You can use SchedulerX to manage periodic scheduling jobs and query the execution records and operational logs of the jobs. This topic describes the scheduling, execution, and O&M features of SchedulerX.
Periodic scheduling
Crontab
SchedulerX supports periodic scheduling by using UNIX crontab expressions. You cannot use crontab scheduling to trigger a job within seconds. For more information, see Cron.
Fixed rate
The interval specified by a crontab expression must be divisible by 60. You cannot use a crontab expression to specify an interval that cannot be divided by 60. For example, if you want to trigger a job at an interval of 40 minutes, you cannot use crontab expressions. Fixed-rate scheduling is suitable for round-robin scheduling and fixed-rate expressions are simple. You cannot use fixed-rate scheduling to trigger a job within seconds. For more information, see Fixed rate.
Second delay
Second-delay scheduling is suitable for workloads that require high real-time performance. For example, you can use second-delay scheduling if you want to trigger a job at an interval of 10 seconds. You can use second-delay scheduling to trigger a job within seconds. For more information, see Second delay.
Calendar
SchedulerX provides multiple types of calendars for you to schedule jobs. You can also import custom calendars. Calendar scheduling is suitable for financial transactions. For example, you can use calendar scheduling if you want to trigger jobs on each trading day.
Time zone
Time zone scheduling is suitable for cross-border business. You can use time zone scheduling if you want to trigger jobs in the time zone of a specific country.
Data timestamp
SchedulerX allows you to process service data across days. When you create a job, you can configure a time offset for the job. For example, a job is triggered at 00:30:00 every day. If you want to use the job to process data that was updated at 23:30:00 on the previous day, you must set the time offset for the job to 1 hour. The job is still triggered at 00:30:00 every day. After the job is triggered, the job uses
context.getDataTime()to retrieve the data that was updated at 23:30:00 on the previous day.
For more information about how to create a periodic scheduling job, see Create a job.
Job orchestration
