Log processing covers real-time computing, data warehousing, and offline computing. This topic describes how to process logs in order without data loss or repeated consumption in real-time computing scenarios, even if upstream and downstream business systems are faulty or the volume of traffic fluctuates.
In this topic, a business day of a bank is used as an example to illustrate how to process logs. The topic also describes how to use Logstore consumer groups of Simple Log Service together with Spark Streaming or Storm Spout to process logs.
Data that can be abstracted into logs
Half a century ago, captains and operators recorded logs in thick notebooks. Today, computers allow logs to be generated and consumed everywhere. For example, GPS, orders, and various devices such as servers, routers, and sensors record our lives from different perspectives. Captains used to include a timestamp to record the time of a log. Captains also recorded other content in logs, such as text, images, weather conditions, and sailing directions. After half a century, logs are generated in various scenarios. For example, logs are recorded for an order, a payment, a page visit, and a database operation.
In computer science, common logs include metrics, binary logs for relational and NoSQL databases, events, audit logs, and access logs.
In this topic, a user operation in the bank is considered a log, which contains the name, account, operation time, operation type, and transaction amount.
Examples:
2016-06-28 08:00:00 Alice deposited USD 1,000
2016-06-27 09:00:00 Bob withdrew USD 20,000Logstore data model
This section uses the Logstore data model of Simple Log Service as an example.
A log consists of a point in time and a group of key-value pairs.
A log group is a collection of logs that have the same metadata such as the IP address and data source.
The following figure shows the relationships between logs and a log group.
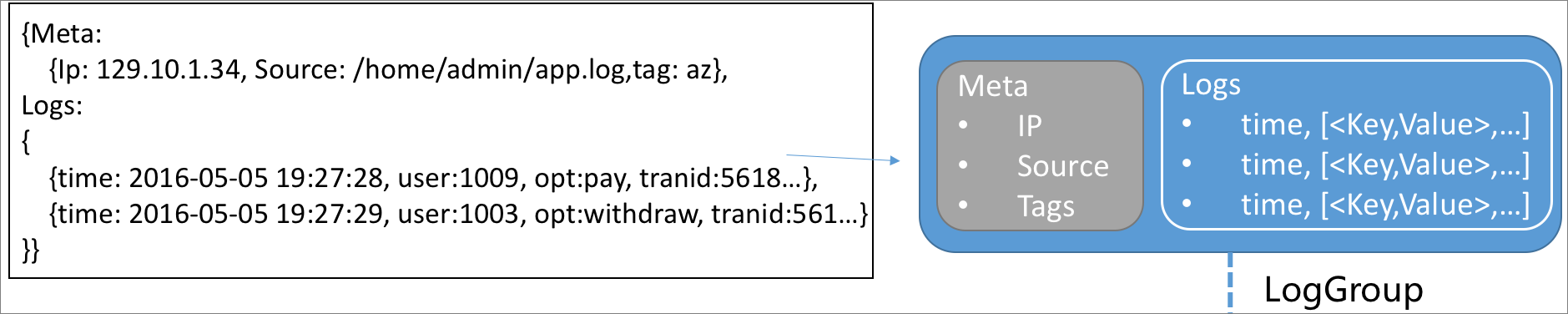
A shard is the basic read and write unit of a log group. A shard can be considered a 48-hour first in, first out (FIFO) queue. Each shard allows you to read data at a rate of 10 MB/s and write data at a rate of 5 MB/s. The logical range of a shard is specified by the BeginKey and EndKey parameters. This range allows the shard to contain a type of data that is different from other shards.
A Logstore stores log data of the same type. Each Logstore consists of one or more shards whose range is
[0000,FFFF..).A project is a container for Logstores.
The following figure shows the relationships among logs, log groups, shards, Logstores, and projects.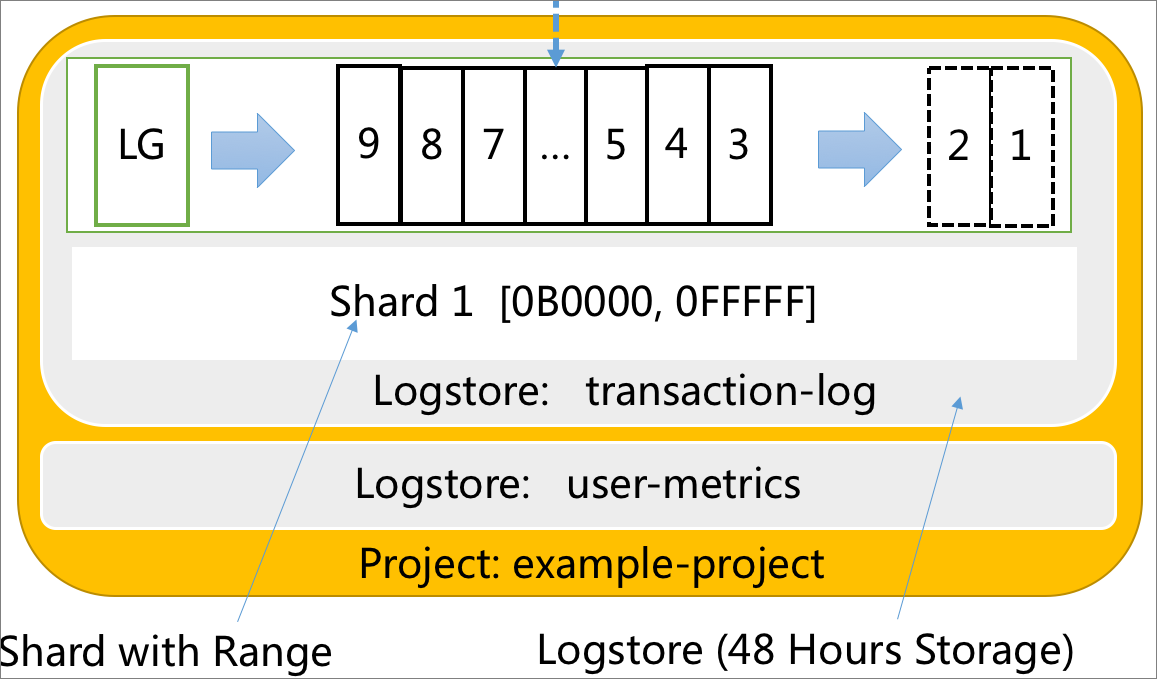
A business day in a bank
For example, one day in the nineteenth century, several users in a city went to a bank to deposit or withdraw money. Several clerks were working in the bank. At that time, transaction data could not be synchronized in real time because computers were not invented. Each clerk recorded transaction data in an account book and checked the transaction data every night. In this example, users are producers of data, money deposit and withdrawal are user operations, and clerks are consumers of data.
In a distributed log processing system, clerks are considered standalone servers that have fixed memory and computing capabilities. Users are considered requests from various data sources. The bank hall serves as a Logstore in which users can read and write data.

