Kluster ACK Edge memungkinkan Anda mengelola node yang dipercepat GPU di pusat data dan edge. Anda dapat mengelola daya komputasi heterogen di berbagai wilayah dan lingkungan. Kluster ACK Edge dapat dihubungkan ke Managed Service for Prometheus, sehingga node yang dipercepat GPU di pusat data dan edge dapat dipantau seperti node di cloud.
Prinsip observabilitas node edge
Kluster ACK Edge memungkinkan Anda mengakses sumber daya IaaS (infrastructure as a service), seperti node di pusat data, vendor cloud pihak ketiga, dan perangkat IoT, melalui sirkuit Express Connect atau Internet. Node edge berkomunikasi dengan cloud menggunakan sirkuit Express Connect untuk memastikan bahwa Managed Service for Prometheus dapat mengakses node edge. Ini menjamin observabilitas berfungsi sesuai harapan. Managed Service for Prometheus menggunakan Raven untuk memantau node edge melalui Internet. Gambar berikut menunjukkan langkah-langkahnya:
Managed Service for Prometheus mengumpulkan metrik berdasarkan nama node, bukan alamat IP. Selama resolusi nama domain, CoreDNS mengonfigurasi plug-in Hosts untuk menyelesaikan nama node edge ke Layanan Raven.
Ketika Managed Service for Prometheus mengakses Layanan Raven, ia memilih node gateway dari backend Layanan tersebut untuk berkomunikasi dengan domain jaringan di edge.
Raven-agent pada node gateway membuat saluran terenkripsi dengan Raven-agent pada node gateway di pusat data lokal. Komunikasi jaringan Lapisan 3 dan Lapisan 7 didukung.
Pada node gateway domain jaringan pusat data lokal, Raven-agent mendapatkan data pemantauan dengan mengakses port pengumpulan GPU dari node target.
Memantau node edge yang dipercepat GPU
Langkah 1: Aktifkan Managed Service for Prometheus
Masuk ke Konsol ACK. Di panel navigasi kiri, klik Clusters.
Di halaman Clusters, temukan kluster yang diinginkan dan klik namanya. Di panel kiri, pilih .
Di halaman Prometheus Monitoring, ikuti petunjuk untuk menginstal komponen yang diperlukan dan periksa dasbor terkait.
Sistem secara otomatis menginstal komponen dan memeriksa dasbor. Setelah instalasi selesai, klik setiap tab untuk melihat metrik.
Langkah 2: Tambahkan node edge yang dipercepat GPU
Untuk informasi lebih lanjut tentang cara menambahkan node edge yang dipercepat GPU, lihat Tambahkan Node yang Dipercepat GPU.
Langkah 3: Sebarkan aplikasi pada node yang terhubung dengan percepatan GPU untuk memverifikasi kebenaran metrik terkait GPU
Dalam contoh ini, proyek TensorFlow Benchmark digunakan dengan kemampuan penjadwalan GPU eksklusif. Anda juga dapat menjalankan aplikasi yang berbagi sumber daya GPU pada node edge yang dipercepat GPU. Untuk informasi lebih lanjut, lihat Bekerja dengan Berbagi Multi-GPU.
Buat pekerjaan dan simpan sebagai file tensorflow.yaml.
apiVersion: batch/v1 kind: Job metadata: name: tensorflow-benchmark-exclusive spec: parallelism: 1 template: metadata: labels: app: tensorflow-benchmark-exclusive spec: containers: - name: tensorflow-benchmark image: registry.cn-beijing.aliyuncs.com/ai-samples/gpushare-sample:benchmark-tensorflow-2.2.3 command: - bash - run.sh - --num_batches=5000000 - --batch_size=8 resources: limits: nvidia.com/gpu: 1 #Ajukan permintaan untuk GPU. workingDir: /root restartPolicy: NeverSebarkan pekerjaan di kluster.
kubectl apply -f tensorflow.yaml
Langkah 4: Lihat dasbor pemantauan GPU
Masuk ke Konsol ACK. Di panel navigasi kiri, klik Clusters.
Di halaman Clusters, temukan kluster yang diinginkan dan klik namanya. Di panel kiri, pilih .
Di halaman Prometheus Monitoring, klik tab GPU Monitoring.
Klik tab GPUs - Cluster Dimension untuk melihat dasbor kluster. Untuk informasi lebih lanjut, lihat Lihat Pemantauan GPU - Dimensi Kluster.
