Pemantauan GPU menggunakan NVIDIA Data Center GPU Manager (DCGM) untuk memantau Node GPU di kluster Anda. Dokumen ini menjelaskan cara melihat hasil pemantauan untuk aplikasi yang meminta sumber daya GPU melalui tiga metode berbeda.
Prasyarat
Anda telah membuat ACK managed cluster.
Anda telah mengaktifkan GPU monitoring untuk kluster tersebut.
Anda telah menginstal komponen berbagi GPU.
Informasi latar belakang
Pemantauan GPU secara komprehensif memantau Node GPU di kluster Anda dan menyediakan dasbor pada tingkat Kluster, Node, dan Pod. Untuk detail lebih lanjut, lihat Deskripsi Dasbor.
Dasbor Pemantauan GPU Tingkat Kluster menampilkan informasi untuk seluruh kluster atau Kelompok Node tertentu, seperti pemanfaatan di seluruh kluster, penggunaan Memori GPU, dan deteksi kesalahan XID.
Dasbor Pemantauan GPU Tingkat Node menampilkan informasi spesifik node, seperti detail GPU, pemanfaatan, dan penggunaan Memori GPU untuk suatu Node tertentu.
Dasbor Pemantauan GPU Tingkat Pod menampilkan informasi spesifik Pod, seperti sumber daya GPU yang diminta oleh Pod dan pemanfaatannya.
Dokumen ini menggunakan alur kerja contoh berikut untuk menunjukkan bagaimana metode permintaan GPU yang berbeda memengaruhi hasil pemantauan.
Catatan penting
Metrik pemantauan GPU dikumpulkan setiap interval 15 detik, yang dapat menyebabkan sedikit keterlambatan data pada dasbor Grafana. Akibatnya, dasbor mungkin menunjukkan tidak ada Memori GPU yang tersedia pada suatu Node, tetapi Pod tetap berhasil dijadwalkan ke Node tersebut. Hal ini dapat terjadi jika sebuah Pod menyelesaikan tugasnya dan melepaskan sumber daya GPU dalam interval pengumpulan 15 detik (antara dua pengambilan data), sehingga penjadwal dapat menempatkan Pod yang tertunda ke Node tersebut sebelum pembaruan metrik berikutnya.
Dasbor Pemantauan hanya memantau sumber daya GPU yang diminta melalui
resources.limitsdalam sebuah Pod. Untuk informasi lebih lanjut, lihat Resource Management for Pods and Containers.Data pada Dasbor Pemantauan mungkin tidak akurat jika Anda menggunakan sumber daya GPU dengan cara berikut:
Menjalankan aplikasi GPU langsung pada suatu Node.
Menjalankan aplikasi GPU dalam kontainer yang dijalankan langsung dengan perintah
docker run.Meminta sumber daya GPU untuk suatu Pod dengan mengatur variabel lingkungan
NVIDIA_VISIBLE_DEVICES=allatauNVIDIA_VISIBLE_DEVICES=<GPU ID>secara langsung di bagianenvPod dan menjalankan program GPU.Mengonfigurasi
privileged: truedalamsecurityContextPod dan menjalankan program GPU.Menjalankan program GPU dalam Pod di mana variabel lingkungan
NVIDIA_VISIBLE_DEVICEStidak diatur, tetapi citra kontainer yang digunakan oleh Pod memiliki konfigurasi defaultNVIDIA_VISIBLE_DEVICES=all.
Memori GPU yang dialokasikan dan Memori GPU yang digunakan tidak selalu sama. Misalnya, sebuah kartu GPU memiliki total Memori GPU 16 GiB. Anda mengalokasikan 5 GiB darinya ke sebuah Pod yang perintah startup-nya adalah
sleep 1000. Dalam kasus ini, Pod berada dalam statusRunningtetapi tidak akan menggunakan GPU selama 1000 detik. Akibatnya, 5 GiB Memori GPU dialokasikan, tetapi Memori GPU yang digunakan adalah 0 GiB.
