This topic provides answers to some frequently asked questions about the connectors of Realtime Compute for Apache Flink.
Kafka
How do I obtain JSON data from Kafka in Realtime Compute for Apache Flink?
What is the purpose of the commit offset mechanism in Kafka?
How does the Kafka connector parse nested JSON-formatted data?
How do I connect to a Kafka cluster for which security information is configured?
What do I do if an unexpected service latency occurs when data is read from Kafka?
How do I fix the "'upsert-kafka' tables require to define a PRIMARY KEY constraint" error?
DataHub
MaxCompute
How do full and incremental MaxCompute source tables read data from MaxCompute?
How do I configure the startPartition parameter for an incremental MaxCompute source table?
How do I configure the partition parameter when data is read from or written to partitions?
What is the difference between max_pt() and max_pt_with_done()?
MySQL
ApsaraDB RDS for MySQL
ClickHouse
Print
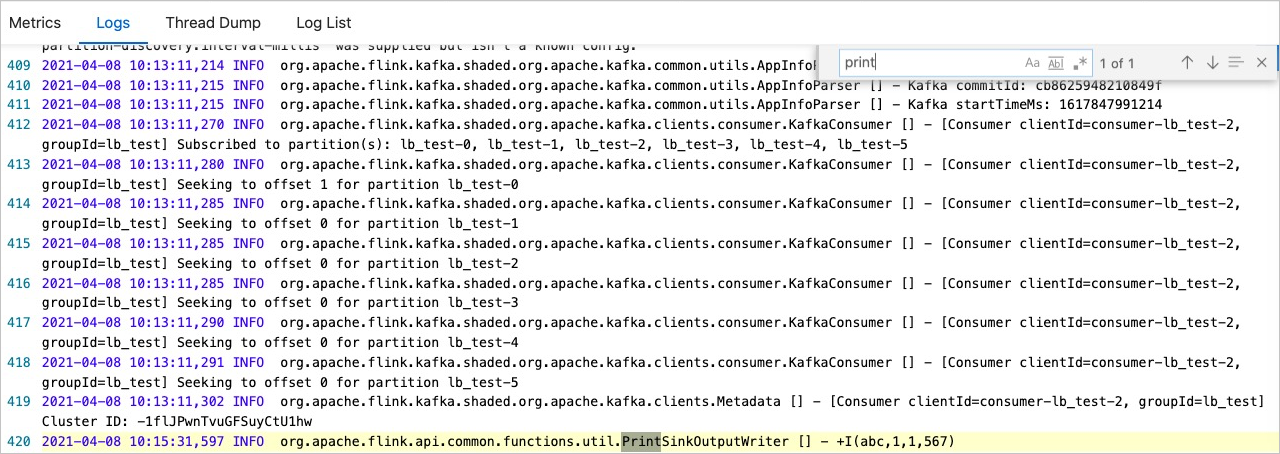
How do I view print data results in the console of Realtime Compute for Apache Flink?
Tablestore
What do I do if no data can be found when I join a dimension table with another table?
ApsaraMQ for RocketMQ
Hologres
What do I do if the "BackPressure Exceed reject Limit" error message appears?
What do I do if the "no table is defined in publication" error message appears?
How do I fix the "permission denied for database" exception when launching a job?
How do I deal with data precision mismatch when reading binary logs in JDBC mode?
Simple Log Service
Paimon
How do I specify the consumer offset for a Paimon source table?
How do I fix the "No space left on device" error when using the Paimon connector?
What do I do if a large number of Apache Paimon files are stored in OSS?
Does the checkpoint interval affect the visibility of data written by the Paimon connector?
Why is memory usage gradually increasing in a long-running job that writes data to Paimon?
Hudi
AnalyticDB for MySQL 3.0
What do I do if the "multi-statement be found." error message appears?
Custom connectors
How do I obtain JSON data from Kafka in Realtime Compute for Apache Flink?
For more information about how to obtain common JSON data, see JSON Format in the Apache Flink documentation.
If you want to obtain nested JSON data, you can define JSON objects in the ROW format in the source table's DDL statement, define the keys that correspond to the JSON data that you want to obtain in the sink table's DDL statement, and configure the method to obtain the values of the keys in the DML statement. Examples:
Test data
{ "a":"abc", "b":1, "c":{ "e":["1","2","3","4"], "f":{"m":"567"} } }Source table's DDL statement
CREATE TEMPORARY TABLE `kafka_table` ( `a` VARCHAR, b int, `c` ROW<e ARRAY<VARCHAR>,f ROW<m VARCHAR>> --c specifies a JSON object, which is of the ROW type in Realtime Compute for Apache Flink. e specifies a JSON list, which is of the ARRAY type. ) WITH ( 'connector' = 'kafka', 'topic' = 'xxx', 'properties.bootstrap.servers' = 'xxx', 'properties.group.id' = 'xxx', 'format' = 'json', 'scan.startup.mode' = 'xxx' );Sink table's DDL statement
CREATE TEMPORARY TABLE `sink` ( `a` VARCHAR, b INT, e VARCHAR, `m` varchar ) WITH ( 'connector' = 'print', 'logger' = 'true' );DML statement
INSERT INTO `sink` SELECT `a`, b, c.e[1], --Realtime Compute for Apache Flink traverses the array from 1. This example shows how Realtime Compute for Apache Flink obtains Element 1 from the array. If you want to obtain the entire array, remove [1]. c.f.m FROM `kafka_table`;Test results
Realtime Compute for Apache Flink is connected to Kafka but cannot read data from or write data to Kafka. What do I do?
Cause
If a forwarding mechanism, such as a proxy or a port mapping, is used to connect Realtime Compute for Apache Flink to Kafka, the Kafka client (Flink's Kafka connector) obtains the endpoints of Kafka brokers instead of the address of the proxy. In this case, Realtime Compute for Apache Flink cannot read data from or write data to Kafka even if the two systems are connected.
The process to connect Realtime Compute for Apache Flink to a Kafka client consists of the following steps:
The Kafka client obtains the metadata of the Kafka broker, including the endpoints of all Kafka brokers.
Realtime Compute for Apache Flink uses the obtained endpoints of Kafka brokers to read data from or write data to Kafka.
Troubleshooting
To troubleshoot this issue, you can perform the following steps to check whether a forwarding mechanism, such as a proxy or a port mapping, is used to connect Realtime Compute for Apache Flink to Kafka:
Use the ZooKeeper command-line tool zkCli.sh or zookeeper-shell.sh to log on to the ZooKeeper service that is used by your Kafka cluster.
Run a command based on the information about your Kafka cluster to obtain the metadata of your Kafka brokers.
In most cases, you can run the
get /brokers/ids/0command to obtain the metadata of Kafka brokers. You can obtain the endpoint of Kafka from theendpointsfield.
Run commands such as
pingortelnetto test the connectivity between Realtime Compute for Apache Flink and the endpoint in the endpoints field.If the connectivity test fails, a forwarding mechanism, such as a proxy or a port mapping, is used to connect Realtime Compute for Apache Flink to Kafka.
Solutions
Set up a direct connection between Realtime Compute for Apache Flink and Kafka, instead of using a forwarding mechanism such as a proxy or a port mapping. This way, Realtime Compute for Apache Flink can directly connect to Kafka by using the endpoint in the endpoints field of the Kafka broker metadata.
Contact Kafka O&M staff to set the advertised.listeners property of Kafka brokers to the forwarding address. This way, the metadata of the Kafka brokers obtained by the Kafka client contains the forwarding address.
NoteOnly Kafka 0.10.2.0 and later allow you to add the forwarding address to the advertised.listeners property of Kafka brokers.
For more information, see KIP-103: Separation of Internal and External traffic and visit Kafka network connection issues.
Why is no data output returned after the data of a Kafka source table is calculated by using event time-based window functions?
Description
After the data of a Kafka source table is processed by using event time-based window functions, no data output is returned.
Cause
No watermark is generated because a partition of the Kafka source table has no data. As a result, no data is returned after event time-based window functions are used to calculate the data of the Kafka source table.
Solutions
Make sure that all partitions of the Kafka source table contain data.
Enable the idleness detection feature for source data. Add the following code to the Other Configuration field in the Parameters section of the Configuration tab and save the code for the code to take effect. For more information, see How do I configure custom parameters for deployment running?
table.exec.source.idle-timeout: 5For information about the table.exec.source.idle-timeout parameter, see Configuration.
What is the purpose of the commit offset mechanism in Kafka?
The commit offset mechanism in Kafka is mainly used to ensure the consistency and reliability of streaming data processing. The mechanism can record the location of processed data to prevent data duplication or loss. In most cases, commit offset is used together with the message queue service (such as Kafka) in streaming data processing to control the progress of data consumption. Realtime Compute for Apache Flink commits the read offset to Kafka each time a checkpoint is generated. This way, the location of the processed data is recorded. If checkpointing is disabled or the checkpoint interval is too large, you may fail to query the read offset in Kafka. This may cause data duplication or loss.
How does the Kafka connector parse nested JSON-formatted data?
When the Kafka connector is used to parse the following JSON-formatted data, the data is parsed into an ARRAY<ROW<cola VARCHAR, colb VARCHAR>> field. This field is an array of the ROW type and contains two child fields of the VARCHAR data type. Then, the data is parsed by using a user-defined table-valued function (UDTF).
{"data":[{"cola":"test1","colb":"test2"},{"cola":"test1","colb":"test2"},{"cola":"test1","colb":"test2"},{"cola":"test1","colb":"test2"},{"cola":"test1","colb":"test2"}]}How do I connect to a Kafka cluster for which security information is configured?
Add the security configurations related to encryption and authentication to the parameters in the WITH clause of the Kafka table's DDL statement. For more information about the security configurations, see SECURITY in Kafka documentation. The following sample code provides an example of the security configurations.
ImportantYou must add the properties. prefix to the security configurations.
Configure a Kafka table to use PLAIN as the Simple Authentication and Security Layer (SASL) mechanism and provide the Java Authentication and Authorization Service (JAAS) configuration.
CREATE TABLE KafkaTable ( `user_id` BIGINT, `item_id` BIGINT, `behavior` STRING, `ts` TIMESTAMP(3) METADATA FROM 'timestamp' ) WITH ( 'connector' = 'kafka', ... 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.sasl.mechanism' = 'PLAIN', 'properties.sasl.jaas.config' = 'org.apache.flink.kafka.shaded.org.apache.kafka.common.security.plain.PlainLoginModule required username=\"username\" password=\"password\";' );Use SASL_SSL as the security protocol and SCRAM-SHA-256 as the SASL mechanism.