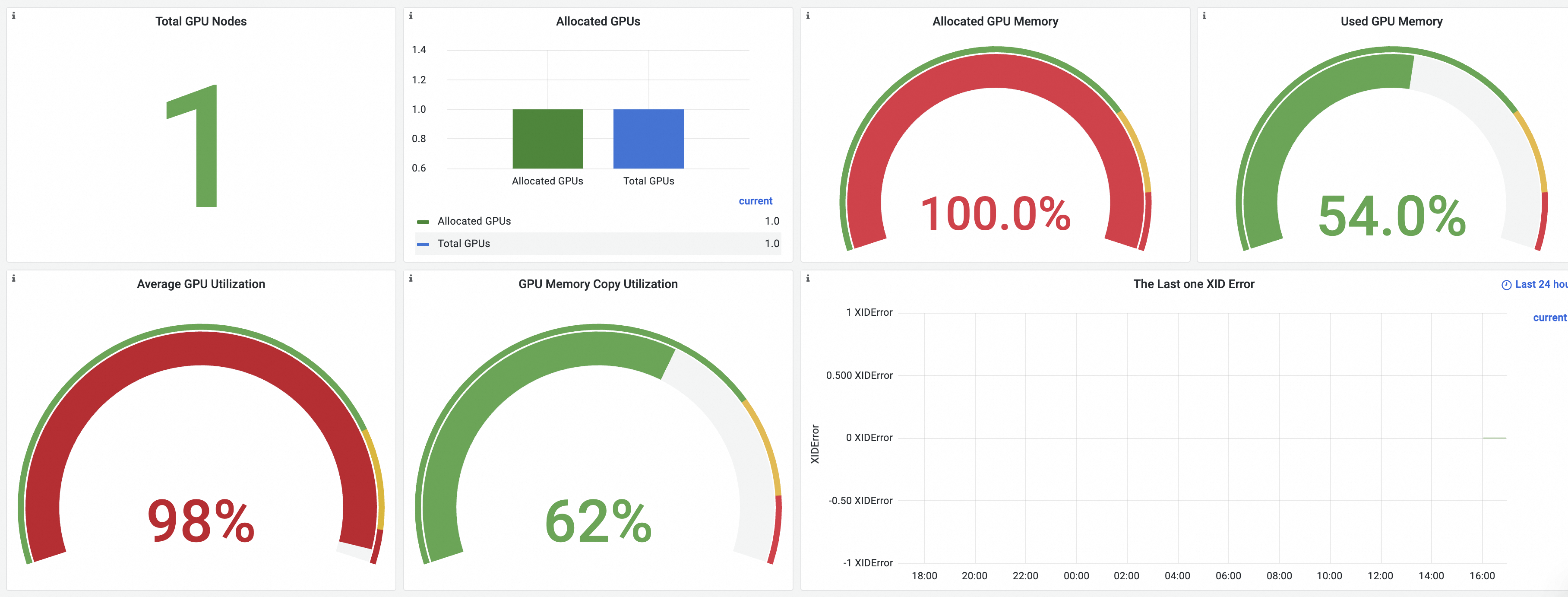
Klik tab GPU - Node untuk melihat dasbor node yang dipercepat GPU. Untuk informasi lebih lanjut tentang dasbor, lihat Lihat Pemantauan GPU - Dimensi Node.
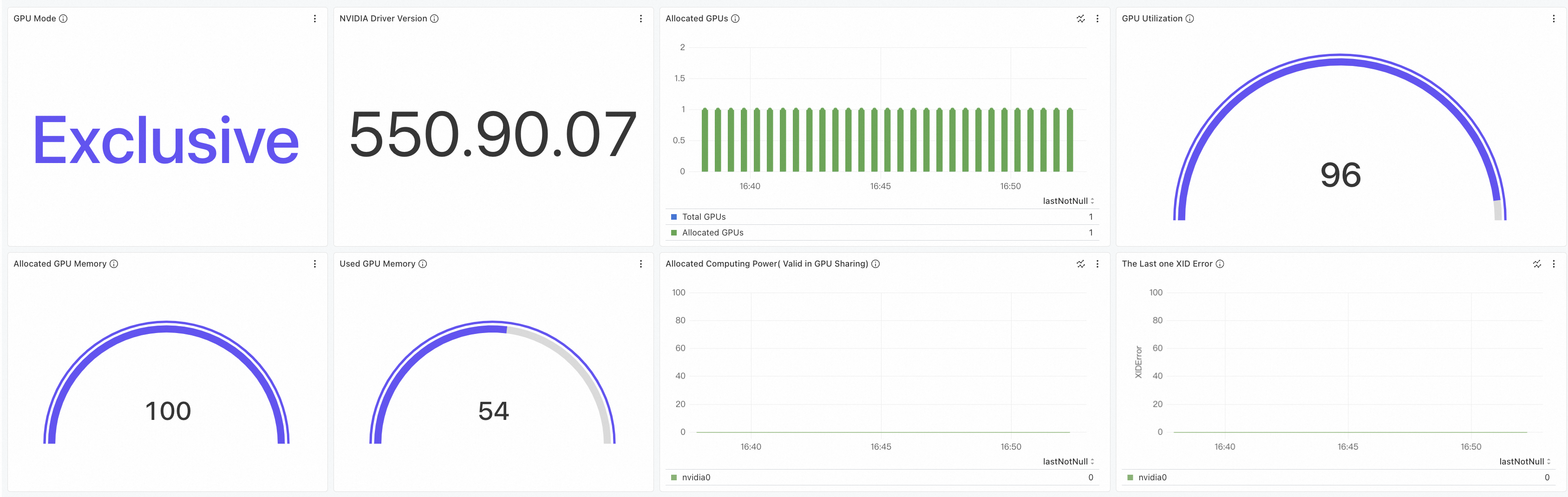
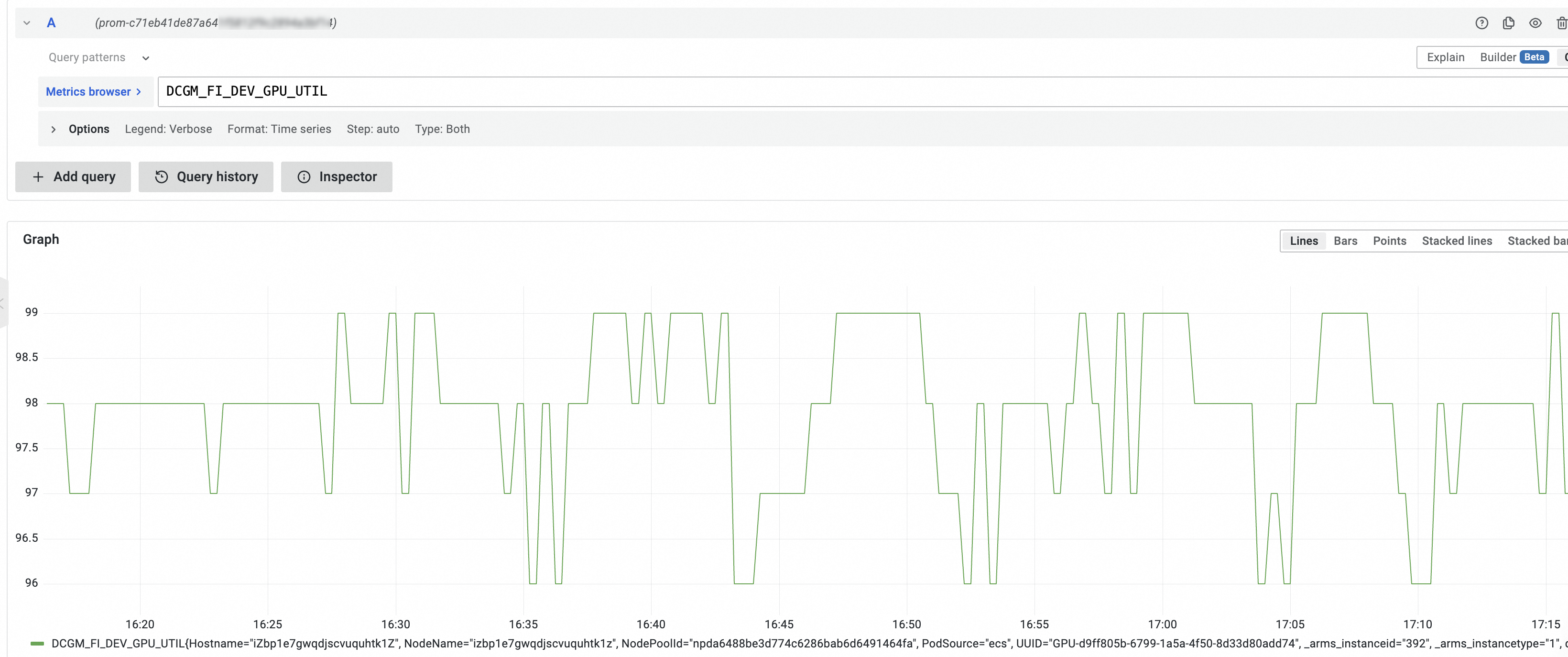
Langkah 5: Lihat metrik pemantauan node edge yang dipercepat GPU
GPU exporter yang digunakan oleh pemantauan GPU kompatibel dengan metrik yang disediakan oleh Data Center GPU Manager (DCGM) exporter. GPU exporter juga menyediakan metrik kustom untuk memenuhi persyaratan skenario tertentu. Untuk informasi lebih lanjut tentang DCGM exporter, lihat DCGM exporter.
Pemantauan GPU mencakup metrik yang didukung oleh DCGM exporter dan metrik kustom. Anda dapat melakukan operasi berikut untuk melihat metrik terkait GPU:
Biaya dikenakan untuk metrik kustom yang digunakan oleh pemantauan GPU.
Sebelum mengaktifkan fitur ini, kami sarankan Anda membaca Ikhtisar Penagihan untuk memahami aturan penagihan metrik kustom. Biaya mungkin bervariasi berdasarkan ukuran kluster dan jumlah aplikasi. Anda dapat mengikuti langkah-langkah dalam Lihat Penggunaan Sumber Daya untuk memantau dan mengelola penggunaan sumber daya.
Masuk ke Konsol ARMS.
Di panel navigasi kiri, pilih .
Pilih instance Prometheus dari daftar drop-down di bagian atas halaman.
Di bagian A, pilih metrik dan klik Jalankan kueri. Pilih mode berdasarkan kebutuhan bisnis Anda.