PASE is no longer maintained. Use the pgvector extension instead. For details, see Use the pgvector extension to perform high-dimensional vector similarity searches.
PASE (PostgreSQL ANN search extension) adds approximate nearest neighbor (ANN) vector search to ApsaraDB RDS for PostgreSQL using two index algorithms: IVFFlat and Hierarchical Navigable Small World (HNSW).
PASE performs similarity search on existing vectors. It does not extract or generate feature vectors — you must provide them.
Prerequisites
Before you begin, make sure you have:
An ApsaraDB RDS for PostgreSQL instance running PostgreSQL 11 or later (PostgreSQL 17 is not supported)
A privileged account for running the SQL statements in this topic
Choose an index algorithm
Both algorithms trade build time and memory against query recall. Use this table to decide:
| IVFFlat | HNSW | |
|---|---|---|
| How it works | Partitions vectors into clusters; queries a subset of clusters near the target | Builds a multi-layer proximity graph; traverses from coarse layers down to fine |
| Best for | High-precision queries where latency up to 100 ms is acceptable | Large datasets (tens of millions of vectors) where responses must arrive within 10 ms |
| 100% recall possible? | Yes, when the query vector is in the candidate dataset | Precision plateaus after a certain level and cannot be increased by tuning parameters alone |
| Build time | Fast | Slow |
| Storage | Low | Higher (stores proximity graph neighbors) |
| Data required before indexing? | Yes, when using internal clustering (clustering_type = 1) — requires data for the k-means training step | No |
Use IVFFlat for image comparison and other high-precision workloads where some query latency is acceptable.
Use HNSW for recommendation systems and semantic search at scale, where low latency matters more than perfect recall.
How it works
IVFFlat
IVFFlat is a simplified version of the IVFADC algorithm.
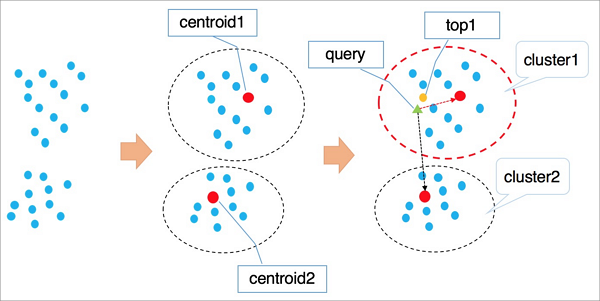
IVFFlat uses k-means to divide vectors into clusters. Each cluster has a centroid.
It finds the
ncentroids nearest to the query vector.It searches all vectors in those
nclusters and returns theknearest results.
Skipping distant clusters speeds up the query but can reduce recall — vectors similar to the query may fall outside the selected clusters. A larger n improves recall at the cost of more computation.
IVFFlat differs from IVFADC in the second phase. IVFADC uses product quantization to skip brute-force traversal, which is faster but less precise. IVFFlat uses brute-force search within the selected clusters, giving you direct control over the precision–speed tradeoff.
HNSW
HNSW is a graph-based ANN algorithm.
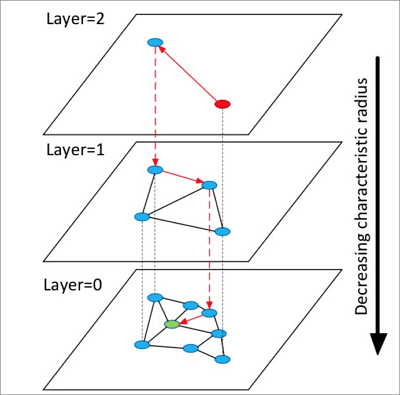
HNSW builds a hierarchical structure of layers (graphs). Each layer is a coarser view of the layer below it.
A search starts at a random element in the top layer.
HNSW finds the neighbors of the current element, adds them to a fixed-length candidate list sorted by distance, and continues expanding neighbors. When the list stabilizes, the top element becomes the entry point for the next layer down.
This repeats until the bottom layer is searched.