CREATE TABLE KafkaTable ( `user_id` BIGINT, `item_id` BIGINT, `behavior` STRING, `ts` TIMESTAMP(3) METADATA FROM 'timestamp' ) WITH ( 'connector' = 'kafka', ... 'properties.security.protocol' = 'SASL_SSL', /* Configure SSL. */ /* Configure the path of the certificate authority (CA) certificate truststore provided by the server. */ 'properties.ssl.truststore.location' = '/flink/usrlib/kafka.client.truststore.jks', 'properties.ssl.truststore.password' = 'test1234', /* Configure the path of the private key file keystore if client authentication is required. */ 'properties.ssl.keystore.location' = '/flink/usrlib/kafka.client.keystore.jks', 'properties.ssl.keystore.password' = 'test1234', /* Configure SASL. */ /* Set the SASL mechanism to SCRAM-SHA-256. * / 'properties.sasl.mechanism' = 'SCRAM-SHA-256', /* Configure JAAS. */ 'properties.sasl.jaas.config' = 'org.apache.flink.kafka.shaded.org.apache.kafka.common.security.scram.ScramLoginModule required username=\"username\" password=\"password\";' );NoteIf the properties.sasl.mechanism parameter is set to SCRAM-SHA-256, set the properties.sasl.jaas.config parameter to org.apache.flink.kafka.shaded.org.apache.kafka.common.security.scram.ScramLoginModule.
If the properties.sasl.mechanism parameter is set to PLAINTEXT, set the properties.sasl.jaas.config parameter to org.apache.flink.kafka.shaded.org.apache.kafka.common.security.plain.PlainLoginModule.
Upload all required files, such as a certificate, public key file, or private key file, in Additional Dependencies for the deployment.
The files that are uploaded are stored in the /flink/usrlib directory. For more information about how to upload a file in Additional Dependencies, see Create a deployment.
ImportantIf the authentication mechanism for the username and password on the Kafka broker is SASL_SSL but the authentication mechanism on the client is SASL_PLAINTEXT, the OutOfMemory exception is reported during draft validation. In this case, you must change the authentication mechanism on the client.
How do I resolve field name conflicts?
Description
Messages from Kafka are serialized into two JSON-formatted strings. In this case, the key and value contain the same field, such as the id field. If the strings are directly parsed as a Flink table for processing, a field name conflict occurs.
key
{ "id": 1 }value
{ "id": 100, "name": "flink" }
Solution
To prevent the preceding issue, configure the key.fields-prefix property in the Kafka table's DDL statement as follows:
CREATE TABLE kafka_table ( -- Specify the key and value fields. key_id INT, value_id INT, name STRING ) WITH ( 'connector' = 'kafka', 'topic' = 'test_topic', 'properties.bootstrap.servers' = 'localhost:9092', 'format' = 'json', 'json.ignore-parse-errors' = 'true', -- Specify the key field and data type. 'key.format' = 'json', 'key.fields' = 'id', 'value.format' = 'json', 'value.fields' = 'id, name', -- Configure a prefix for the key field. 'key.fields-prefix' = 'key_' );In the preceding example, the key.fields-prefix property is set to key_ when the table is created. In this case, the key field (id in this example) is prefixed with key_ during the processing of Kafka data. Therefore, the key field's name in the Kafka table becomes key_id, which is distinguished from .
When you run the
SELECT * FROM kafka_table;command to query data, the following result is returned:key_id: 1, value_id: 100, name: flink
What do I do if an unexpected service latency occurs when data is read from Kafka?
Description
The value of the currentEmitEventTimeLag metric indicates a latency of more than 50 years when data is read from the Kafka source table. The following figure shows an example.
Troubleshooting
Check whether the deployment is a JAR deployment or an SQL deployment.
For a JAR deployment, check whether the Kafka dependency in the Project Object Model (POM) file is a built-in dependency of Realtime Compute for Apache Flink. If the Kafka dependency in the POM file is the dependency of Kafka, no latency-related metrics are displayed.
Check whether data is inserted into all partitions of the upstream Kafka topic in real time.
Check whether the timestamp of metadata on a Kafka message is 0 or null.
The data latency of the Kafka source is calculated by subtracting the timestamp on a Kafka message from the current time. When the message does not contain the timestamp, the value of the currentEmitEventTimeLag metric indicates a latency of more than 50 years. You can use one of the following methods to identify the issue:
For an SQL deployment, you can define a metadata column to obtain the timestamp on a Kafka message. For more information, see Create an ApsaraMQ for Kafka source table.
CREATE TEMPORARY TABLE sk_flink_src_user_praise_rt ( `timestamp` BIGINT , `timestamp` TIMESTAMP METADATA, -- The timestamp of metadata. ts as to_timestamp ( from_unixtime (`timestamp`, 'yyyy-MM-dd HH:mm:ss') ), watermark for ts as ts - interval '5' second ) WITH ( 'connector' = 'kafka', 'topic' = '', 'properties.bootstrap.servers' = '', 'properties.group.id' = '', 'format' = 'json', 'scan.startup.mode' = 'latest-offset', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true' );Write a simple Java program and use KafkaConsumer to read Kafka messages for testing.
How do I fix the "'upsert-kafka' tables require to define a PRIMARY KEY constraint" error?
Problem description

Cause
This error occurs because the primary key is not specified in the Upsert Kafka sink table's DDL definition. The Upsert Kafka connector partitions upstream changelog events (INSERT, UPDATE_AFTER, and DELETE) based on the primary key, ensuring messages with the same primary key are distributed to the same partition and processed in order.
Solution
Specify the primary key in the Upsert Kafka sink table's DDL definition.
How do I resume a deployment of Realtime Compute for Apache Flink that fails to run after a DataHub topic is split or scaled in?
If a topic that is being read by Realtime Compute for Apache Flink is split or scaled in, the deployment of Realtime Compute for Apache Flink fails and cannot resume. If you want to resume the deployment, you must cancel the deployment, and then start the deployment.
Can I delete a DataHub topic that is being consumed?
No, you cannot delete or recreate a DataHub topic that is being consumed.
What do the endPoint and tunnelEndpoint parameters mean? What happens if the two parameters are incorrectly configured?
For more information, see Endpoints. If these two parameters are incorrectly configured in a virtual private cloud (VPC), the following errors may occur:
If the endPoint parameter is incorrectly configured, the task stops when the progress reaches 91%.
If the tunnelEndpoint parameter is incorrectly configured, the task fails to run.
How do full and incremental MaxCompute source tables read data from MaxCompute?
Full and incremental MaxCompute source tables read data from MaxCompute via MaxCompute Tunnel. Therefore, the read speed is limited by the bandwidth of MaxCompute Tunnel.
If MaxCompute is used as a data source, can the full or incremental MaxCompute source table read the data that is appended to an existing partition or table after a deployment of Realtime Compute for Apache Flink starts?
No, the new data cannot be read. If new data is appended to the partition or the table that is read or is being read by the full or incremental MaxCompute source table after a deployment of Realtime Compute for Apache Flink starts, the data cannot be read and a failover may be triggered.
Full and incremental MaxCompute source tables use ODPS DOWNLOAD SESSION to read data from a partition or table. When you create a download session, the MaxCompute server creates an index file that contains the data mappings obtained when you create the download session. Subsequent data reading is performed based on the data mappings. Therefore, in most cases, the data that is appended to a MaxCompute table or to a partition in the table after you create a download session cannot be read. If new data is written to MaxCompute, two exceptions may occur:
If data is read from MaxCompute via Tunnel, the following error occurs:
ErrorCode=TableModified,ErrorMessage=The specified table has been modified since the download initiated.The accuracy of data cannot be guaranteed. If new data is written after MaxCompute Tunnel is disabled, the data is not read. If a deployment is recovered from a failover or is resumed, the data may not be correct. For example, existing data is read again but the new data may not be completely read.
After I suspend a deployment for a full or incremental MaxCompute source table, can I change the degree of parallelism for the deployment and resume the deployment that I suspended?
If the useNewApi parameter is set to true for a streaming deployment that uses a MaxCompute source table, you can change the degree of parallelism for the deployment and resume the deployment after you suspend the deployment. By default, the useNewApi parameter is set to true. The MaxCompute source table reads data from multiple matched partitions in sequence. When the MaxCompute source table reads data from a specific partition, data of different ranges in the partition is distributed to each subtask based on the degree of parallelism. If you change the degree of parallelism for the deployment, the parallel data distribution method for the partition that is being read before the deployment is suspended remains unchanged. Instead, data in the next partition is distributed to each subtask based on the new degree of parallelism. Therefore, if you increase the degree of parallelism for the deployment and restart the deployment when data in a large partition is read, data in the partition may be read by only some MaxCompute operators.
You cannot change the degree of parallelism for a batch deployment or a deployment in which the useNewApi parameter is set to false.
Why is the data in the partitions before the start offset also read when I set the start offset of a deployment to 2019-10-11 00:00:00?
The start offset is valid only for message queue data sources, such as DataHub. You cannot apply the start offset in MaxCompute source tables. After you start a deployment, Realtime Compute for Apache Flink reads data by using the following methods:
For a partitioned table, Realtime Compute for Apache Flink reads data from all existing partitions.
For a non-partitioned table, Realtime Compute for Apache Flink reads all existing data.
What do I do if an incremental MaxCompute source table detects a new partition when data is still being written to the partition?
No mechanism is provided to check the data completeness of a partition. When a new partition is detected, the source table starts to read data from the partition. For example, the incremental MaxCompute source table reads data from the MaxCompute partitioned table T whose partition key column is ds. We recommend that you write data to the MaxCompute table by using the following method: Execute the Insert overwrite table T partition (ds='20191010') ... statement without creating a partition first. If the write operation is successful, the partition and partition data are available at the same time.
Do not create a partition, such as ds=20191010, and write data to the partition, because if the incremental MaxCompute source table detects the new partition ds=20191010, the source table immediately reads data from the new partition. If not all data has not been written to the partition yet, the data that is read from MaxCompute is incomplete.
What do I do if the "ErrorMessage=Authorization Failed [4019], You have NO privilege" error message appears when using the MaxCompute connector?
