A tunnel client is an automatic data consumption framework of Tunnel Service. Before using Tunnel Service, you must know the following features of tunnel clients: automatic data processing, automatic load balancing, excellent horizontal scaling, automatic resource cleanup, and automatic fault tolerance.
Background information
Tunnel clients support the following features for processing full and incremental data: load balancing, fault recovery, checkpoints, and partition information synchronization used to ensure the sequence of consuming information. Tunnel clients allow you to focus on the processing logic of each record.
For the detailed sample code of Tunnel clients, visit Github.
Automatic data processing
Tunnel clients regularly check heartbeats to detect active channels, update status of Channel and ChannelConnect, and initialize, run, and terminate data processing tasks.
Initialize the resources of tunnel clients.
Change the state of the tunnel client from Ready to Started.
Set HeartbeatTimeout and ClientTag in TunnelWorkerConfig to run the ConnectTunnel task and connect Tunnel Service to obtain the ClientId of the current tunnel client.
Initialize ChannelDialer to create a ChannelConnect task.
Each ChannelConnect task corresponds to a Channel. ChannelConnect tasks record data consumption checkpoints.
Set the Callback parameter for processing data and the CheckpointInterval parameter for specifying the interval of outputting checkpoints in Tunnel Service. In this way, you can create a data processor that automatically outputs checkpoints.
Initialize TunnelStateMachine to automatically update the status of the Channel.
Regularly check heartbeat messages.
You can set the heartbeatIntervalInSec parameter in TunnelWorkerConfig to set the interval for checking the heartbeat.
Send a heartbeat request to obtain the list of latest available channels from Tunnel Service. The list includes the ChannelId, channel versions, and channel status.
Merge the list of channels obtained from Tunnel Service with the local list of channels, and then create and update ChannelConnect tasks. Follow these rules:
Merge: overwrite the earlier version in the local list with the later version for the same ChannelId from Tunnel Service, and insert the new channels from Tunnel Service into the local list.
Create a ChannelConnect task: create a ChannelConnect task in the WAIT state for a channel that has no ChannelConnect task. If the ChannelConnect task corresponds to a channel in the OPEN state, run the ReadRecords&&ProcessRecords task that cyclically processes data for this ChannelConnect task. For more information, see the ProcessDataPipeline class in source code.
Update an existing ChannelConnect task: after you merge the lists of channels, if a channel corresponds to a ChannelConnect task, update the state of ChannelConnect based on the state of the channel with the same ChannelId. For example, if channels are in the CLOSE state, set the state of corresponding ChannelConnect tasks to CLOSED to terminate the corresponding pipeline tasks. For more information, see the ChannelConnect.notifyStatus method in source code.
Automatically process channel status.
Based on the number of active tunnel clients obtained in the heartbeat request, Tunnel Service allocates available partitions to different clients to balance the loads.
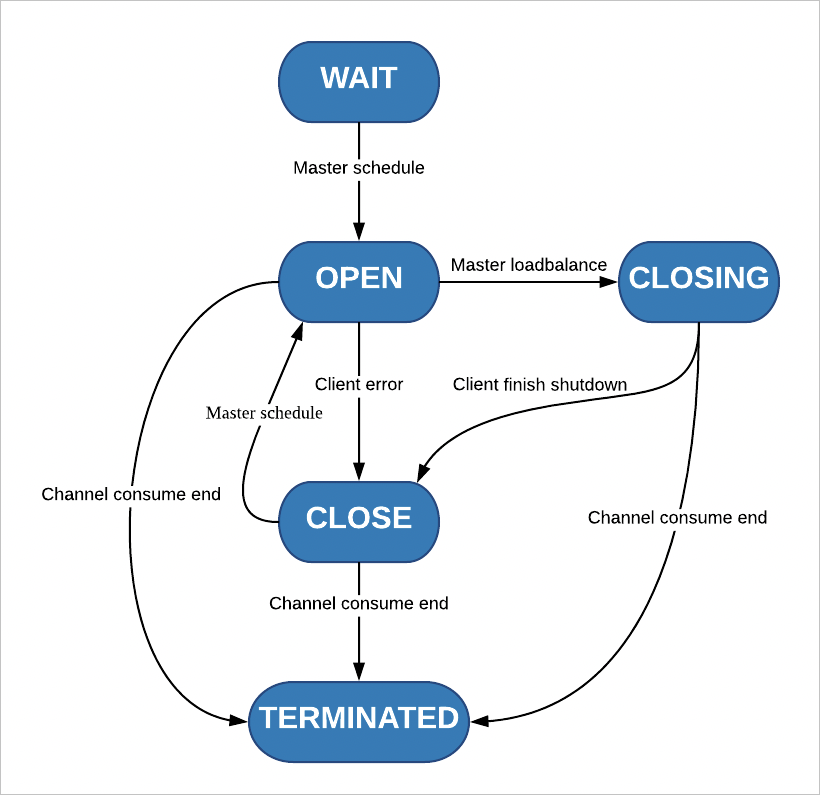
Tunnel Service automatically processes channel status as described in the following figure, and drives channel consumption and load balancing.
Tunnel Service and tunnel clients change their status based on heartbeats and channel version updates.
Each channel is initially in the WAIT state.
The channel for incremental data changes to the OPEN state only when the channel consumption on the parent partition is terminated.
Tunnel Service allocates the partition in the OPEN state to each tunnel client.
During load balancing, Tunnel Service and tunnel clients use a scheduling protocol for changing a channel state from OPEN, CLOSING to CLOSED. After consuming a BaseData channel or a Stream channel, tunnel clients report the channel as terminated.
Automatic load balancing and excellent horizontal scaling
Multiple Tunnel clients can consume data by using the same Tunnel or TunnelId. When the tunnel clients run the heartbeat task, Tunnel Service automatically redistributes channels and tries to allocate active channels to each tunnel client to achieve load balancing.
You can add tunnel clients to scale out data consumption capabilities. Tunnel clients can run on one or more instances.
Automatic resource cleanup and fault tolerance
Resource cleanup: If tunnel clients do not shut down normally, such as exceptional exit or manual termination, the system recycles resources automatically. For example, the system can release the thread pool, call the shutdown method that you have registered for the corresponding channel, and terminate the connection to Tunnel Service.
Fault tolerance: When non-parametric errors, such as heartbeat timeout, occur on a tunnel client, the system automatically renews connections to continue stable data consumption.