HNSW uses the Navigable Small World (NSW) algorithm — originally designed for single-layer graphs — to construct each layer, enabling faster traversal than clustering-based methods.
Background knowledge of machine learning and ANN search algorithms is assumed throughout this topic.
Set up PASE
Step 1: Enable the extension
CREATE EXTENSION pase;Step 2: Calculate vector similarity (optional quick test)
Use the <?> operator to compute similarity between two vectors before creating an index.
PASE-type construction:
SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[]) AS distance;
SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[], 0) AS distance;
SELECT ARRAY[2, 1, 1]::float4[] <?> pase(ARRAY[3, 1, 1]::float4[], 0, 1) AS distance;String-based construction:
SELECT ARRAY[2, 1, 1]::float4[] <?> '3,1,1'::pase AS distance;
SELECT ARRAY[2, 1, 1]::float4[] <?> '3,1,1:0'::pase AS distance;
SELECT ARRAY[2, 1, 1]::float4[] <?> '3,1,1:0:1'::pase AS distance;The <?> operator takes a float4[] on the left and a PASE value on the right. Both vectors must have the same number of dimensions, or PASE returns a similarity calculation error.
In the PASE constructor (float4[], second_param, similarity_method):
Second parameter: reserved; set to
0Similarity method:
0= Euclidean distance,1= dot product (also called inner product)
If using the dot product or cosine similarity method, normalize the input vectors first. A normalized vector satisfiessuch that
. For a normalized vector, the dot product equals the cosine value. ApsaraDB RDS for PostgreSQL supports the Euclidean distance method directly; use the dot product method only after normalizing vectors.
Step 3: Create an index
IVFFlat index
CREATE INDEX ivfflat_idx ON table_name
USING
pase_ivfflat(column_name)
WITH
(clustering_type = 1, distance_type = 0, dimension = 256, base64_encoded = 0, clustering_params = "10,100");Parameters:
| Parameter | Required | Default | Description |
|---|---|---|---|
clustering_type | Yes | — | Clustering method. 0 = external (loads a centroid file specified by clustering_params). 1 = internal k-means. Start with 1 if you are new to PASE. |
distance_type | No | 0 | Similarity method. 0 = Euclidean distance. 1 = dot product (requires normalized vectors; dot product order is opposite to Euclidean order). ApsaraDB RDS for PostgreSQL supports only Euclidean distance directly. |
dimension | Yes | — | Number of vector dimensions. Maximum: 512. |
base64_encoded | No | 0 | Vector encoding. 0 = float4[]. 1 = Base64-encoded float[]. |
clustering_params | Yes | — | For internal clustering (clustering_type = 1): "sampling_ratio,k". sampling_ratio is the sampling fraction with 1000 as the denominator, range (0, 1000] — a value of 1 samples at a 1:1000 ratio before running k-means; keep total sampled records under 100,000. k is the number of centroids; use a value in [100, 1000]. For external clustering (clustering_type = 0): the directory path of the centroid file. |
HNSW index
CREATE INDEX hnsw_idx ON table_name
USING
pase_hnsw(column_name)
WITH
(dim = 256, base_nb_num = 16, ef_build = 40, ef_search = 200, base64_encoded = 0);Parameters:
| Parameter | Required | Valid values | Description |
|---|---|---|---|
dim | Yes | [8, 512] | Number of vector dimensions. |
base_nb_num | Yes | Recommended: [16, 128] | Number of neighbors stored per element. Higher values improve recall but increase build time and storage. |
ef_build | Yes | Recommended: [40, 400] | Candidate heap size during index construction. Higher values improve recall but slow down builds. |
ef_search | Yes | [10, 400] | Candidate heap size during queries. Higher values improve recall but reduce query throughput. |
base64_encoded | No | 0 or 1 | Vector encoding. 0 = float4[]. 1 = Base64-encoded float[]. |
Step 4: Query vectors
IVFFlat query
Use the <#> operator and include ORDER BY — the index only takes effect with ORDER BY.