Description
An error message appears on the Failover page or on the TaskManager.log page when a deployment is running:
ErrorMessage=Authorization Failed [4019], You have NO privilege'ODPS:***'Cause
The user identity information specified in the MaxCompute table's DDL statement cannot be used to access MaxCompute.
Solution
Use an Alibaba Cloud account, a RAM user, or a RAM role to authenticate the user identity. For more information, see User authentication.
How do I configure the startPartition parameter for an incremental MaxCompute source table?
Perform the following steps to configure the startPartition parameter:
Step | Description | Example |
1 | Use an equal sign (=) to connect the name of each partition key column and the related partition value. Each partition value must be a fixed value. | The partition key column is dt, and you want to start to read data from the data record whose value of dt is 20220901. In this case, the result is dt=20220901. |
2 | Sort the results that are obtained in the first step by partition level in ascending order. Separate the results with commas (,) with no spaces. The result that is obtained in this step is the value of the startPartition parameter. Note You can specify all partition levels or only the first several partition levels. |
|
When the incremental MaxCompute source table loads the partition list, the source table compares all partitions in the partition list with the partition that is specified by the startPartition parameter based on the alphabetical order. The source table loads the partitions whose alphabetical order is greater than or equal to the partition that is specified by the startPartition parameter. For example, an incremental MaxCompute partitioned table contains the first-level partition key column ds and the second-level partition key column type and contains the following partitions:
ds=20191201,type=a
ds=20191201,type=b
ds=20191202,type=a
ds=20191202,type=b
ds=20191202,type=c
ds=20191203,type=a
If the value of the startPartition parameter is ds=20191202, the following partitions are read: ds=20191202,type=a, ds=20191202,type=b, ds=20191202,type=c, and ds=20191203,type=a. If the value of the startPartition parameter is ds=20191202,type=b, the following partitions are read: ds=20191202,type=b, ds=20191202,type=c, and ds=20191203,type=a.
The partition that is specified by the startPartition parameter does not necessarily need to exist. All partitions whose alphabetical order is greater than or equal to the partition that is specified by the startPartition parameter are read.
Why is data reading not started after a deployment that uses an incremental MaxCompute source table is started?
Excessive partitions whose alphabetical order is greater than or equal to the partition that is specified by the startPartition parameter exist, or partitions whose alphabetical order is greater than or equal to the partition that is specified by the startPartition parameter contain excessive small files. Before the incremental MaxCompute source table starts to read data, the source table must sort the information about existing partitions that meet the specific conditions. We recommend that you take note of the following items:
Do not read excessive historical data.
NoteIf you want to process historical data, you can run a batch deployment that uses a MaxCompute source table.
Decrease the number of small files in historical data.
How do I configure the partition parameter when data is read from or written to partitions?
Read data from partitions
Read data from static partitions
To read data from static partitions to a source or dimension table, perform the steps that are described in the following table to configure the partition parameter.
Step
Description
Example
1
For a dimension table, connect the name of each partition key column and the related partition value with an equal sign (=). Each partition value must be a fixed value.
For a source table, connect the name of each partition key column and the related partition value with an equal sign (=). Each partition value can be a fixed value or a value that contains asterisks (*) as wildcards. Wildcards can be used to match any string, including empty strings.
The partition key column is dt, and you want to read data whose value of dt is 20220901. In this case, the result is
dt=20220901.The partition key column is dt, and you want to read data whose value of dt starts with 202209. In this case, the result is
dt=202209*(only for the source table.)The partition key column is dt, and you want to read data whose value of dt starts with 2022 and ends with 01. In this case, the result is
dt=2022*01 (only for the source table.).The partition key column is dt, and you want to read data from all partitions. In this case, the result is
dt=*(only for the source table.)
2
Sort the results that are obtained in the first step by partition level in ascending order. Separate the results with commas (,) with no spaces. The result that is obtained in this step is the value of the partition parameter.
You can specify all partition levels or only the first few partition levels.
If the table has only the first-level partition key column named dt and you want to read data from partitions that meet the condition of dt=20220901, you can configure
'partition' = 'dt=20220901'.If the first-level partition key column is dt, the second-level partition key column is hh, and the third-level partition key column is mm and you want to read data from partitions that meet the condition of dt=20220901, hh=08, mm=10, you can specify
'partition' = 'dt=20220901,hh=08,mm=10'.If the first-level partition key column is dt, the second-level partition key column is hh, and the third-level partition key column is mm and you want to read data from partitions that meet the condition of dt=20220901, hh=08, you can configure
'partition' = 'dt=20220901,hh=08' or 'partition' = 'dt=20220901,hh=08,mm=*'.If the first-level partition key column is dt, the second-level partition key column is hh, and the third-level partition key column is mm and you want to read data from partitions that meet the conditions of dt=20220901, mm=10, you can enter
'partition' = 'dt=20220901,hh=*,mm=10'.
If the preceding steps cannot meet your partition filter requirements, you can also add filter conditions to the WHERE clause of the SQL statement and use the partition pushdown feature of the SQL optimizer to filter partitions. For example, if the first-level partition key column is dt and the second-level partition key column is hh and you want to read data from partitions that meet the conditions of dt>=20220901, dt<=20220903, hh>=09, and hh<=17, you can use the following sample SQL code:
CREATE TABLE maxcompute_table ( content VARCHAR, dt VARCHAR, hh VARCHAR ) PARTITIONED BY (dt, hh) WITH ( -- You must use PARTITIONED BY to specify partition key columns. Otherwise, the partition pushdown feature of the SQL optimizer cannot be enabled. This affects the partition filter efficiency. 'connector' = 'odps', ... -- Configure required parameters, such as accessId. The partition parameter is optional. If you do not configure this parameter, the SQL optimizer filters partitions. ); SELECT content, dt, hh FROM maxcompute_table WHERE dt >= '20220901' AND dt <= '20220903' AND hh >= '09' AND hh <= '17'; -- Configure the partition filter condition in the WHERE clause.Read data from the partition that is ranked first in alphabetical order
If data needs to be read from the partition that is ranked first in alphabetical order, set the partition parameter to
'partition' = 'max_pt()'.If data needs to be read from the first two partitions that are ranked in alphabetical order, set the partition parameter to
'partition' = 'max_two_pt()'.If data needs to be read from the first partition that matches a partition whose name ends with ".done", set the partition parameter to
'partition' = 'max_pt_with_done()'.
In most cases, the partition that is ranked first in alphabetical order is also the latest partition that is generated. In specific cases, if the data in the latest partition is not ready and you want the dimension table to read earlier data, you can set the partition parameter to max_pt_with_done().
When data preparation in a partition is complete, you must create an empty partition named in the format: Partition name.done. For example, when data preparation in the dt=20220901 partition is complete, you must create an empty partition named dt=20220901.done. After you set the partition parameter to max_pt_with_done(), the dimension table reads data only from the partition whose corresponding ".done" partition exists. For more information, see the What is the difference between max_pt() and max_pt_with_done()? section of this topic.
NoteWhen a deployment is started, the source table obtains data only of the partition that is ranked first in alphabetical order. After all data in the partition is read, the source table stops running and does not monitor whether a new partition is generated. If you want the source table to continuously read new partitions, use an incremental source table. Each time a dimension table is updated, the dimension table checks the latest partition and reads the latest data.
Write data to partitions
Write data to a static partition
If the sink table needs to write data to static partitions, you can perform the steps that are described in "Read data from static partitions" to configure the partition parameter.
ImportantThe partition parameter that is configured for a sink table does not support asterisks (*) as wildcards.
Write data to a dynamic partition
When the sink table needs to write data to the related partition based on the values of partition key columns in the data, you must sort the partition key column names by partition level in ascending order and separate the partition key column names with commas (,). Spaces are not allowed. In this case, the result is the value of the partition parameter. For example, if the first-level partition is dt, the second-level partition is hh, and the third-level partition is mm, you can specify
'partition' = 'dt,hh,mm'.
Why does a deployment that uses a MaxCompute source table remain in the starting status? Or why does it take a long time to generate data after the deployment is started?
This issue is caused by one of the following reasons:
The MaxCompute source table contains excessive small files.
The MaxCompute storage cluster does not reside in the same region as the Flink computing cluster. As a result, the network communication requires a long period of time. We recommend that you deploy a MaxCompute storage cluster that resides in the same region as the Flink computing cluster before you perform operations.
The MaxCompute permission configuration is invalid. The Download control on the MaxCompute source table is required.
How do I select a data tunnel?
MaxCompute provides the following types of tunnels: Batch Tunnel and Streaming Tunnel. You can select a tunnel type based on your business requirements for consistency and operational efficiency. The following table describes the differences between the two types of tunnels.
Business requirement | Batch Tunnel | Streaming Tunnel |
Consistency | Batch Tunnel is more reliable than Streaming Tunnel when writing data to MaxCompute. It supports the at-least-once semantics, ensuring that no data is lost. Data may be duplicated only if:
| Streaming Tunnel supports the at-least-once semantics, ensuring no data is lost. However, data may be duplicated upon any exception during job running. |
Operation efficiency | It is less efficient than Streaming Tunnel because data is committed during checkpointing and files are created on the server. | Streaming Tunnel does not commit data during checkpointing. If you use Streaming Tunnel and set the numFlushThreads parameter to a value greater than 1, Streaming Tunnel can continuously receive upstream data while flushing data. This results in a higher overall operational efficiency. |
If the execution of a checkpoint on a deployment that uses Batch Tunnel is slow or even times out and the downstream store allows for duplicate data, you can use Streaming Tunnel for the deployment.
What do I do if duplicate data is written to MaxCompute?
If duplicate data is generated when the MaxCompute connector is used to write data to MaxCompute in a Realtime Compute for Apache Flink deployment, perform the following operations to troubleshoot the issue:
Check the logic of the draft. When Realtime Compute for Apache Flink writes data to MaxCompute by using the MaxCompute connector, Realtime Compute for Apache Flink does not check the uniqueness of a primary key even if a primary key constraint is declared in the MaxCompute sink table's DDL. In addition, non-transactional tables of MaxCompute do not support primary key constraints. If duplicate data is generated during data processing based on the logic of your Realtime Compute for Apache Flink draft, the data that is written to MaxCompute also contains the duplicate data.
