuk lapisan kontrol, node, workload, dan load balancing.
Panduan untuk Dokumen Ini
Dokumen ini ditujukan untuk pengembang dan administrator kluster Container Service for Kubernetes. Dokumen ini memberikan rekomendasi umum untuk merencanakan dan membangun kluster HA. Konfigurasi aktual bervariasi tergantung pada lingkungan kluster dan kebutuhan bisnis Anda. Dokumen ini mencakup konfigurasi HA baik untuk lapisan kontrol maupun bidang data kluster.
|
Arsitektur Dokumen |
Peran Pemeliharaan |
Jenis Kluster yang Berlaku |
|
Dikelola oleh ACK. |
Hanya berlaku untuk jenis kluster ACK terkelola tertentu, termasuk kluster ACK yang dikelola (Edisi Pro, Edisi Dasar), kluster ACK Serverless (Edisi Pro, Edisi Dasar), kluster ACK Edge, dan Kluster LINGJUN. Jenis kluster lain seperti kluster khusus ACK dan kluster terdaftar tidak termasuk (Anda mengelola lapisan kontrolnya sendiri), tetapi dapat menggunakan konfigurasi ini sebagai referensi. |
|
|
Konfigurasi Ketersediaan Tinggi Kelompok Node dan Node Virtual |
Dipelihara oleh Anda. |
Umum. |
Arsitektur Contoh Kluster
Kluster ACK terdiri dari dua bagian utama: lapisan kontrol serta node reguler atau virtual.
-
Lapisan kontrol mengelola kluster, termasuk penjadwalan workload dan pemeliharaan status. Ambil contoh kluster ACK yang dikelola. Kluster ACK yang dikelola menggunakan arsitektur Kubernetes-on-Kubernetes untuk menghosting komponen lapisan kontrol seperti Kube API Server, etcd, dan Kube Scheduler.
-
Node reguler atau virtual: Kluster ACK mendukung node reguler (Instance ECS) dan node virtual. Node menjalankan workload dan menyediakan sumber daya untuk kontainer.