Langkah 1: Membuat kelompok node
Dasbor Pemantauan GPU menampilkan metrik untuk Pod yang meminta sumber daya GPU baik sebagai satu kartu penuh maupun jumlah tertentu dari Memori GPU, opsional dengan daya komputasi.
Contoh ini membuat tiga Kelompok Node dalam suatu kluster untuk menunjukkan penjadwalan Pod dan penggunaan sumber daya untuk model permintaan GPU yang berbeda. Untuk petunjuk terperinci tentang pembuatan Kelompok Node, lihat Membuat kelompok node. Konfigurasi untuk Kelompok Node adalah sebagai berikut:
Item konfigurasi | Deskripsi | Nilai contoh |
Node Pool Name | Nama untuk Kelompok Node pertama. | exclusive |
Nama untuk Kelompok Node kedua. | share-mem | |
Nama untuk Kelompok Node ketiga. | share-mem-core | |
Instance Type | Tipe instans untuk node. Contoh ini menggunakan proyek TensorFlow Benchmark yang memerlukan memori GPU 10 GiB, sehingga tipe instans node harus menyediakan lebih dari 10 GiB. | ecs.gn7i-c16g1.4xlarge |
Expected Node Count | Jumlah total node yang harus dipertahankan oleh Kelompok Node. | 1 |
Node Labels | Label yang ditambahkan ke Kelompok Node pertama. Ini menunjukkan bahwa sumber daya GPU diminta sebagai satu kartu penuh. | None |
Label yang ditambahkan ke Kelompok Node kedua. Ini menunjukkan bahwa sumber daya GPU diminta berdasarkan memori GPU. | ack.node.gpu.schedule=cgpu | |
Label yang ditambahkan ke Kelompok Node ketiga. Ini menunjukkan bahwa sumber daya GPU diminta berdasarkan memori GPU dan mendukung permintaan daya komputasi. | ack.node.gpu.schedule=core_mem |
Langkah 2: Men-deploy aplikasi GPU
Setelah membuat Kelompok Node, jalankan Job pengujian GPU pada Node untuk memverifikasi bahwa metrik GPU dikumpulkan dengan benar. Untuk informasi tentang label dan hubungan penjadwalan yang diperlukan untuk setiap Job, lihat Jenis node GPU dan label penjadwalan. Konfigurasi untuk ketiga Job adalah sebagai berikut:
Nama Job | Kelompok Node untuk tugas | Permintaan sumber daya GPU |
| exclusive |
Meminta 1 kartu GPU penuh. |
| share-mem |
Meminta 10 GiB memori GPU. |
| share-mem-core |
Meminta 10 GiB memori GPU dan 30% daya komputasi dari satu kartu GPU. |
Buat file manifest Job.
Buat file bernama
tensorflow-benchmark-exclusive.yamldengan konten YAML berikut.apiVersion: batch/v1 kind: Job metadata: name: tensorflow-benchmark-exclusive spec: parallelism: 1 template: metadata: labels: app: tensorflow-benchmark-exclusive spec: containers: - name: tensorflow-benchmark image: registry.cn-beijing.aliyuncs.com/ai-samples/gpushare-sample:benchmark-tensorflow-2.2.3 command: - bash - run.sh - --num_batches=5000000 - --batch_size=8 resources: limits: nvidia.com/gpu: 1 #Apply for a GPU. workingDir: /root restartPolicy: NeverBuat file bernama
tensorflow-benchmark-share-mem.yamldengan konten YAML berikut.apiVersion: batch/v1 kind: Job metadata: name: tensorflow-benchmark-share-mem spec: parallelism: 1 template: metadata: labels: app: tensorflow-benchmark-share-mem spec: containers: - name: tensorflow-benchmark image: registry.cn-beijing.aliyuncs.com/ai-samples/gpushare-sample:benchmark-tensorflow-2.2.3 command: - bash - run.sh - --num_batches=5000000 - --batch_size=8 resources: limits: aliyun.com/gpu-mem: 10 #Apply for 10 GiB of GPU memory. workingDir: /root restartPolicy: NeverBuat file bernama
tensorflow-benchmark-share-mem-core.yamldengan konten YAML berikut.apiVersion: batch/v1 kind: Job metadata: name: tensorflow-benchmark-share-mem-core spec: parallelism: 1 template: metadata: labels: app: tensorflow-benchmark-share-mem-core spec: containers: - name: tensorflow-benchmark image: registry.cn-beijing.aliyuncs.com/ai-samples/gpushare-sample:benchmark-tensorflow-2.2.3 command: - bash - run.sh - --num_batches=5000000 - --batch_size=8 resources: limits: aliyun.com/gpu-mem: 10 #Apply for 10 GiB of GPU memory. aliyun.com/gpu-core.percentage: 30 # Apply for 30% of the computing power of a GPU. workingDir: /root restartPolicy: Never
Jalankan perintah berikut untuk men-deploy Job.