Check whether multiple Realtime Compute for Apache Flink deployments are run to write data to the same MaxCompute table at the same time. MaxCompute does not support primary key constraints. If the same result is obtained in multiple Realtime Compute for Apache Flink deployments, the MaxCompute table to which data is written contains duplicate data.
If Batch Tunnel is used, check whether your Realtime Compute for Apache Flink deployment fails during checkpointing. If your Realtime Compute for Apache Flink deployment fails during checkpointing, data in the MaxCompute sink table may have been submitted to MaxCompute. When your Realtime Compute for Apache Flink deployment is resumed from the previous checkpoint, data between the two checkpoints may be duplicated.
If Streaming Tunnel is used, check whether your Realtime Compute for Apache Flink deployment performs a failover during checkpointing. If you enable Streaming Tunnel to write data to MaxCompute, data between checkpoints is submitted to MaxCompute. Therefore, if your Realtime Compute for Apache Flink deployment performs a failover and is resumed from the most recent checkpoint, the data that is generated after the most recent checkpointing is complete and before your Realtime Compute for Apache Flink deployment performs a failover may be repeatedly written to MaxCompute. For more information, see the How do I select a data tunnel? section of this topic. In this case, you can switch to the Batch Tunnel mode to avoid duplicate data.
If Batch Tunnel is used, check whether your Realtime Compute for Apache Flink deployment performs a failover or restarts after the deployment is canceled. For example, a Realtime Compute for Apache Flink deployment may be canceled and then started due to optimization based on Autopilot. If the Realtime Compute for Apache Flink engine version is earlier than vvr-6.0.7-flink-1.15, data of the MaxCompute sink table is submitted before the MaxCompute connector is disabled. Therefore, if the Realtime Compute for Apache Flink deployment is canceled and resumed from the previous checkpoint, the data that is generated during the period of time between checkpointing and deployment cancellation may be repeatedly written to MaxCompute. You can upgrade the engine version of Realtime Compute for Apache Flink to vvr-6.0.7-flink-1.15 or later to resolve the issue.
What do I do if the "Invalid partition spec" error message appears when a deployment that uses a MaxCompute sink table runs?
Cause: The value of a partition key column in the data that is written to MaxCompute is invalid. Invalid values include an empty string, a null value, and a value that contains equal signs (=), commas (,), or slashes (/).
Solution: Check whether invalid data exists.
What do I do if the "No more available blockId" error message appears when a deployment that uses a MaxCompute sink table runs?
Cause: The number of blocks that are written to the MaxCompute sink table exceeds the upper limit. This indicates that the amount of data that is flushed each time is excessively small and frequent flush operations are performed.
Solution: We recommend that you change the values of the batchSize and flushIntervalMs parameters.
How do I use the SHUFFLE_HASH hint for a dimension table?
By default, information about the entire dimension table is stored in each subtask. If a dimension table contains a large amount of data, you can use the SHUFFLE_HASH hint to evenly distribute the data of the dimension table to subtasks. This reduces the consumption of the Java virtual machine (JVM) heap memory. In the following example, the data of the dim_1 and dim_3 dimension tables is distributed to subtasks after the SHUFFLE_HASH hint is used, but the data of the dim_2 dimension table is still completely cached in each subtask.
-- Create a source table and three dimension tables.
CREATE TABLE source_table (k VARCHAR, v VARCHAR) WITH ( ... );
CREATE TABLE dim_1 (k VARCHAR, v VARCHAR) WITH ('connector' = 'odps', 'cache' = 'ALL', ... );
CREATE TABLE dim_2 (k VARCHAR, v VARCHAR) WITH ('connector' = 'odps', 'cache' = 'ALL', ... );
CREATE TABLE dim_3 (k VARCHAR, v VARCHAR) WITH ('connector' = 'odps', 'cache' = 'ALL', ... );
-- Specify the names of the dimension tables whose data needs to be distributed to subtasks in the SHUFFLE_HASH hint.
SELECT /*+ SHUFFLE_HASH(dim_1), SHUFFLE_HASH(dim_3) */
k, s.v, d1.v, d2.v, d3.v
FROM source_table AS s
INNER JOIN dim_1 FOR SYSTEM_TIME AS OF PROCTIME() AS d1 ON s.k = d1.k
LEFT JOIN dim_2 FOR SYSTEM_TIME AS OF PROCTIME() AS d2 ON s.k = d2.k
LEFT JOIN dim_3 FOR SYSTEM_TIME AS OF PROCTIME() AS d3 ON s.k = d3.k;How do I configure the CacheReloadTimeBlackList parameter?
Data type:
StringUse
->to connect the start and end times.Use
,to separate multiple time periods.Time format:
YYYY-MM-DD HH:mm(If only the hour and minute are specified, it defaults to every day).
Example setting: 'cacheReloadTimeBlackList' = '14:00 -> 15:00,23:00 -> 01:00'Example scenario | Sample value |
Daily interval | 14:00 -> 15:00 |
Multiple daily intervals | 14:00 -> 15:00,23:00 -> 01:00 |
Including specific date | 14:00 -> 15:00, 23:00 -> 01:00,2025-10-01 22:00 -> 2025-10-01 23:00 |
What do I do if the "java.io.EOFException: SSL peer shut down incorrectly" error message appears?
Description
Caused by: java.io.EOFException: SSL peer shut down incorrectly at sun.security.ssl.SSLSocketInputRecord.decodeInputRecord(SSLSocketInputRecord.java:239) ~[?:1.8.0_302] at sun.security.ssl.SSLSocketInputRecord.decode(SSLSocketInputRecord.java:190) ~[?:1.8.0_302] at sun.security.ssl.SSLTransport.decode(SSLTransport.java:109) ~[?:1.8.0_302] at sun.security.ssl.SSLSocketImpl.decode(SSLSocketImpl.java:1392) ~[?:1.8.0_302] at sun.security.ssl.SSLSocketImpl.readHandshakeRecord(SSLSocketImpl.java:1300) ~[?:1.8.0_302] at sun.security.ssl.SSLSocketImpl.startHandshake(SSLSocketImpl.java:435) ~[?:1.8.0_302] at com.mysql.cj.protocol.ExportControlled.performTlsHandshake(ExportControlled.java:347) ~[?:?] at com.mysql.cj.protocol.StandardSocketFactory.performTlsHandshake(StandardSocketFactory.java:194) ~[?:?] at com.mysql.cj.protocol.a.NativeSocketConnection.performTlsHandshake(NativeSocketConnection.java:101) ~[?:?] at com.mysql.cj.protocol.a.NativeProtocol.negotiateSSLConnection(NativeProtocol.java:308) ~[?:?] at com.mysql.cj.protocol.a.NativeAuthenticationProvider.connect(NativeAuthenticationProvider.java:204) ~[?:?] at com.mysql.cj.protocol.a.NativeProtocol.connect(NativeProtocol.java:1369) ~[?:?] at com.mysql.cj.NativeSession.connect(NativeSession.java:133) ~[?:?] at com.mysql.cj.jdbc.ConnectionImpl.connectOneTryOnly(ConnectionImpl.java:949) ~[?:?] at com.mysql.cj.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:819) ~[?:?] at com.mysql.cj.jdbc.ConnectionImpl.<init>(ConnectionImpl.java:449) ~[?:?] at com.mysql.cj.jdbc.ConnectionImpl.getInstance(ConnectionImpl.java:242) ~[?:?] at com.mysql.cj.jdbc.NonRegisteringDriver.connect(NonRegisteringDriver.java:198) ~[?:?] at org.apache.flink.connector.jdbc.internal.connection.SimpleJdbcConnectionProvider.getOrEstablishConnection(SimpleJdbcConnectionProvider.java:128) ~[?:?] at org.apache.flink.connector.jdbc.internal.AbstractJdbcOutputFormat.open(AbstractJdbcOutputFormat.java:54) ~[?:?] ... 14 moreCause
This error usually occurs when the SSL protocol is enabled for a MySQL database, but the SSL connection is incorrectly configured on the client. For example, the driver version of a MySQL database is 8.0.27 and the SSL protocol is enabled for the MySQL database. However, the default access mode of the MySQL database is not SSL. In this case, this error occurs.
Solution
We recommend that you set the connector parameter to RDS in the WITH clause and append
characterEncoding=utf-8&useSSL=falseto the URL parameter for the MySQL dimension table. Example:'url'='jdbc:mysql://***.***.***.***:3306/test?characterEncoding=utf-8&useSSL=false'
Why does the data type of the primary key in a MySQL table change from BIGINT UNSIGNED to DECIMAL when I use the MySQL table to create a catalog in the console of Realtime Compute for Apache Flink? Why does the data type of the primary key change to TEXT after I execute the CREATE TABLE AS statement to synchronize data to Hologres?
Realtime Compute for Apache Flink does not support the BIGINT UNSIGNED data type. Therefore, Realtime Compute for Apache Flink converts the data type of the primary key in the MySQL table from BIGINT UNSIGNED into DECIMAL based on the limits on the value range. When you execute the CREATE TABLE AS statement to synchronize data from MySQL to Hologres, Realtime Compute for Apache Flink automatically converts the data type of the primary key into TEXT because Hologres does not support using DECIMAL as a primary key, nor does it support the BIGINT UNSIGNED data type.
We recommend that you adjust the data type of the primary key based on the limitations during the development and design process. If you want to use the column of the DECIMAL data type, you can manually create a table in the Hologres console and configure another field as the primary key or do not specify a primary key for the table. However, this may lead to data duplication because different primary keys or a missing primary key can affect the uniqueness of the data. Therefore, you must resolve this issue at the application level. For example, you can allow a specific degree of data duplication or use the deduplication logic.
When data is written to a ApsaraDB RDS table, is a new row inserted into the table, or is the table updated based on the primary key?
If a primary key is defined in the sink table's DDL, data is written to ApsaraDB RDS using the following statement: INSERT INTO tablename(field1,field2, field3, ...) VALUES(value1, value2, value3, ...) ON DUPLICATE KEY UPDATE field1=value1,field2=value2, field3=value3, ...;. This statement inserts a new row if the primary key value does not exist. Otherwise, the existing row is updated based with the provided values. If no primary key is defined in the DDL statement, data is inserted using the INSERT INTO statement.
How do I perform GROUP BY operations by using the unique index of an ApsaraDB RDS sink table?
If you want to use the unique index of an ApsaraDB RDS sink table to perform GROUP BY operations, you must declare the unique index in the GROUP BY clause in your draft.