Secara default, Kluster ACK menyediakan penerapan HA multi-zona ketersediaan (multi-AZ). Gambar berikut menunjukkan arsitektur kluster ACK yang dikelola.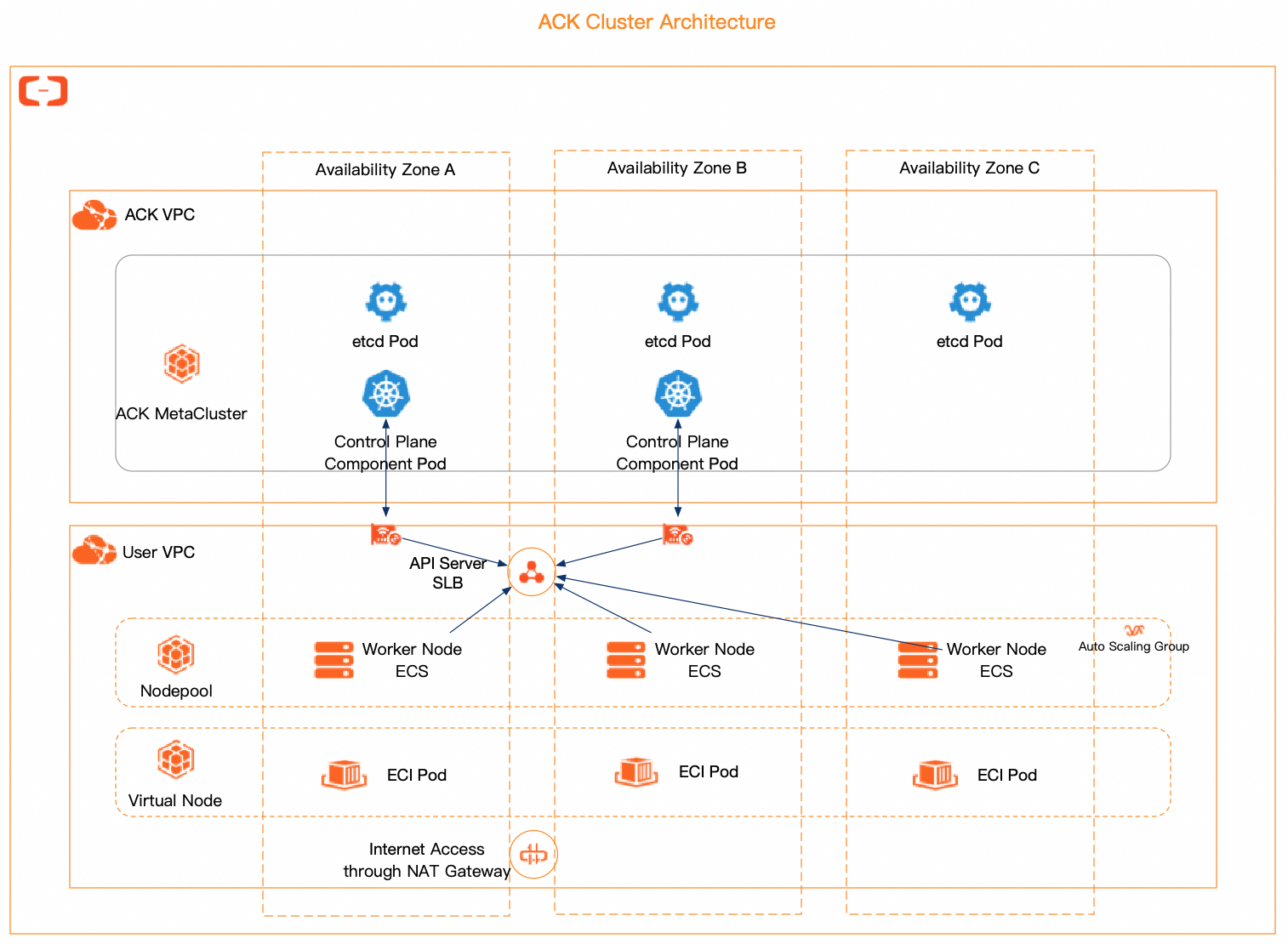
Ketersediaan Tinggi Arsitektur Lapisan Kontrol
Untuk kluster ACK terkelola—seperti kluster ACK yang dikelola (Edisi Pro dan Edisi Dasar), kluster ACK Serverless (Edisi Pro dan Edisi Dasar), kluster ACK Edge, dan Kluster LINGJUN—ACK mengelola lapisan kontrol dan komponennya seperti kube-apiserver, etcd, dan kube-scheduler.
-
Wilayah multi-zona: Semua komponen terkelola menggunakan penerapan multi-replika dan multi-AZ yang seimbang, memastikan kelangsungan layanan selama kegagalan zona tunggal atau node tunggal.
-
Wilayah zona tunggal: Semua komponen terkelola menggunakan penerapan multi-replika dan multi-node, memastikan kelangsungan layanan selama kegagalan node tunggal.
Secara khusus, etcd memiliki setidaknya tiga replika dan kube-apiserver setidaknya dua. Semua replika kube-apiserver terhubung ke VPC kluster melalui Elastic Network Interfaces (ENI). Kubelet dan Kube Proxy terhubung ke kube-apiserver melalui Classic Load Balancer (CLB) API Server atau ENI.
Semua komponen inti terkelola melakukan skalabilitas elastis berdasarkan penggunaan sumber daya seperti CPU dan memori, secara dinamis memenuhi kebutuhan API Server dengan jaminan Service-Level Agreement (SLA) yang stabil.
Selain HA multi-zona default lapisan kontrol, konfigurasikan HA bidang data: Konfigurasi Ketersediaan Tinggi untuk Kelompok Node dan Node Virtual, Konfigurasi Ketersediaan Tinggi untuk Workload, Konfigurasi Ketersediaan Tinggi untuk Load Balancing, dan Konfigurasi Komponen yang Direkomendasikan.
