This topic describes the system architecture, data model, embedding and retrieval strategies, Subspace multi-tenancy design, and suitability assessment for the Knowledge Storage (RAG) Service. This information helps technical decision-makers evaluate whether the service is suitable for their business scenarios.
System architecture
The Knowledge Storage (RAG) Service uses a fully managed Serverless architecture. You interact with the service through an API, and the platform automatically manages the underlying resources. The data flow is as follows:
Call the
AddDocumentsAPI and specify an OSS file path, or upload local files using an SDK.The system reads files from OSS and automatically performs document parsing and intelligent chunking.
For each chunk, the system calls an embedding model to generate a vector and writes it to the chunk table in Tablestore.
The system automatically builds a vector index and a full-text index.
When you call the Retrieve API, the system performs hybrid retrieval and returns the relevant chunk results.
All data, including original documents, parsed results, and vector data, is stored in the OSS and Tablestore services within your account. The service itself does not retain any of your data. Storage and compute are decoupled and billed separately.
Data model
The data in a knowledge base is organized into four entity layers:
Entity | Description |
knowledge base | A knowledge base. Each knowledge base corresponds to a document table, a chunk table, and an index table. A single knowledge base can support up to 100 million documents. |
document | A document record. It is associated with an OSS file and stores the document's status and metadata. |
chunk | A document chunk. It stores vector data and the original content, and is the smallest unit for retrieval. |
index | An index table. It contains the vector and full-text indexes that are built from chunks to enable fast retrieval. |
The system automatically creates the corresponding data tables in Tablestore:
document table:
{knowledge_base_name}_{knowledge_base_id}chunk table:
{knowledge_base_name}_{knowledge_base_id}_chunkindex table:
{knowledge_base_name}_{knowledge_base_id}_index
Data sources
The data source for a knowledge base is Alibaba Cloud Object Storage Service (OSS). Regardless of the upload method, the original document data is stored in your own OSS bucket.
The knowledge base needs read and write permissions for the OSS bucket to read original documents for parsing and chunking, and to write intermediate results back to OSS.
You can import documents into a knowledge base in the following three ways:
Upload local files: Specify a local file or directory. The SDK automatically uploads the content to OSS and then adds it to the knowledge base. If you specify a directory, the SDK recursively processes all files within it.
Add OSS files: If the files are already in OSS, you can directly specify their OSS paths to add them to the knowledge base, skipping the upload step.
Bulk import from an OSS directory: Specify an OSS directory path. The system automatically and recursively scans all files in the directory. You can filter files by filename patterns by using
inclusionFiltersandexclusionFilters.
For more information about each method, see Document Management.
Embedding configuration
The embedding configuration determines how document chunks are vectorized. You specify this configuration when creating a knowledge base.
Parameter | Description |
| The model provider. Valid values are |
| The model name. Model Studio supports |
| The vector dimension. For example, |
| Required only in |
| Required only in |
If you do not provide the embeddingConfiguration parameter, the system defaults to using the Model Studio text-embedding-v4 model (1024 dimensions), which is suitable for most scenarios.
The embedding configuration cannot be changed after you create the knowledge base. To change the model or dimension, you must delete and recreate the knowledge base. Carefully evaluate your model choice before creating the knowledge base.
Recommendations:
For general-purpose Chinese and English scenarios, we recommend
text-embedding-v4(1024 dimensions), which provides a good balance between semantic understanding and performance.If you have an existing in-house or third-party embedding service, use the
custommode to integrate it and maintain a consistent technology stack.Higher dimensions provide richer semantic representation but also increase storage and compute costs. A dimension of 1024 is the recommended choice for most scenarios.
Retrieval strategy
When you call the Retrieve API, the retrieval configuration (retrievalConfiguration) follows this order of precedence:
Precedence | Source | Description |
1 (Highest) | Parameters in the Retrieve API call | The configuration passed in the current request. It applies only to this single call. |
2 | Knowledge base-level configuration | The configuration set when you created the knowledge base. You can modify it by using the UpdateKnowledgeBase API. |
3 (Lowest) | System default | Hybrid retrieval of vector and full-text retrieval results, with scores merged using the WEIGHT method (vector 0.7 : full-text 0.3). |
Retrieval types
Type | Description | Use cases |
| Vector retrieval, based on semantic similarity. | Use natural language queries where semantic understanding matters. |
| Full-text retrieval, based on keyword matching. | Input precise keywords, proper nouns, or identifiers. |
We recommend enabling both retrieval types and merging the results using a rerank mechanism.
Rerank strategies
Type | Description | Use cases |
RRF | Merges results by using Reciprocal Rank Fusion, which does not require additional model calls. | General-purpose scenarios where low latency is important. |
WEIGHT | Merges scores from vector retrieval and full-text retrieval by using a weighted ratio. | Scenarios that require fine-grained control over the contribution of each retrieval method. |
MODEL | Calls a rerank model to reorder the candidate results. | Scenarios that require high-quality ranking and can tolerate additional latency. |
For more information about how to configure and tune retrieval strategies, see Retrieval and Ranking.