An ApsaraDB RDS table has only one auto-increment primary key, which cannot be declared as a primary key in the SQL draft.
Why is the INT UNSIGNED data type that is supported by MySQL physical tables, such as ApsaraDB RDS for MySQL physical tables or AnalyticDB for MySQL physical tables, declared as another data type in Flink SQL?
To ensure data precision, the Java Database Connectivity (JDBC) driver of MySQL converts the received data into a different data type based on the data type of the received data. For example, the MySQL JDBC driver converts the received data of the INT UNSIGNED type into the LONG type of MySQL. The LONG type of MySQL is mapped to the BIGINT type of Flink SQL. The MySQL JDBC driver converts the received data of the BIGINT UNSIGNED type into the BIGINTEGER type of MySQL. The BIGINTEGER type of MySQL is mapped to the DECIMAL(20, 0) type of Flink SQL.
What do I do if the "Incorrect string value: '\xF0\x9F\x98\x80\xF0\x9F...' for column 'test' at row 1" error message appears?
Description
Caused by: java.sql.BatchUpdateException: Incorrect string value: '\xF0\x9F\x98\x80\xF0\x9F...' for column 'test' at row 1 at sun.reflect.GeneratedConstructorAccessor59.newInstance(Unknown Source) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at com.mysql.cj.util.Util.handleNewInstance(Util.java:192) at com.mysql.cj.util.Util.getInstance(Util.java:167) at com.mysql.cj.util.Util.getInstance(Util.java:174) at com.mysql.cj.jdbc.exceptions.SQLError.createBatchUpdateException(SQLError.java:224) at com.mysql.cj.jdbc.ClientPreparedStatement.executeBatchedInserts(ClientPreparedStatement.java:755) at com.mysql.cj.jdbc.ClientPreparedStatement.executeBatchInternal(ClientPreparedStatement.java:426) at com.mysql.cj.jdbc.StatementImpl.executeBatch(StatementImpl.java:796) at com.alibaba.druid.pool.DruidPooledPreparedStatement.executeBatch(DruidPooledPreparedStatement.java:565) at com.alibaba.ververica.connectors.rds.sink.RdsOutputFormat.executeSql(RdsOutputFormat.java:488) ... 15 moreCause
The data contains special characters or encoding formats. As a result, the database encoding cannot be parsed as expected.
Solution
When you use a JDBC driver to connect to a MySQL database, you must add the character set UTF-8 to the JDBC URL of the MySQL database, such as
jdbc:mysql://<Internal endpoint>/<databaseName>?characterEncoding=UTF-8.
What do I do if a deadlock occurs when data is written to a MySQL database using the ApsaraDB RDS for MySQL connector or TDDL connector?
Description
When data is written to an ApsaraDB RDS for MySQL database that uses the Taobao Distributed Data Layer (TDDL) or RDS connector, a deadlock occurs.
ImportantWhen Realtime Compute for Apache Flink writes data to relational databases, such as using the TDDL or ApsaraDB RDS for MySQL connector, frequent data writes to the same table have the potential to cause deadlocks.
Example of how a deadlock occurs
For example, an INSERT operation preempts two locks (A,B) in sequence. Lock A is a range lock used for two transactions (T1,T2). The table schema is (id(Auto-increment primary key ),nid(Unique key)). T1 contains two statements insert(null,2),(null,1). T2 contains one statement insert(null,2).
At time t, the first statement in T1 is executed. T1 holds Lock A and B.
At time t+1, T2 attempts to acquire Lock A on (-inf,2] to execute a statement. However, Lock A is still held by T1 on the same range (-inf,2], preventing T2 from acquiring it. T2 will be blocked until Lock A is released by T1.
At time t+2, the second statement in T1 attempts to acquire Lock A on (-inf,1], which is included in (-inf,2]. T1's second statement will be blocked until T2 releases Lock A, which is currently held by T1 itself.
Both T1 and T2 are now blocked, creating a deadlock.
Differences in database engine locks between RDS or TDDL and Tablestore
RDS/TDDL: The row lock in InnoDB is used to lock an index rather than a record. In this case, if the same index key is used when you access records in different rows, a lock conflict may occur, and the data in the entire section cannot be updated.
Tablestore: Only a single row is locked. This does not affect the update of other data.
Solution
In scenarios with high QPS or TPS or highly concurrent write operations, use Tablestore as the result table. We recommend that you do not use TDDL or ApsaraDB RDS as the sink table for your Realtime Compute for Apache Flink deployment.
If you want to use a relational database such as ApsaraDB RDS for MySQL, take note of the following points:
Make sure that your deployment is not affected by read and write operations from other systems.
If the amount of data in your deployment is small, perform a single-concurrent write operation. In scenarios with high QPS or TPS or high concurrency, the write performance deteriorates.
Do not use a unique primary key specified by UniqueKey if possible. If you write data to a table with a unique primary key, a deadlock may occur. If the table must contain unique primary keys, sort the unique primary keys in descending order of differentiation. This significantly reduces the probability of deadlocks. For example, you can place the MD5 function at the beginning of day_time(20171010).
Shard databases and tables based on your business requirements to avoid writing data to a single table. For more information about the implementation, contact the database administrator.
Why does the destination table schema not automatically update after I change the source table schema in the upstream MySQL instance?
The synchronization of table schema changes is not triggered based on specific DDL statements but is triggered based on the schema changes between the two data records before and after the schema is changed. If only DDL statements are changed, but no data is added or modified in the source table, schema changes are not triggered in the downstream destination table. For more information, see the "Synchronization policies of table schema changes" section of the CREATE TABLE AS (CTAS) topic.
Why does the error message "finish split response timeout" appear in the source?
The source fails to respond to the RPC requests of the coordinator due to high CPU utilization of tasks. In this case, you must increase the number of CPU cores of TaskManager on the Resources tab in the console of Realtime Compute for Apache Flink.
What is the impact if the table schema changes during full data reading of a MySQL CDC table?
If the table schema changes during full data reading of a table in a deployment, the deployment may report an error or the change to the table schema cannot be synchronized. In this case, you must cancel the deployment, delete the downstream table to which data is synchronized, and then restart the deployment without states.
What do I do if data synchronization fails in a deployment due to unsupported changes to the table schema during the synchronization by using the CREATE TABLE AS or CREATE DATABASE AS statement?
You must resynchronize data of the table. In this case, you can cancel the deployment, delete the downstream table to which data is synchronized, and then restart the deployment without states. We recommend that you avoid such incompatible modifications. Otherwise, a synchronization failure is reported after the deployment is restarted. For more information about the support for changes to the table schema, see the "Synchronization policies of table schema changes" section of the CREATE TABLE AS statement topic.
Can I retract the updated data from a ClickHouse sink table?
If a primary key is specified in the DDL statement that is used to create the ClickHouse sink table of Realtime Compute for Apache Flink and the ignoreDelete parameter is set to false, you can retract the updated data. However, the data processing performance significantly decreases.
ClickHouse is a column-oriented database management system used for online analytical processing (OLAP). If you use the UPDATE and DELETE operations to process data, the performance of this system remains low. If a primary key is specified in the DDL statement, Realtime Compute for Apache Flink tries to use the ALTER TABLE UPDATE statement to update data or use the ALTER TABLE DELETE statement to delete data. As a result, the data processing performance significantly decreases.
When can I view the data that is written to a ClickHouse sink table in the ClickHouse console?
By default, the exactly-once semantics is disabled for ClickHouse sink tables. If the exactly-once semantics is disabled for a ClickHouse sink table, the system automatically writes data in the cache to the sink table after the number of data entries in the cache reaches the value specified by the batchSize parameter or the waiting time exceeds the time period that is specified by the flushIntervalMs parameter. In this case, you do not need to wait for a successful checkpoint before you can view the data that is written to the sink table in the ClickHouse console.
For a ClickHouse sink table for which the exactly-once semantics is enabled, you can view the data that is written to the sink table in the ClickHouse console only after a checkpoint is run.
How do I view print data results in the console of Realtime Compute for Apache Flink?
If you want to view print data results in the console of Realtime Compute for Apache Flink, you can use one of the following methods:
Log on to the development console of Realtime Compute for Apache Flink to view data.
In the left-side navigation pane, click .
On the Deployments page, find the deployment that you want to manage and click its name.
In the right-hand pane, click the Logs tab.
In the left side of that pane, click the Logs tab and select a running job from the Job drop-down list.
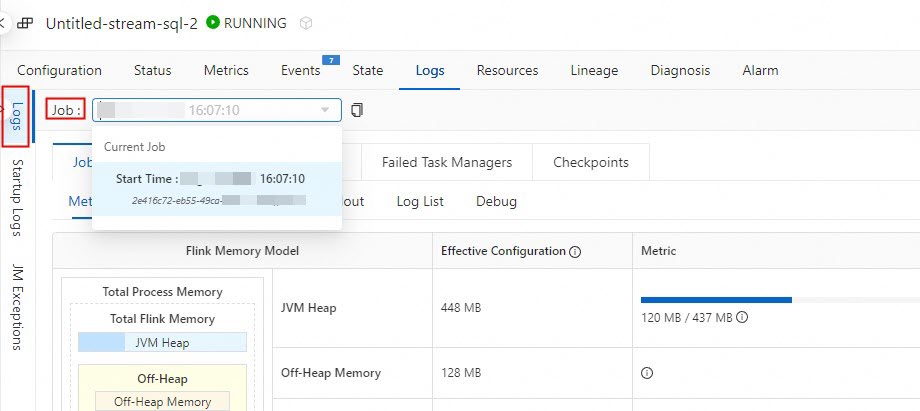
Click the Running Task Managers tab, and click the value in the Path, ID column.
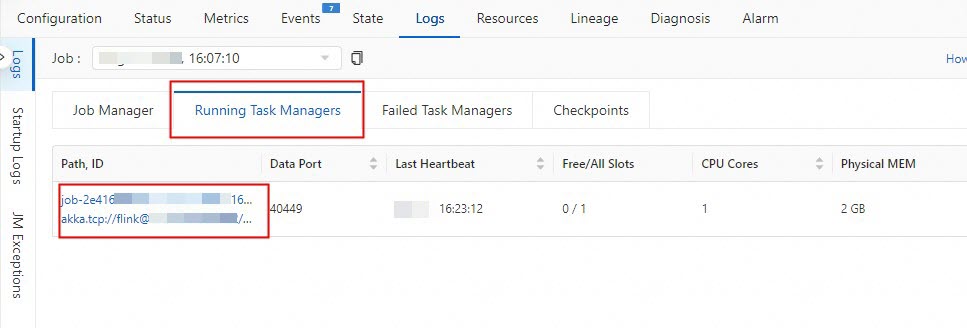
Click the Logs tab to view print data results.