You can drag and drop jobs in a directed acyclic graph (DAG) in the SchedulerX console to create a workflow. The DAG provides details of each job and helps you troubleshoot failed downstream jobs. For more information, see Create a workflow.
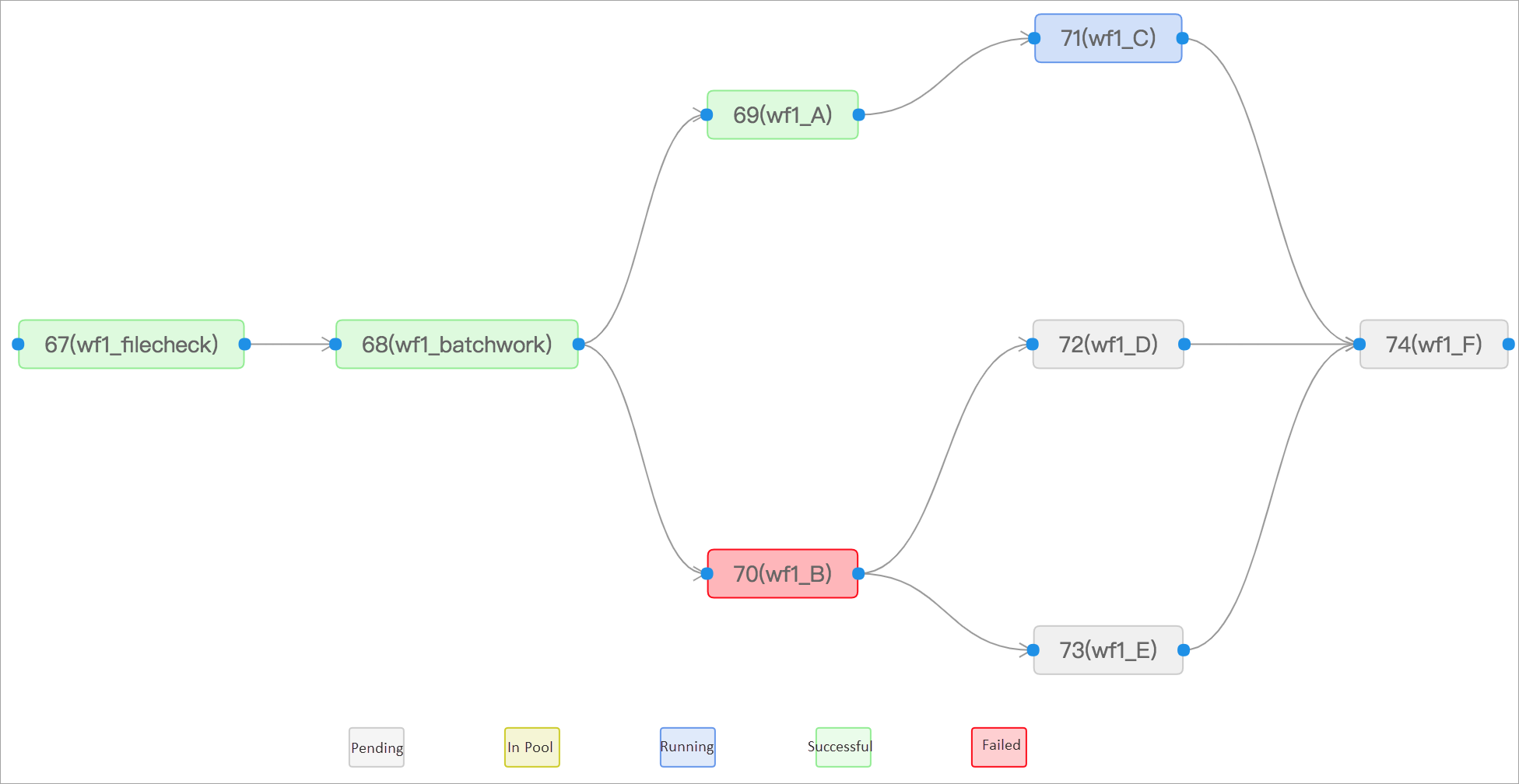
Diverse job types
The periodic scheduling and workflow scheduling features provided by SchedulerX support different programming languages.
Java
You can create Java jobs for Java applications that are connected to SchedulerX by using SchedulerX SDK for Java to run specific Java application methods. For more information, see Java jobs.
Script
You can write and run scripts online. Scripts such as Shell and Python are supported. For more information, see Script jobs.
Golang
You can create and run Go jobs for Go applications that are connected to SchedulerX by using SchedulerX SDK for Go. For more information, see Golang jobs.
XXL-JOB
SchedulerX is compatible with XXL-JOB jobs. You can use SchedulerX to manage XXL-JOB jobs without the need to modify the code of the jobs. For more information, see XXL-JOB jobs.
DataWorks
SchedulerX is integrated with Alibaba Cloud DataWorks. You can introduce DataWorks jobs to a workflow to orchestrate DataWorks jobs and other jobs together. For more information, see DataWorks jobs.
Spring
SchedulerX is compatible with the @Scheduled annotation of Spring jobs. You can use SchedulerX to manage Spring jobs without the need to modify the code of the jobs. For more information, see Spring jobs.
HTTP
http serverless: You do not need to connect a client to your cluster. You can schedule jobs by using a public domain name. For more information, see Configure an HTTP job.
http agent: You must connect schedulerxAgent to your VPC-connected cluster. You can schedule jobs by using a private domain name or an IP address.
Kubernetes
SchedulerX supports Kubernetes script jobs and is compatible with native Kubernetes jobs and CRON jobs. For more information, see Kubernetes jobs.
Distributed computing
SchedulerX provides easy-to-use distributed programming models that allow you to perform batch processing on a large amount of data.
Standalone model
This model randomly distributes a job to a worker. For more information, see Standalone.
Broadcast model
This model runs a job on all workers at the same time and waits until all workers complete the job. For more information, see Broadcast.