kubectl apply -f tensorflow-benchmark-exclusive.yaml kubectl apply -f tensorflow-benchmark-share-mem.yaml kubectl apply -f tensorflow-benchmark-share-mem-core.yamlJalankan perintah berikut untuk memeriksa status Pod.
kubectl get podOutput yang diharapkan:
NAME READY STATUS RESTARTS AGE tensorflow-benchmark-exclusive-7dff2 1/1 Running 0 3m13s tensorflow-benchmark-share-mem-core-k24gz 1/1 Running 0 4m22s tensorflow-benchmark-share-mem-shmpj 1/1 Running 0 3m46sOutput menunjukkan bahwa semua Pod berada dalam status
Running, yang berarti Job berhasil dideploy.
Langkah 3: Melihat dasbor pemantauan GPU
View the GPUs - Cluster Dimension dashboard
Masuk ke Konsol ACK. Di panel navigasi kiri, klik Clusters.
Pada halaman Clusters, temukan kluster yang Anda inginkan dan klik namanya. Di panel kiri, pilih .
Pada halaman Prometheus monitoring, klik tab GPU Monitoring, lalu klik tab GPUs - Cluster Dimension. Informasi pada Dasbor Pemantauan tingkat kluster dijelaskan di bawah ini. Untuk informasi lebih lanjut, lihat Dasbor pemantauan dimensi kluster.