Konfigurasi Ketersediaan Tinggi Kelompok Node dan Node Virtual
Kluster ACK mendukung node reguler (Instance ECS) dan node virtual, yang dikelola melalui kelompok node untuk operasi seperti peningkatan, penskalaan, dan O&M. Gunakan Instance ECS untuk trafik yang stabil atau dapat diprediksi, dan node virtual untuk trafik lonjakan guna mengurangi biaya. Lihat Ikhtisar kelompok node terkelola.
Konfigurasi Ketersediaan Tinggi Kelompok Node
Kombinasikan penyesuaian otomatis node, set penyebaran, penerapan multi-zona, dan batasan penyebaran topologi Kubernetes untuk mengisolasi layanan di berbagai domain kegagalan dan mengurangi titik kegagalan tunggal.
Konfigurasikan Penyesuaian Otomatis Node
Setiap kelompok node didukung oleh grup Auto Scaling (ESS), yang mendukung penskalaan manual dan otomatis berdasarkan beban penjadwalan atau penggunaan sumber daya kluster. Lihat Penyesuaian skala otomatis dan Aktifkan penyesuaian otomatis node.
Aktifkan Set Penyebaran
Set penyebaran menyebarkan Instance ECS di berbagai server fisik untuk mencegah kegagalan bersama lokasi. Tentukan set penyebaran untuk kelompok node agar instance yang diskalakan keluar ditempatkan pada mesin fisik yang terpisah, meningkatkan pemulihan bencana dan ketersediaan. Lihat Praktik terbaik untuk set penyebaran kelompok node.
Konfigurasikan Distribusi Multi-Zona
ACK mendukung kelompok node multi-zona. Pilih beberapa vSwitch dari zona berbeda saat membuat kelompok node, dan atur Scaling Policy ke Distribution Balancing untuk mendistribusikan Instance ECS secara merata di berbagai zona. Jika terjadi ketidakseimbangan sumber daya akibat kehabisan stok, lakukan operasi rebalance. Lihat Aktifkan penyesuaian otomatis node.

Aktifkan Batasan Penyebaran Topologi
Penyesuaian otomatis node, set penyebaran, dan distribusi multi-zona, dikombinasikan dengan batasan penyebaran topologi Kubernetes, mencapai tingkat isolasi domain kegagalan yang berbeda. Node kelompok node ACK secara otomatis menerima label topologi seperti kubernetes.io/hostname, topology.kubernetes.io/zone, dan topology.kubernetes.io/region. Gunakan batasan ini untuk mengontrol distribusi pod di berbagai domain kegagalan dan meningkatkan toleransi terhadap kegagalan infrastruktur.
Kluster ACK mendukung penjadwalan sadar topologi, seperti mencoba ulang pod di berbagai domain topologi atau menjadwalkan pod ke Instance ECS dalam set penyebaran latensi rendah yang sama.
Konfigurasi Ketersediaan Tinggi Node Virtual
Node virtual ACK menjadwalkan pod pada Elastic Container Instance (ECI) tanpa mengelola server ECS yang mendasarinya. Instance ECI dibuat sesuai permintaan dengan penagihan bayar sesuai penggunaan per detik.
Penskalaan horizontal cepat atau peluncuran Job batch dapat menghabiskan inventaris instance atau alamat IP vSwitch di suatu zona, menyebabkan kegagalan pembuatan ECI. Fitur multi-zona kluster ACK Serverless meningkatkan tingkat keberhasilan pembuatan ECI.
Konfigurasikan Profil ECI untuk node virtual dan tentukan vSwitch di berbagai zona untuk penerapan multi-zona.
-
ECI mendistribusikan permintaan pembuatan pod di semua vSwitch.
-
Jika vSwitch kekurangan inventaris, ECI secara otomatis mencoba vSwitch berikutnya.