Map model
This model uses a Map method that is similar to the Map method in Hadoop MapReduce. The Map method allows you to process a large amount of data on multiple workers by using a few lines of code. For more information, see Visual MapReduce model.
MapReduce model
This model is an extension of the Map model. The MapReduce model deprecates the postProcess method and provides the Reduce interface. After a worker completes all tasks of a job, you can call the Reduce method to return the execution result of the job instance or call back your business data. For more information, see MapReduce.
Sharding model
This model is similar to the Elastic-Job model and supports multiple programming languages. You can configure sharding parameters in the SchedulerX console to evenly distribute shards to multiple agents. For more information, see Sharding models for different programming languages.
Automatic retry on failure
Automatic retry for failed instances
You can configure the number of retries and a retry interval for a failed job instance in the Advanced Configuration section of the Task Management module. For example, you can set the number of retries to 3 and the retry interval to 30 seconds. In this case, the instance enters the Failed state and an alert is sent after the job fails three retries.
Automatic retry for failed tasks
For distributed jobs, such as jobs in the sharding or MapReduce model, SchedulerX also supports retries for the tasks of these jobs if the tasks fail. You can configure the number of retries and a retry interval for failed tasks of a job in the Advanced Configuration section of the Task Management module.
Multiple throttling methods
Instance concurrency
SchedulerX implements traffic throttling at a job granularity. Instance concurrency specifies the maximum number of instances that can run in a job at the same time. The default concurrency value is 1. A value of 1 indicates that a job can run only after the job completes the previous run.
Task concurrency for a single machine
To throttle traffic of a distributed job, you can specify the number of concurrent tasks on each machine.
Task concurrency for all machines
When a large number of machines run in a distributed job, the traffic of tasks of a specific machine may be relatively higher than that of other machines. To throttle traffic of the distributed job, you can configure the pull model in the SchedulerX console. If you specify the number of concurrent tasks on all machines, all compute nodes pull tasks from the master node.
Application priority
SchedulerX implements traffic throttling at an application granularity. Application priority specifies the maximum number of jobs that can run at the same time in an application.
Observability
SchedulerX visualizes data on different GUIs. The following figures show specific GUIs.
User dashboard
Execution records of a job
Operational logs of a job
Stacks of a job
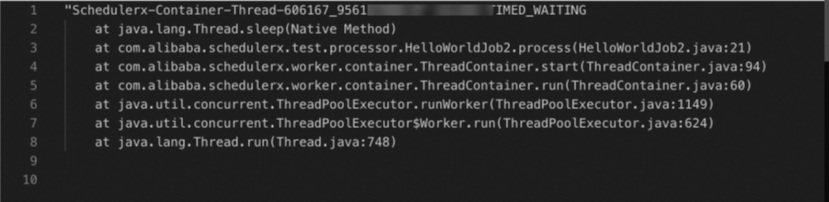
Traces of a job. For more information, see Integrate tracing analysis.
Operation records of a job
Powerful O&M capabilities
Enable and disable jobs
You can dynamically enable and disable jobs in the SchedulerX console.
Rerun failed jobs
If a job fails, you can modify the code of the job, republish the job, and then immediately rerun the job.
Mark jobs as completed
If a job fails, you can rerun it after it is calibrated in the background. However, the rerun process takes hours to complete. You can mark the job as completed to skip it.
Stop jobs
You can implement kill() of the JobProcessor to terminate jobs or tasks in the SchedulerX console.
Update job outputs
You may want to update the output of a job that has a data timestamp. For example, a business report is generated from a workflow. However, you want to add a field to the report or you have found errors in the data of the previous month. In this case, you can trigger the job to reprocess the data of the previous month. SchedulerX allows you to update the outputs of jobs or workflows. The interval of the data points that you want to update must be one day. Different job instances have different data timestamps.
Monitoring and alerting
Alert type: generates alerts when operations fail to be performed, operations time out, or no machines are available, and sends notifications for successful operations.
Alert contact: supports alert contact groups.
Alert record: records historical alerts.
Alerting method: supports text messages, phone calls, emails, and webhooks.