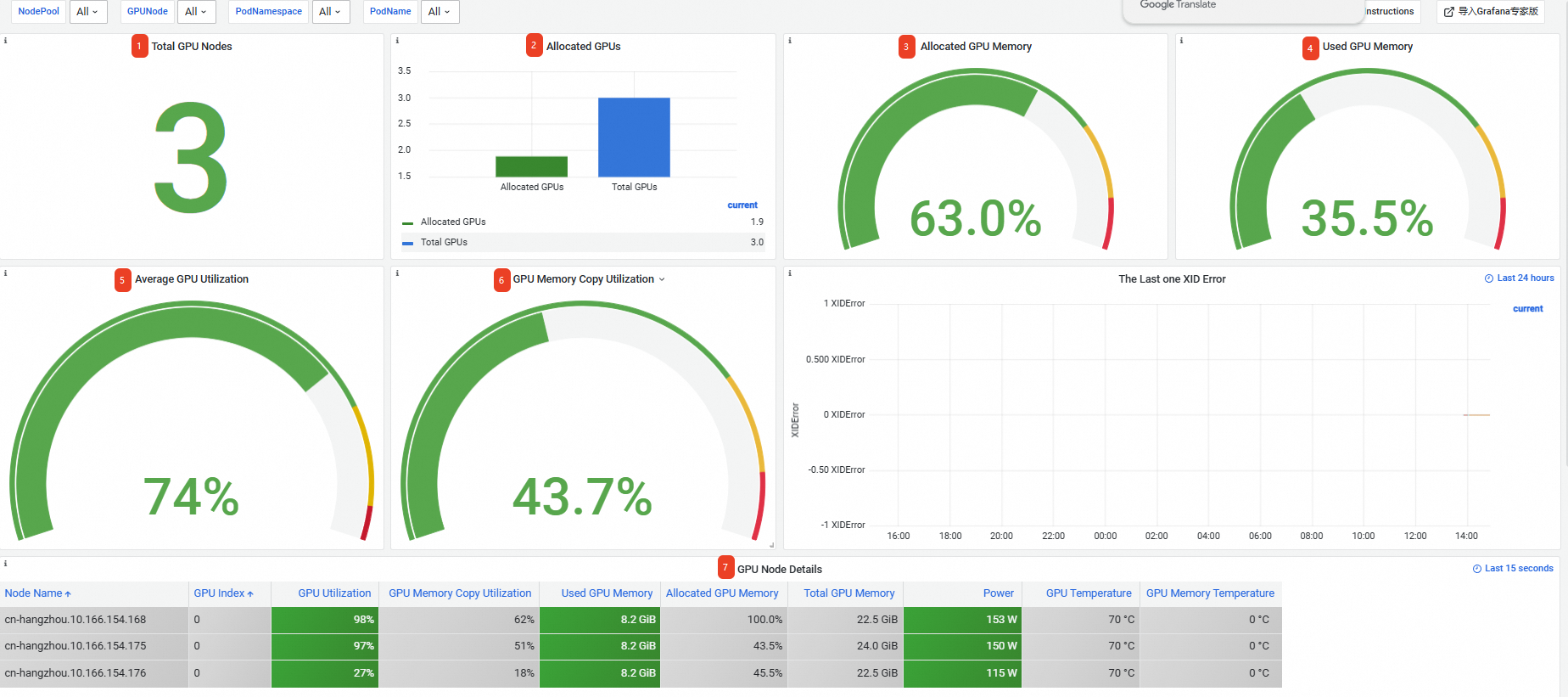
No.
Nama panel
Deskripsi
1
Total GPU Nodes
Kluster memiliki 3 node GPU.
2
Allocated GPUs
1,9 dari total 3 GPU dialokasikan.
CatatanJika sebuah Pod meminta GPU sebagai satu kartu penuh, alokasi untuk satu kartu adalah 1. Untuk penjadwalan GPU bersama, alokasi adalah rasio memori GPU yang dialokasikan terhadap total memori GPU untuk kartu tersebut.
3
Allocated GPU Memory
63,0% dari total memori GPU dialokasikan.
4
Used GPU Memory
35,5% dari total memori GPU digunakan.
5
Average GPU Utilization
Laju pemanfaatan rata-rata di seluruh kartu adalah 74%.
6
GPU Memory Copy Utilization
Laju pemanfaatan salinan memori rata-rata di seluruh kartu adalah 43,7%.
7
GPU Node Details
Informasi tentang Node GPU di kluster, termasuk nama node, indeks kartu GPU, pemanfaatan GPU, dan pemanfaatan pengontrol memori.