Go to Flink web UI.
Log on to the development console of Realtime Compute for Apache Flink. In the left-side navigation pane of the details page of a fully managed Flink workspace, choose .
On the Deployments page, find the deployment that you want to manage and click its name.
On the Status tab, click Flink UI in the Actions field.

In the left-side navigation pane of Apache Flink Dashboard, click Task Managers.
On the Task Managers page, click the value in the Path, ID column.
Click the value in the Path, ID column. On the page that appears, click the Logs tab to view the print data results.
What do I do if no data can be found when I join a dimension table with another table?
Check whether the schema type and name in the DDL statement are the same as the schema type and name in the physical table.
What is the difference between max_pt() and max_pt_with_done()?
If the values of the partition parameter are sorted in alphabetical order, max_pt() returns the partition that ranks first in alphabetical order. If the values of the partition parameter are sorted in alphabetical order, max_pt_with_done() returns the partition that ranks first in alphabetical order and ends with the .done suffix. In this example, the following partitions are used:
ds=20190101
ds=20190101.done
ds=20190102
ds=20190102.done
ds=20190103
The following example shows the difference between max_pt() and max_pt_with_done():
`partition`='max_pt_with_done()'returns theds=20190102partition.`partition`='max_pt()'returns theds=20190103partition.
What do I do if the error message "Heartbeat of TaskManager timed out" appears when data is written to an Apache Paimon sink table in a deployment?
In most cases, the issue is caused by insufficient heap memory of the TaskManager. Apache Paimon uses heap memory in the following scenarios:
When data is written to an Apache Paimon primary key table, a memory buffer is configured for each concurrent task of the writer operator to sort table data. The size of the memory buffer is specified by the
write-buffer-sizetable parameter. The default value is 256 MB.By default, Apache Paimon files are in the Optimized Row Columnar (ORC) format. A memory buffer is required to batch convert the memory data into data in the column-oriented storage format. The size of the memory buffer is specified by the
orc.write.batch-sizetable parameter. The default value is 1024, which indicates that 1,024 rows of data are stored by default.Each bucket whose data is modified is assigned a dedicated writer object to process the data that is written to the bucket.
To handle the issue, use the relevant solution based on the following possible causes of insufficient heap memory:
The value of the
write-buffer-sizeparameter is excessively large.You can change the value of this parameter to a smaller value. An excessively small value of this parameter may cause frequent writes to disks. In this case, small files are frequently merged. This affects the write performance.
The size of a single data record is excessively large.
For example, if a data record contains a JSON field that is 4 MB in size, the ORC buffer size reaches 4 GB (4 MB × 1024). This consumes a large amount of heap memory. To resolve the issue, use one of the following methods:
Reduce the value of the
orc.write.batch-sizeparameter.If you do not need to perform ad hoc OLAP queries on an Apache Paimon sink table and only want to consume data in batch or streaming mode, add the
'file.format' = 'avro'and'metadata.stats-mode' = 'none'configurations to the table creation statement to use the Avro format and disable statistics collection.NoteYou can configure the file.format and metadata.stats-mode parameters only when you create a table. After the table is created, you cannot use the ALTER TABLE statement or SQL hints to change the values of the parameters.
An excessive number of writer objects are created because data is written to an excessive number of partitions at the same time or an excessive number of buckets are available in each partition.
You must check whether partition key columns are properly configured, whether other data is written to partition key columns due to SQL errors, and whether the number of buckets configured for each partition is excessively large. We recommend that each bucket contains approximately 2 GB to 5 GB of data. For more information about how to change the number of buckets, see the "Change the number of buckets in a fixed bucket table" section of the Primary key tables and append-only tables topic.
What do I do if the error message "Sink materializer must not be used with Paimon sink" appears when data is written to Apache Paimon in a deployment?
The Sink materializer operator is supposed to resolve the out-of-order data issue that is caused by cascaded JOIN operations in a streaming deployment. In a deployment that writes data to Apache Paimon, the use of this operator causes additional overheads and incorrect computing results during data aggregation. Therefore, the Sink materializer operator cannot be used in a deployment that writes data to Apache Paimon.
You can execute the SET statement to set the table.exec.sink.upsert-materialize parameter to false to disable the Sink materializer operator. If you want to resolve the out-of-order data issue that is caused by cascaded JOIN operations, see the "Out-of-order data handling" section of the Primary key tables and append-only tables topic.
What do I do if the "File deletion conflicts detected" or "LSM conflicts detected" error message appears when data is written to Apache Paimon in a deployment?
The error message is returned because of one of the following reasons:
Multiple deployments are run to write data to the same partition of an Apache Paimon table at the same time. You must restart the failed deployments to resolve conflicts. The occurrence of this issue is normal. If the error message does not repeatedly appear, no operation is required.
A deployment is resumed from an out-of-date state. In this case, the error message repeatedly appears. You must resume the deployment from the latest state or restart the deployment without states.
Multiple INSERT statements are used in a deployment to write data to the same Apache Paimon table. Apache Paimon does not support data writing by using multiple INSERT statements in a deployment. You can use the UNION ALL statement to write multiple data streams to the Apache Paimon table at the same time.
The parallelism of the Global Committer node or the parallelism of the Compaction Coordinator node that is required when data is written to append scalable tables is greater than 1. To ensure data consistency, the parallelism of the two nodes must be 1.
What do I do if the "File xxx not found, Possible causes" error message appears when data is read from an Apache Paimon source table in a deployment?
The data consumption of Apache Paimon tables depends on snapshot files. If the snapshot expiration time is excessively short or the consumption efficiency of a deployment is low, the snapshot files of the Apache Paimon table that is being consumed are deleted due to expiration. As a result, the error message appears.
You can adjust the expiration time of savepoint files, specify a consumer ID, or optimize data consumption. For more information about how to query available snapshot files and the time when each snapshot file was created, see the "Snapshots table" section of the System tables topic.
How do I fix the "No space left on device" error when using the Paimon connector?
For data queries (lookup joins) and data writes with
changelog-producer=lookup, configure the following parameters in SQL hints. These settings prevent cached files from consuming excessive storage:lookup.cache-max-disk-size: Limit the maximum disk usage for cache. Recommended values:256 MB,512 MB,1 GB, or higher as needed.lookup.cache-file-retention: Set the cache retention period. Recommended values: 30 minutes, 15 minutes, or less.
For general Paimon data writes, configure
write-buffer-spill.max-disk-size(maximum size of temporary files stored locally) in SQL hints. This prevents temporary files from taking up too much storage.
What do I do if a large number of Apache Paimon files are stored in OSS?
Historical data files of Apache Paimon tables are stored to support access to Apache Paimon tables in historical states. You can modify the retention policy of historical data files. For more information, see Clean up expired data.
This issue may occur if partition key columns are improperly configured or an excessive number of buckets is used. We recommend that each bucket contains approximately 2 GB to 5 GB of data. For more information about bucketing methods, see the "Bucket mode" section of the Primary key tables and append-only tables topic.
By default, data files are saved in the ORC format. You can add the
'file.compression' = 'zstd'configuration when you create a table and use the Zstandard data compression algorithm to save data files. This reduces the total size of data files.NoteThe file.compression parameter can be configured only when you create a table. After the table is created, you cannot use the ALTER TABLE statement or SQL hints to change the value of the parameter.
Does the checkpoint interval affect the visibility of data written by the Paimon connector?
The checkpoint interval affects the visibility of data written by the Paimon connector. The exactly-once semantics of Paimon is ensured based on system checkpoints. Only at each checkpoint does Paimon commit data to make the data visible to downstream systems. Before the data is committed, the data in the local buffer is flushed to the remote file system. However, the downstream system is not notified that the data can be read.
Why is memory usage gradually increasing in a long-running job that writes data to Paimon?
Memory usage in long-running jobs can increase due to two main reasons:
Expected behavior: A gradual increase in memory usage is normal if the Request Per Second (RPS) also rises.
Known memory leak: A memory leak can occur in a long-running job that uses the Paimon catalog of the filesystem metastore type. This is a known issue in Apache Flink. To resolve this memory leak issue when reading from or writing to OSS via a Paimon catalog of the filesystem metastore type, configure the following options:
fs.oss.endpoint,fs.oss.accessKeyId, andfs.oss.accessKeySecret.
What do I do if the "IllegalArgumentException: timeout value is negative" error message appears?