The following list describes the roles that are involved:
Log or log group: the user operations such as money deposit and withdrawal.
User: the producer of operations.
Clerk: the employee who processes requests in the bank.
Bank hall (Logstore): the place where requests are received and then assigned to clerks for processing.
Shard: the manner in which the bank manager sorts requests in the bank hall.
Issue 1: Ordering
Two clerks, Clerk A and Clerk B, were working in the bank. Alice deposited USD 1,000 at Counter A. Clerk A recorded the transaction amount in Account Book A. In the afternoon, Alice went to Counter B to withdraw the money. However, Clerk B could not find the deposit record of Alice in Account Book B.
In this example, money deposit and withdrawal must be strictly ordered. Requests from the same user must be processed by the same clerk to ensure that the status of user operations is consistent.
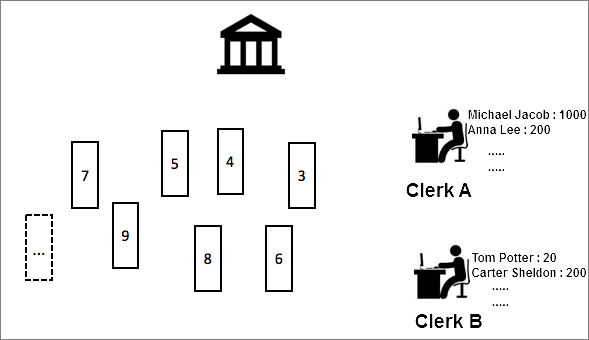
To preserve the order of requests, a shard can be created to sort requests and assign Clerk A to process the requests based on the FIFO principle. However, this method is inefficient. For example, if 1,000 users perform operations and 10 clerks are available, the process is still inefficient because only one clerk out of the 10 is assigned to process the operations. To improve efficiency, you can use the following solution:
Create 10 shards for 10 clerks and assign a clerk to process requests in each shard. To ensure that operations for the same account are ordered, use consistent hashing to map requests. For example, map requests from users to specific shards based on the bank accounts or names of the users. In this case, the formula hash(Alice) = A is used to map requests from Alice to the shard whose range contains A. A clerk, such as, Clerk A, is assigned to process requests in this shard.
If many users are named Alice, the solution can be adjusted. For example, use the hash function to map requests from users to shards based on the account IDs or zip codes of the users. Then, requests can be evenly distributed to each shard.
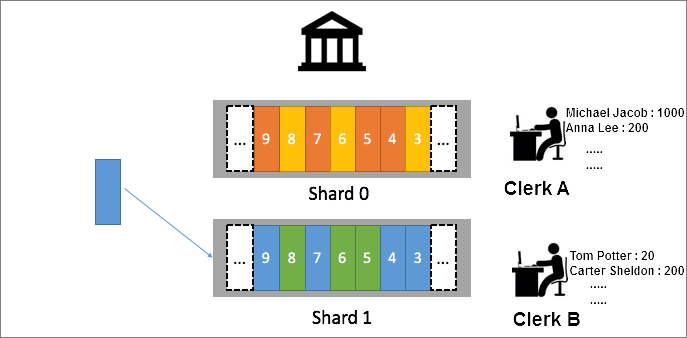
Issue 2: At-least-once processing
Alice deposited money at Counter A. Clerk A received a call when Clerk A was handling this deposit request. After the call, Clerk A mistakenly considered that the deposit request of Alice was processed and started to handle the request from the next user. As a result, the deposit request of Alice was lost.
Computers do not make the same mistakes as clerks and can work more reliably for a longer period. However, computers may fail to process data due to failures or overload. Loss of deposit due to such reasons is not acceptable. To avoid data loss in this scenario, you can use the following solution:
Clerk A records the progress of the current request in a notebook that is different from Account Book A. Then, Clerk A calls the next user only after the deposit request of Alice is processed.