Ubah field vSwitchIds dalam ConfigMap kube-system/eci-profile. Tambahkan ID vSwitch, dipisahkan dengan koma (,). Perubahan berlaku langsung. Lihat Buat pod ECI multi-zona.
kubectl -n kube-system edit cm eci-profileapiVersion: v1
data:
kube-proxy: "true"
privatezone: "true"
quota-cpu: "192000"
quota-memory: 640Ti
quota-pods: "4000"
regionId: cn-hangzhou
resourcegroup: ""
securitygroupId: sg-xxx
vpcId: vpc-xxx
vSwitchIds: vsw-xxx,vsw-yyy,vsw-zzz
kind: ConfigMapKonfigurasi Ketersediaan Tinggi Workload
Pastikan pod tetap berjalan atau pulih dengan cepat dari kegagalan dengan mengonfigurasi batasan penyebaran topologi, anti-afinitas pod, Pod Disruption Budgets (PDB), dan pemeriksaan kesehatan dengan self-healing.
Konfigurasikan Batasan Penyebaran Topologi
Batasan penyebaran topologi mendistribusikan pod secara merata di berbagai node dan zona untuk meningkatkan ketersediaan aplikasi. Ini berlaku untuk jenis workload seperti Deployment, StatefulSet, DaemonSet, Job, dan CronJob.
Atur maxSkew.topologyKey untuk mengontrol distribusi pod di berbagai domain topologi, seperti mendistribusikan workload secara merata di berbagai zona. Berikut adalah contohnya.
apiVersion: apps/v1
kind: Deployment
metadata:
name: app-run-per-zone
spec:
replicas: 3
selector:
matchLabels:
app: app-run-per-zone
template:
metadata:
labels:
app: app-run-per-zone
spec:
containers:
- name: app-container
image: app-image
topologySpreadConstraints:
- maxSkew: 1
topologyKey: "topology.kubernetes.io/zone"
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: app-run-per-zoneKonfigurasikan Anti-Afinitas Pod
Anti-afinitas pod mencegah pod dijadwalkan ke node yang sama, meningkatkan isolasi kesalahan. Berikut adalah contohnya.
apiVersion: apps/v1
kind: Deployment
metadata:
name: app-run-per-node
spec:
replicas: 3
selector:
matchLabels:
app: app-run-per-node
template:
metadata:
labels:
app: app-run-per-node
spec:
containers:
- name: app-container
image: app-image
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- app-run-per-node
topologyKey: "kubernetes.io/hostname"Batasan penyebaran topologi juga dapat membatasi pod menjadi satu per node. Dengan topologyKey: "kubernetes.io/hostname", setiap node bertindak sebagai domain topologi.
Contoh berikut mengatur maxSkew ke 1, topologyKey ke "kubernetes.io/hostname", dan whenUnsatisfiable ke DoNotSchedule, membatasi perbedaan jumlah pod antar node maksimal satu untuk distribusi merata.
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app-container
image: my-app-image
topologySpreadConstraints:
- maxSkew: 1
topologyKey: "kubernetes.io/hostname"
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: my-appKonfigurasikan Pod Disruption Budget
Pod Disruption Budget (PDB) menentukan jumlah minimum replika yang tersedia selama pemeliharaan node atau kegagalan, mencegah terlalu banyak replika dihentikan secara bersamaan. Berikut adalah contohnya.
apiVersion: apps/v1
kind: Deployment
metadata:
name: app-with-pdb
spec:
replicas: 3
selector:
matchLabels:
app: app-with-pdb
template:
metadata:
labels:
app: app-with-pdb
spec:
containers:
- name: app-container
image: app-container-image
ports:
- containerPort: 80
---
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: pdb-for-app
spec:
minAvailable: 2
selector:
matchLabels:
app: app-with-pdb
Konfigurasikan Pemeriksaan Kesehatan Pod dan Self-Healing
Konfigurasikan probe liveness, readiness, dan startup dengan kebijakan restart untuk memantau kesehatan kontainer dan mengaktifkan self-healing. Berikut adalah contohnya.
apiVersion: v1
kind: Pod
metadata:
name: app-with-probe
spec:
containers:
- name: app-container
image: app-image
livenessProbe:
httpGet:
path: /health
port: 80
initialDelaySeconds: 10
periodSeconds: 5
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
startupProbe:
exec:
command:
- cat
- /tmp/ready
initialDelaySeconds: 20
periodSeconds: 15
restartPolicy: AlwaysKonfigurasi Ketersediaan Tinggi Load Balancing
Tingkatkan stabilitas layanan dan isolasi kesalahan dengan menentukan zona primer dan sekunder untuk instance Server Load Balancer (SLB) serta mengaktifkan petunjuk sadar topologi.