Error message
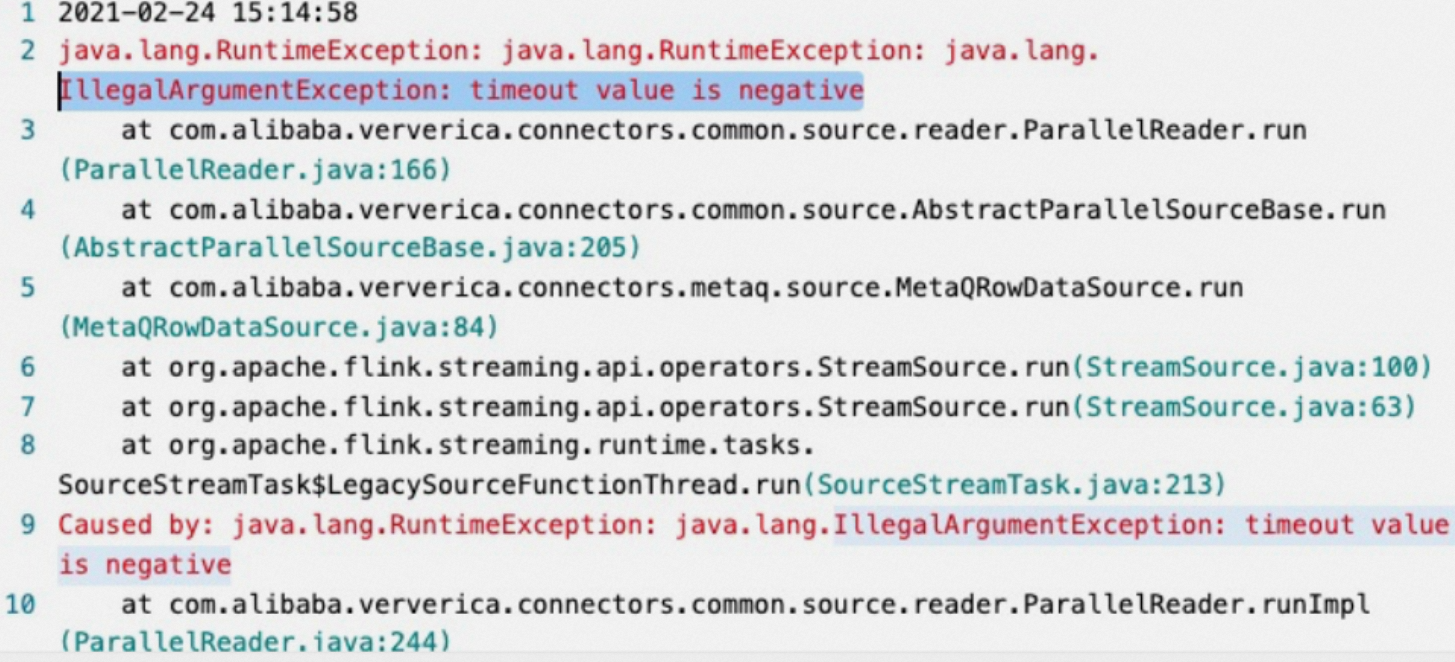
Cause
If no new ApsaraMQ messages are consumed for a period of time, the MetaQSource thread starts to hibernate. The hibernation period is specified by the pullIntervalMs parameter. However, the default value of the pullIntervalMs parameter is -1. If -1 is used as the value of the hibernation period, the error message appears.
Solution
Change the value of the pullIntervalMs parameter to a non-negative value.
How does the connector for the ApsaraMQ for RocketMQ source table learn about the change in the number of partitions in a topic when new partitions are created in the topic?
Realtime Compute for Apache Flink that uses a Ververica Runtime (VVR) version earlier than 6.0.2 obtains the current number of partitions in a topic of ApsaraMQ for RocketMQ at an interval of 5 to 10 minutes. If the number of partitions is different from the original number of partitions for three consecutive times, a deployment failover is triggered. Therefore, the connector for the ApsaraMQ for RocketMQ source table can learn about the change in the number of partitions 10 to 30 minutes after the change occurs and a deployment failover occurs. After the deployment is restarted, Realtime Compute for Apache Flink reads data from the new partitions.
Realtime Compute for Apache Flink that uses VVR 6.0.2 or later obtains the current number of partitions in a topic of Message Queue for ApsaraMQ for RocketMQ at an interval of 5 minutes. When Realtime Compute for Apache Flink detects new partitions, the source operator of a TaskManager directly reads data from the new partitions. The deployment failover is not triggered. Therefore, the connector for the ApsaraMQ for RocketMQ source table can learn about the change in the number of partitions 1 to 5 minutes after the change occurs.
What do I do if the "BackPressure Exceed reject Limit" error message appears?
Error message
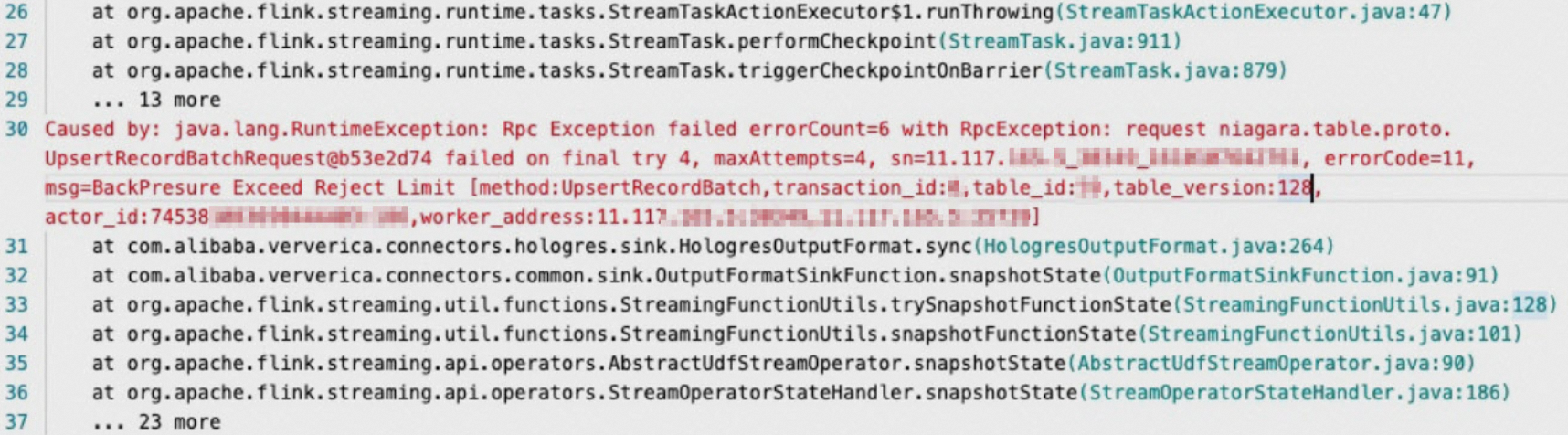
Cause
The write load in Hologres is high.
Solution
Provide the instance information to Hologres technical support engineers to perform an upgrade.
What do I do if the "remaining connection slots are reserved for non-replication superuser connections" error message appears?
Description
Caused by: com.alibaba.hologres.client.exception.HoloClientWithDetailsException: failed records 1, first:Record{schema=org.postgresql.model.TableSchema@188365, values=[f06b41455c694d24a18d0552b8b0****, com.chot.tpfymnq.meta, 2022-04-02 19:46:40.0, 28, 1, null], bitSet={0, 1, 2, 3, 4}},first err:[106]FATAL: remaining connection slots are reserved for non-replication superuser connections at com.alibaba.hologres.client.impl.Worker.handlePutAction(Worker.java:406) ~[?:?] at com.alibaba.hologres.client.impl.Worker.run(Worker.java:118) ~[?:?] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_302] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_302] ... 1 more Caused by: com.alibaba.hologres.org.postgresql.util.PSQLException: FATAL: remaining connection slots are reserved for non-replication superuser connections at com.alibaba.hologres.org.postgresql.core.v3.QueryExecutorImpl.receiveErrorResponse(QueryExecutorImpl.java:2553) ~[?:?] at com.alibaba.hologres.org.postgresql.core.v3.QueryExecutorImpl.readStartupMessages(QueryExecutorImpl.java:2665) ~[?:?] at com.alibaba.hologres.org.postgresql.core.v3.QueryExecutorImpl.<init>(QueryExecutorImpl.java:147) ~[?:?] at com.alibaba.hologres.org.postgresql.core.v3.ConnectionFactoryImpl.openConnectionImpl(ConnectionFactoryImpl.java:273) ~[?:?] at com.alibaba.hologres.org.postgresql.core.ConnectionFactory.openConnection(ConnectionFactory.java:51) ~[?:?] at com.alibaba.hologres.org.postgresql.jdbc.PgConnection.<init>(PgConnection.java:240) ~[?:?] at com.alibaba.hologres.org.postgresql.Driver.makeConnection(Driver.java:478) ~[?:?] at com.alibaba.hologres.org.postgresql.Driver.connect(Driver.java:277) ~[?:?] at java.sql.DriverManager.getConnection(DriverManager.java:674) ~[?:1.8.0_302] at java.sql.DriverManager.getConnection(DriverManager.java:217) ~[?:1.8.0_302] at com.alibaba.hologres.client.impl.ConnectionHolder.buildConnection(ConnectionHolder.java:122) ~[?:?] at com.alibaba.hologres.client.impl.ConnectionHolder.retryExecute(ConnectionHolder.java:195) ~[?:?] at com.alibaba.hologres.client.impl.ConnectionHolder.retryExecute(ConnectionHolder.java:184) ~[?:?] at com.alibaba.hologres.client.impl.Worker.doHandlePutAction(Worker.java:460) ~[?:?] at com.alibaba.hologres.client.impl.Worker.handlePutAction(Worker.java:389) ~[?:?] at com.alibaba.hologres.client.impl.Worker.run(Worker.java:118) ~[?:?] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_302] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_302] ... 1 moreCause
The number of connections exceeds the upper limit.
Solution
View app_name of the connection for each access node (Frontend, FE) and view the number of Hologres Client connections used by flink-connector.
Check whether other deployments are connecting to Hologres.
Release specific connections. For more information, see Manage connections.
What do I do if the "no table is defined in publication" error message appears?
Description
After I drop a table and recreate a table that has the same name as the dropped table, the
no table is defined in publicationerror message appears.Cause
When the table is dropped, the publication that is associated with the table is not dropped.
Solution
Run the
select * from pg_publication where pubname not in (select pubname from pg_publication_tables);command in Hologres to query the information about the publication that is not dropped when the table is dropped.Execute the
drop publication xx;statement to drop the publication that is associated with the table.Restart the deployment.
What is the relationship between the interval at which checkpoints are executed by a Hologres sink node and the visibility of Hologres data?
The interval at which checkpoints are executed by a Hologres sink node is not directly related to the visibility of Hologres data. The checkpoint interval affects the service level agreement (SLA) for data restoration but does not determine the visibility of Hologres data.
The Hologres connector does not support transactions; it only periodically flushes data to Hologres. Data is refreshed to the database every time a checkpoint is executed. The maximum period of time that a Hologres sink node waits to execute a checkpoint is not specified by the checkpoint interval. If the buffer meets specified conditions, data is written to the downstream storage before the next checkpoint. For more information, see the descriptions of the Hologres, Hologres, and Hologres parameters in the "Hologres connector" topic. In most cases, Hologres does not ensure transactional consistency. The Hologres connector refreshes data asynchronously in the background. At checkpoints, data is forcefully flushed for fault tolerance and recovery.
How do I fix the "permission denied for database" exception when launching a job?
Cause
In VVR 8.0.4 or later, Realtime Compute for Apache Flink forcibly uses JDBC mode to consume binary log data from Hologres V2.0 or later. This mode requires specific permissions on non-superuser users.