This solution may lead to repetition. For example, after Clerk A handled the deposit request of Alice and updated data in Account Book A, Clerk A was called away and did not record the progress of the current request in the notebook. When Clerk A came back and did not find the progress of the request from Alice in the notebook, Clerk A may process the request again.
Issue 3: Exactly once processing
Repetition may not result in issues.
If you perform an idempotent operation more than once, the repetition of the process does not affect the result. For example, balance inquiry is a read-only operation performed by a user. If the user repeats this operation, the inquiry result is not affected. Some non-read-only operations, such as user logoff, can also be repeatedly performed with no impact on the operation result.
In actual scenarios, most operations such as money deposit and withdrawal are not idempotent. Repetition of these operations has a significant impact on the results. You can use the following solution to avoid repetition. After Clerk A handles a request, Clerk A updates data in Account Book A, records the progress of the current request in the notebook, and then combines the data update and progress record into a checkpoint.
If Clerk A temporarily or permanently leaves, other clerks can continue in the following manner: If a checkpoint is recorded for the current request, proceed to the next request. If no checkpoints are recorded for the current request, process this request. This ensures the atomicity of operations.

A checkpoint is a persistent object in which you can save the position or time of an element in a shard as the key to indicate that the element is processed.
Business challenges
The principles described in the preceding issues are not complicated. However, changes and uncertainties in the number of users and workload volume in the real world further complicate the preceding issues. Examples:
The number of users significantly increases on the pay day.
Unlike computers, clerks need a break and lunchtime.
To improve user experience, the bank manager must increase the number of clerks. This poses the challenge of evaluating the conditions to increase the number of clerks.
Clerks need to hand over account books and checkpoints in an efficient manner.
A business day in a modern bank
The bank opens for business at 08:00 in the morning.
All requests are assigned to the only shard named Shard0. Clerk A is assigned to process the requests.

Peak hours start from 10:00 in the morning.
The bank manager decides to split Shard0 into Shard1 and Shard2 from 10:00 in the morning. The bank manager also assigns requests to the two shards based on the following rules: Assign requests from users whose names start with a letter from A to W to Shard1 and assign requests from users whose names start with
[X, Y, Z]to Shard2. The total number of users whose names start with a letter from A to W is nearly equal to that of users whose names start with X, Y, or Z.The following figure shows the status of requests in the shards from 10:00 to 12:00.

When Clerk A has difficulty in processing requests in two shards, the bank manager dispatches Clerk B and Clerk C. Clerk B takes over one of the shards. Clerk C is idle.
The number of users increases after 12:00.
The bank manager splits Shard1 into Shard3 and Shard4 and assigns Clerk A to process requests in Shard3 and Clerk C to process requests in Shard4. After 12:00, requests that were originally assigned to Shard1 are reassigned to Shard3 and Shard4.
The following figure shows the status of requests in the shards after 12:00.

The number of users decreases from 16:00.
The bank manager asks Clerk A and Clerk B to have a break and asks Clerk C to process requests in Shard2, Shard3, and Shard4. Later, the bank manager combines Shard2 and Shard3 into a shard named Shard5 and combines Shard5 and Shard4 into a shard named Shard6. After all requests in Shard6 are processed, the bank is closed.
Log processing
The preceding process can be abstracted into a typical log processing scenario. To meet the business requirements of banks, an elastic and flexible log framework can be used to provide the following features:
Shards are automatically scaled in or scaled out.
Shards are automatically adapted to the consumers of a consumer group when consumers are added to or removed from the consumer group. This way, data integrity is ensured, and logs are processed in order.
Logs are processed only once. This requires consumers to support ordering.
The consumption process is monitored to ensure that computing resources are allocated based on actual requirements.
Logs from more sources can be collected. In the example of the modern bank, users can send requests from multiple channels, such as online banking, mobile banking, and electronic checks.
You can use Logstore consumer groups to process logs in real time in the preceding scenarios. This way, you can focus on the business logic without the need to worry about resource scaling or failovers. For more information, see Use consumer groups to consume logs.
You can also use Spark Streaming to consume log data in Simple Log Service by using consumer groups. For more information, see Use Spark Streaming to consume log data.