SELECT id, vector <#> '1,1,1'::pase AS distance
FROM table_name
ORDER BY
vector <#> '1,1,1:10:0'::pase
ASC LIMIT 10;The query string format is vector:n:similarity_method:
`n`: number of clusters to search, range
(0, 1000]. Higher values improve recall at the cost of speed. Tune based on your recall and latency requirements.`similarity_method`:
0= Euclidean distance,1= dot product (requires normalized vectors).
HNSW query
Use the <?> operator and include ORDER BY.
SELECT id, vector <?> '1,1,1'::pase AS distance
FROM table_name
ORDER BY
vector <?> '1,1,1:100:0'::pase
ASC LIMIT 10;The query string format is vector:ef:similarity_method:
`ef`: candidate heap size during the query, range
(0, ∞). Start at40and increase in small steps until you find the right balance for your workload.`similarity_method`:
0= Euclidean distance,1= dot product (requires normalized vectors).
Usage notes
Index bloat: Check index size with
SELECT pg_relation_size('index_name');and compare it to the table size. If the index is larger than the table and queries have slowed down, rebuild the index.Accuracy drift after updates: Frequent data updates can cause the index to become stale. If 100% recall is required, rebuild the index on a regular schedule.
Creating an IVFFlat index with internal centroids: Set
clustering_type = 1and make sure the table already contains data before creating the index.
Example: IVFFlat end-to-end
This example creates a table, loads 3-dimensional vectors, builds an IVFFlat index, and runs a nearest-neighbor query.
-- Step 1: Enable the extension
CREATE EXTENSION pase;
-- Step 2: Create the table
CREATE TABLE vectors_table (
id SERIAL PRIMARY KEY,
vector float4[] NOT NULL
);
-- Step 3: Insert sample data
INSERT INTO vectors_table (vector) VALUES
('{1.0, 0.0, 0.0}'),
('{0.0, 1.0, 0.0}'),
('{0.0, 0.0, 1.0}'),
('{0.0, 0.5, 0.0}'),
('{0.0, 0.5, 0.0}'),
('{0.0, 0.6, 0.0}'),
('{0.0, 0.7, 0.0}'),
('{0.0, 0.8, 0.0}'),
('{0.0, 0.0, 0.0}');
-- Step 4: Build the IVFFlat index
CREATE INDEX ivfflat_idx ON vectors_table
USING
pase_ivfflat(vector)
WITH
(clustering_type = 1, distance_type = 0, dimension = 3, base64_encoded = 0, clustering_params = "10,100");
-- Step 5: Query the 10 nearest neighbors to [1, 1, 1]
SELECT id, vector <#> '1,1,1'::pase AS distance
FROM vectors_table
ORDER BY
vector <#> '1,1,1:10:0'::pase
ASC LIMIT 10;Appendix
Calculate dot product or cosine similarity
The dot product of a normalized vector equals its cosine value. This function uses an HNSW index to retrieve the top-k results by dot product:
CREATE OR REPLACE FUNCTION inner_product_search(
query_vector text,
ef integer,
k integer,
table_name text
)
RETURNS TABLE (id integer, uid text, distance float4) AS $$
BEGIN
RETURN QUERY EXECUTE format('
SELECT a.id, a.vector <?> pase(ARRAY[%s], %s, 1) AS distance
FROM (
SELECT id, vector
FROM %s
ORDER BY vector <?> pase(ARRAY[%s], %s, 0) ASC
LIMIT %s
) a
ORDER BY distance DESC;',
query_vector, ef, table_name, query_vector, ef, k
);
END
$$ LANGUAGE plpgsql;Use an external centroid file for IVFFlat
This is an advanced option. Upload an external centroid file to the server directory, then reference it in clustering_params when clustering_type = 0. The file format is:
Number of dimensions|Number of centroids|Centroid vector datasetExample:
3|2|1,1,1,2,2,2References
Product Quantization for Nearest Neighbor Search — Hervé Jégou, Matthijs Douze, Cordelia Schmid
Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs — Yu.A. Malkov, D.A. Yashunin