View the GPUs - Nodes dashboard
Pada halaman Prometheus monitoring, klik tab GPU Monitoring, lalu klik tab GPUs - Nodes. Pilih Node target dari daftar dropdown GPUNode. Contoh ini menggunakan cn-hangzhou.10.166.154.xxx. Informasi pada Dasbor Pemantauan tingkat node dijelaskan di bawah ini:
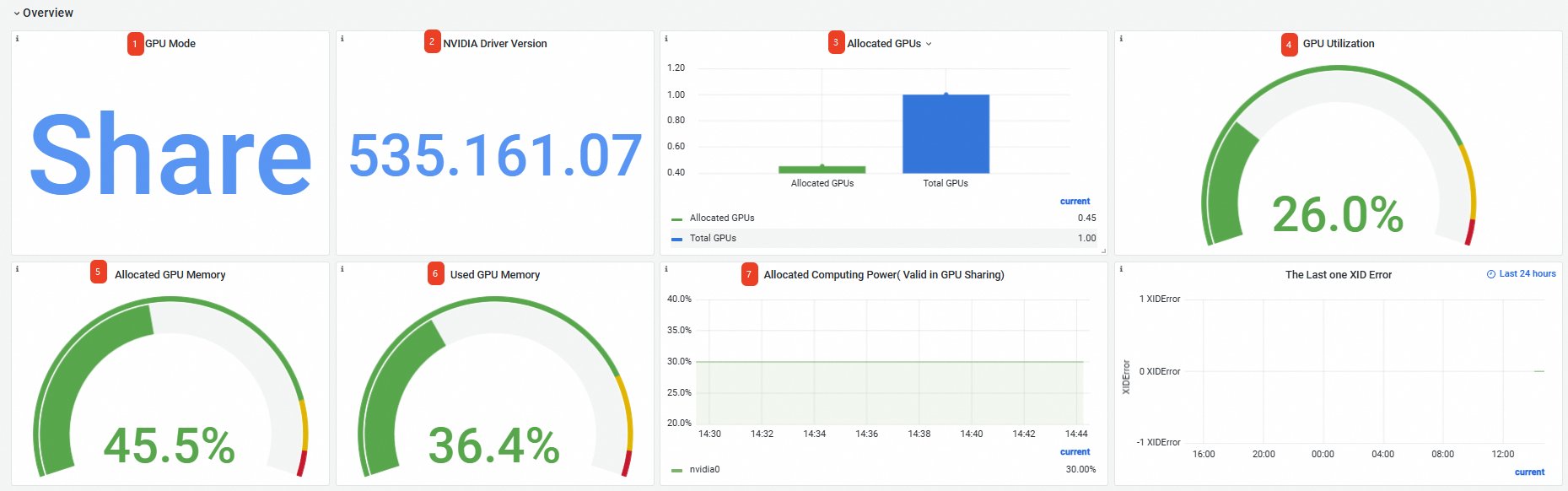


Grup panel | No. | Nama panel | Deskripsi |
Ikhtisar | 1 | GPU Mode | Mode GPU adalah mode bersama, di mana Pod meminta sumber daya GPU berdasarkan memori GPU dan daya komputasi. |
2 | NVIDIA Driver Version | Versi driver GPU yang terinstal adalah 535.161.07. | |
3 | Allocated GPUs | Jumlah total GPU adalah 1, dan jumlah GPU yang dialokasikan adalah 0,45. | |
4 | GPU Utilization | Laju pemanfaatan GPU rata-rata adalah 26%. | |
5 | Allocated GPU Memory | Memori GPU yang dialokasikan adalah 45,5% dari total memori GPU. | |
6 | Used GPU Memory | Memori GPU yang saat ini digunakan adalah 36,4% dari total memori GPU. | |
7 | Allocated Computing Power | 30% daya komputasi kartu GPU 0 dialokasikan. Catatan Panel Allocated Computing Power hanya menampilkan data jika Anda mengaktifkan alokasi daya komputasi pada Node tersebut. Oleh karena itu, di antara tiga node dalam contoh ini, hanya Node dengan label | |
Pemanfaatan | 8 | GPU Utilization | Untuk kartu GPU 0, pemanfaatan minimum adalah 0%, maksimum 33%, dan rata-rata 12%. |