Tentukan Zona Primer dan Sekunder untuk Instance CLB
CLB diterapkan di berbagai zona di sebagian besar wilayah untuk pemulihan bencana lintas pusat data. Tentukan zona primer dan sekunder untuk instance CLB menggunakan anotasi Service agar sesuai dengan zona Instance ECS kelompok node, mengurangi penerusan data lintas zona. Lihat Wilayah dan zona yang mendukung CLB dan Tentukan zona primer dan sekunder saat membuat instance CLB.
Berikut adalah contohnya.
apiVersion: v1
kind: Service
metadata:
annotations:
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-master-zoneid: "cn-hangzhou-b"
service.beta.kubernetes.io/alibaba-cloud-loadbalancer-slave-zoneid: "cn-hangzhou-i"
name: nginx
namespace: default
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
run: nginx
type: LoadBalancerAktifkan petunjuk sadar topologi
Kubernetes 1.23 memperkenalkan routing sadar topologi (petunjuk sadar topologi) untuk mengurangi trafik lintas zona dan meningkatkan kinerja jaringan.
Aktifkan fitur ini di Service. Saat cukup banyak endpoint tersedia di zona tersebut, controller EndpointSlice memprioritaskan routing trafik ke endpoint yang lebih dekat dengan asal permintaan berdasarkan petunjuk topologi, menjaga trafik tetap dalam zona yang sama untuk mengurangi biaya. Lihat Routing Sadar Topologi.
Konfigurasi komponen tambahan yang direkomendasikan
ACK menyediakan berbagai komponen untuk memperluas fungsionalitas kluster. Lihat Ikhtisar komponen dan catatan rilis dan Kelola komponen.
Terapkan Nginx Ingress Controller dengan Benar
Distribusikan Nginx Ingress Controller di berbagai node untuk mencegah konflik sumber daya dan titik kegagalan tunggal. Gunakan node khusus untuk kinerja dan stabilitas yang lebih baik.
Hindari batasan sumber daya untuk Nginx Ingress Controller agar tidak terjadi gangguan trafik akibat OOM. Jika batasan diperlukan, atur CPU minimal 1000m dan memori minimal 2 GiB. Lihat Rekomendasi penggunaan untuk Nginx Ingress Controller.
Untuk controller ALB Ingress atau MSE Ingress, konfigurasikan beberapa zona saat pembuatan. Lihat Buat gateway cloud-native, Buat dan gunakan ALB Ingress untuk mengekspos Layanan, dan Perbandingan Nginx Ingress, ALB Ingress, dan MSE Ingress.
Terapkan CoreDNS dengan Benar
Distribusikan replika CoreDNS di berbagai zona dan node untuk menghindari kegagalan titik tunggal. CoreDNS secara default menggunakan anti-afinitas lemah per node; sumber daya yang tidak mencukupi dapat memusatkan replika pada satu node. Hapus pod untuk memicu ulang penjadwalan jika hal ini terjadi.
Pastikan node CoreDNS memiliki CPU dan memori yang cukup untuk mempertahankan QPS dan latensi DNS. Lihat Praktik terbaik DNS.
Referensi
-
Gunakan tipe Instance ECS yang lebih besar untuk node pekerja. Lihat Konfigurasi tipe Instance ECS yang direkomendasikan.
-
Untuk penerapan kluster ACK yang dikelola Edisi Pro berskala besar (biasanya lebih dari 500 node atau 10.000 pod), lihat Rekomendasi penggunaan untuk kluster berskala besar.