Solution
Depending on your Hologres instance's permission model, grant the following permissions to non-superuser users:
Standard PostgreSQL authorization model
-- Grant the CREATE permission and assign Replication Role to users. GRANT CREATE ON DATABASE <db_name> TO <user_name>; alter role <user_name> replication;SPM
/* In the simple permission model (SPM), use call spm_grant to grant <db>_admin permissions to users. Alternatively, use the HoloWeb console for authorization. Also, assign Replication Role to users.*/ call spm_grant('<db_name>_admin', '<user_name>'); alter role <user_name> replication;Replace
user_namewith your Alibaba Cloud account ID or RAM username. For more information, see Account overview in the Hologres documentation.
How do I fix the "table id parsed from checkpoint is different from the current table id" exception during checkpoint recovery?
In VVR 8.0.5 to 8.0.8, during checkpoint recovery of a job that reads binary logs from Hologres, Realtime Compute for Apache Flink forcibly verifies the consistency between the table ID with checkpoint information. If they do not match, the job cannot be recovered from the checkpoint. This exception indicates that users have rebuilt the Hologres table using commands such as TRUNCATE.
Solution
Upgrade to VVR 8.0.9 or later to disable table ID verification.
Avoid any operation that rebuilds the source table, as this leads to the removal of the original table's historical binary logs. When Realtime Compute for Apache Flink tries to read binary logs from the new table using the original table's offset, unexpected issues such as data inconsistency may occur.
How do I deal with data precision mismatch when reading binary logs in JDBC mode?
Cause
In a job that uses VVR 8.0.10 or earlier, the decimal field's precision defined for the Flink source table does not match that of the Hologres table.
Solution
Upgrade to VVR 8.0.11 or later.
Ensure the decimal fields' precision for the Flink and Hologres tables are consistent, which prevents data losses caused by precision loss.
How do I fix the "no table is defined in publication" or "The table xxx has no slot named xxx" exception when creating a table with the same name as a dropped table?
Cause
The publication associated with the dropped table has not been deleted.
Solutions
Solution 1:
Query the relevant publication:
select * from pg_publication where pubname not in (select pubname from pg_publication_tables);Drop the publication:
drop publication <publicationName>;Restart the job.
Solution 2:
Upgrade to VVR 8.0.5 or later, and the connector automatically cleans the publication.
What do I do if the "Caused by: com.aliyun.openservices.aliyun.log.producer.errors.LogSizeTooLargeException: the logs is 8785684 bytes which is larger than MAX_BATCH_SIZE_IN_BYTES 8388608" error message appears?
Description
Caused by: com.aliyun.openservices.aliyun.log.producer.errors.LogSizeTooLargeException: the logs is 8785684 bytes which is larger than MAX_BATCH_SIZE_IN_BYTES 8388608 at com.aliyun.openservices.aliyun.log.producer.internals.LogAccumulator.ensureValidLogSize(LogAccumulator.java:249) at com.aliyun.openservices.aliyun.log.producer.internals.LogAccumulator.doAppend(LogAccumulator.java:103) at com.aliyun.openservices.aliyun.log.producer.internals.LogAccumulator.append(LogAccumulator.java:84) at com.aliyun.openservices.aliyun.log.producer.LogProducer.send(LogProducer.java:385) at com.aliyun.openservices.aliyun.log.producer.LogProducer.send(LogProducer.java:308) at com.aliyun.openservices.aliyun.log.producer.LogProducer.send(LogProducer.java:211) at com.alibaba.ververica.connectors.sls.sink.SLSOutputFormat.writeRecord(SLSOutputFo rmat.java:100)Cause
A single row of log data that is written to Simple Log Service exceeds 8 MB. As a result, no more data can be written to Simple Log Service.
Solution
Change the start offset to skip ultra-large abnormal data. For more information, see Start a job deployment.
What do I do if an OOM error occurs in TaskManagers and the "java.lang.OutOfMemoryError: Java heap space" error message appears for the source table when I restore a failed Flink program?
Cause
In most cases, this issue occurs because the message body of Simple Log Service is excessively large. The Simple Log Service connector is used to request data in batches. The number of log groups is determined by the batchGetSize parameter. The default value of this parameter is 100. Therefore, Flink can receive data of a maximum of 100 log groups each time. When Flink runs as expected, Flink consumes data in a timely manner and does not receive data of 100 log groups. However, if a failover occurs, a large amount of data that is not consumed is accumulated. If the single log group memory multiplied by 100 is greater than the available memory for JVM, an OOM error occurs in TaskManagers.
Solution
Decrease the value of the batchGetSize parameter.
How do I specify a consumer offset for an Apache Paimon source table?
You can configure the scan.mode parameter to specify the consumer offset for an Apache Paimon source table. The following table describes the scan modes supported by Apache Paimon source tables and the related behavior.
Scan mode | Batch read behavior | Streaming read behavior |
default | The default scan mode. The actual behavior is determined by other parameters.
If neither of the preceding parameters is configured, the actual behavior is the same as the behavior in latest-full scan mode. | |
latest-full | Produces the most recent snapshot of the table. | Produces the most recent snapshot of the table upon the startup of a deployment, and continuously produces incremental data. |
compacted-full | Produces the snapshot of the table after the most recent full compaction is performed. | Produces the snapshot of the table upon the startup of a deployment after the most recent full compaction is performed, and continuously produces incremental data. |
latest | Triggers the same behavior as latest-full. | Continuously produces incremental data without producing the most recent snapshot of the table upon the startup of a deployment. |
from-timestamp | Produces the most recent snapshot that is generated earlier than or at the timestamp specified by the | Continuously produces incremental data that is read starting from the timestamp specified by the |
from-snapshot | Produces a snapshot of the table. The snapshot is specified by the | Continuously produces incremental data that is read starting from the snapshot specified by the |
from-snapshot-full | Triggers the same behavior as from-snapshot. | Produces a snapshot of the table upon the startup of a deployment and continuously produces incremental data that is read later than the time the snapshot is generated. The snapshot is specified by the |
How do I configure automatic partition expiration?
Apache Paimon tables support the automatic deletion of partitions that exist for a period of time longer than the specified validity period of a partition. This helps reduce storage costs. The details are as follows:
Period of time for which a partition exists: The value is obtained based on the difference between the current system time and the timestamp of the converted partition value. The timestamp of the converted partition value is obtained based on the following rules:
The
partition.timestamp-patternparameter specifies a pattern to convert a partition value into a time string.Each partition key column in the value of this parameter is represented by a dollar sign ($) and a column name. For example, a partition contains four partition key columns year, month, day, and hour, and the pattern is
$year-$month-$day $hour:00:00. The partitionyear=2023,month=04,day=21,hour=17is converted into the time string2023-04-21 17:00:00based on the pattern.The
partition.timestamp-formatterparameter specifies a pattern to convert a time string into a timestamp.If this parameter is not configured, the pattern
yyyy-MM-dd HH:mm:ssoryyyy-MM-ddis used by default. All patterns that are compatible with DateTimeFormatter of Java can be used.
Partition expiration time: The value is specified by the
partition.expiration-timeparameter.
What do I do if no data is found in the storage?
If data is not flushed, this issue is normal because the writer of Flink flushes data to disks based on the following policies:
A bucket reaches a specific size in memory. The default threshold is 64 MB.
The total buffer size reaches a specific value. The default threshold is 1 GB.
All data in memory is flushed out when checkpointing is triggered.
If a streaming write operation is performed, make sure that checkpointing is enabled.
What do I do if duplicate data exists?
To deduplicate data during a copy-on-write (COW) operation, you must set
write.insert.drop.duplicatestotrue.By default, deduplication is not performed on the first file in each bucket during the COW operation. Only incremental data is deduplicated. If you want to enable global deduplication, you must set
write.insert.drop.duplicatestotrue. If you perform a merge-on-read (MOR) operation, global deduplication is automatically enabled after you define a primary key. You do not need to enable a flag parameter.NoteIn Hudi 0.10.0 and later,
write.insert.drop.duplicatesis renamed towrite.precombinedand defaults totrue.To enable deduplication across partitions, you must set
index.global.enabledtotrue.NoteIn Hudi 0.10.0 and later, the default value of
index.global.enabledistrue.The bucket index does not support cross-partition changes. Therefore, when both
index.type=bucketandindex.global.enabled=trueare configured, deduplication will not be performed across partitions.
If you want to update data that was generated a long period of time ago, such as one month, you must increase the value of the index.state.ttl parameter. The unit of this parameter is days.
The index is the core data structure that is used to determine data duplication. The index.state.ttl parameter is used to specify the number of days for which the index can be saved. The default value is 1.5. If you set this parameter to a value less than 0, the index is permanently stored.
NoteIn Hudi 0.10.0 and later, the default value of the index.state.ttl parameter is 0.
Why are only log files generated in MOR mode?
Cause: Hudi generates Parquet files only after data is compacted. If data is not compacted, only log files are generated. By default, asynchronous compaction is enabled in MOR mode, and data is compacted at an interval of five commits. A compaction task is triggered only when the compaction interval condition is met.
Solution: Decrease the value of the compaction.delta_commits parameter to shorten the compaction interval and accelerate the trigger of a compaction task.
What do I do if the "multi-statement be found." error message appears?
Description
A deployment that writes data to AnalyticDB for MySQL unexpectedly restarts, reporting this error:
Caused by: java.sql.SQLSyntaxErrorException: [13000, 2024101216171419216823505703151806929] multi-statement be found.
Cause
ALLOW_MULTI_QUERIES=trueis configured for the AnalyticDB for MySQL database that uses the MySQL JDBC driver of the 8.x version, resulting in a compatibility issue.Solution
Contact technical support for a custom AnalyticDB for MySQL V3.0 connector of the MySQL JDBC driver package 5.1.46. For more information about how to use custom connectors, see Manage custom connectors.
Set the
allowMultiQueriesparameter to true for the JDBC URL of the AnalyticDB for MySQL database. For example, you can add the following configuration:jdbc:mysql://xxxxx.ads.aliyuncs.com:3306/xxx?allowMultiQueries=true'.
How do I fix "Error: No suitable driver found for..."?
Cause
The custom connector cannot locate its required driver.
Solution
Load the driver in your factory class in advance using
Class.forName.Add the driver JAR to your additional dependencies and set the
kubernetes.application-mode.classpath.include-user-jar: trueparameter. For instructions on adding parameters, see How do I configure custom parameters for deployment running?