9 | Memory Copy Utilization | Untuk kartu GPU 0, pemanfaatan salinan memori minimum adalah 0%, maksimum 22%, dan rata-rata 8%. | |
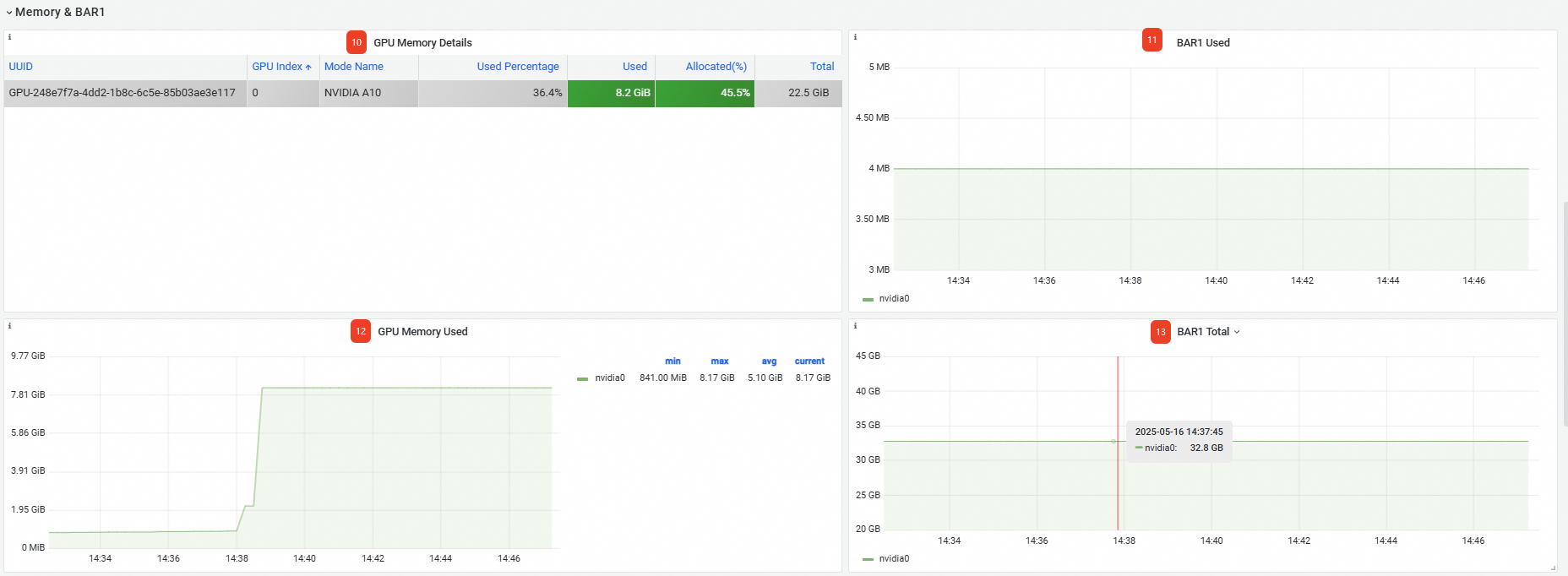
Memori&BAR1 | 10 | GPU Memory Details | Detail tentang memori GPU, termasuk UUID kartu GPU, nomor indeks, dan model. |
11 | BAR1 Used | Memori BAR1 yang digunakan adalah 4 MB. | |
12 | Memory Used | Memori GPU yang digunakan pada kartu adalah 8,17 GB. | |
13 | BAR1 Total | Total memori BAR1: 32,8 GB. | |
GPU Process | 14 | GPU Process Details | Detail tentang setiap proses GPU, termasuk namespace dan nama Pod-nya. |
Anda juga dapat melihat metrik lanjutan di bagian bawah halaman. Untuk detailnya, lihat Dasbor pemantauan tingkat node.

View the GPUs - Application Pod Dimension dashboard
Pada halaman Prometheus monitoring, klik tab GPU Monitoring, lalu klik tab GPUs - Application Pod Dimension. Informasi pada Dasbor Pemantauan tingkat Pod dijelaskan di bawah ini:
No. | Nama panel | Deskripsi |
1 | GPU Pod Details | Informasi tentang Pod di kluster yang telah meminta sumber daya GPU, termasuk namespace Pod, nama, nama Node, dan memori GPU yang digunakan. Catatan
|
Anda juga dapat melihat metrik lanjutan di bagian bawah halaman. Untuk detailnya, lihat GPUs - Application Pod Dimension.