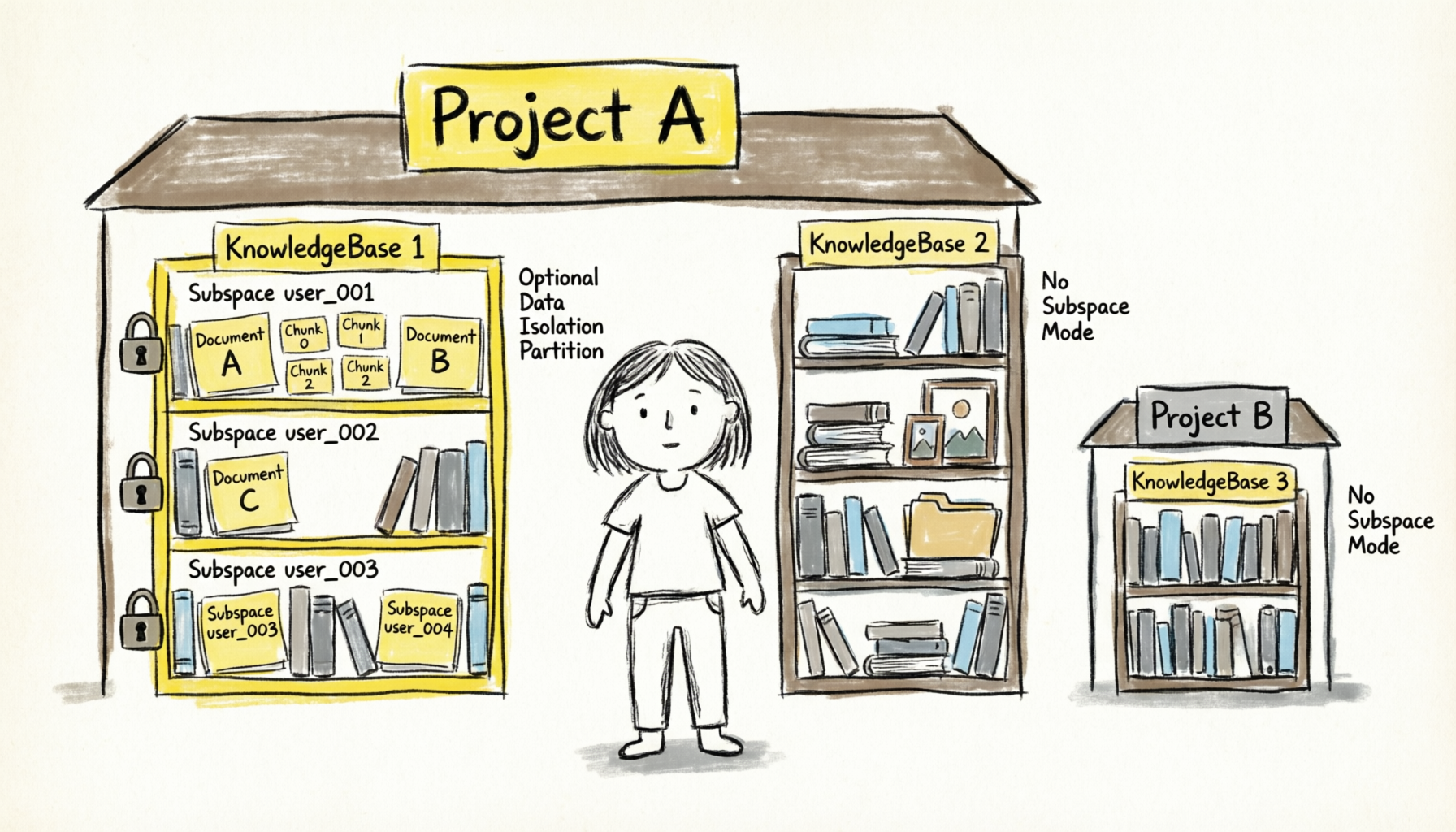
Subspace multi-tenancy
A Subspace is a data partition within a knowledge base that isolates data for different users, departments, or tenants. To enable this feature, set "subspace": true when you create the knowledge base.
Core rules:
After you enable Subspace, all document operations (add, query, delete, and list) and retrieval requests must specify the
subspacefield. Otherwise, the API returns an error.The Retrieve API supports querying multiple Subspaces simultaneously by passing a list of them (up to 32).
The maximum length for a Subspace name is 128 characters.
The Subspace setting cannot be changed after you create the knowledge base.
For example, in an enterprise environment, each employee in a department might have their own set of documents. A department administrator can create a knowledge base with Subspace enabled and assign a unique Subspace to each employee, such as employee_zhangsan and employee_lisi. This ensures that each employee's documents are isolated and not visible to others, while the administrator manages the knowledge base configuration centrally. To search across documents from multiple employees, the administrator can pass a list of Subspaces in the Retrieve request.
Subspace vs. multiple knowledge bases
Dimension | Subspace | Multiple knowledge bases |
Isolation granularity | Logical partitions within a single knowledge base | Completely independent knowledge bases |
Embedding configuration | Shares the same configuration | Each knowledge base has its own configuration |
Retrieval scope | Can perform federated retrieval across Subspaces | Retrieval is limited to a single knowledge base |
Management cost | Low (manage all tenants in one knowledge base) | High (manage multiple knowledge bases) |
Use cases | Multi-tenant isolation for homogeneous data | Different business domains or embedding requirements |
Suitability assessment
Recommended use cases:
Building Retrieval-Augmented Generation (RAG) capabilities for Large Language Model (LLM) applications.
Implementing hybrid retrieval that combines vector retrieval and full-text retrieval.
Requiring multi-tenancy data isolation.
Managing document collections that scale from hundreds to tens of billions of items.
Having strict data security requirements, where data must not leave your account.
Preferring a pay-as-you-go, zero-ops model.
Scenarios requiring evaluation:
Scenarios with extremely high requirements for real-time document indexing. Documents are indexed asynchronously, which introduces a delay between upload and search availability.
Scenarios that require custom chunking strategies. The service currently uses automatic chunking.
Not recommended for:
Querying purely structured data. We recommend using the Tablestore wide-column model or a relational database instead.
Indexing real-time streaming data. We recommend using Tablestore Search Index directly for this purpose.