PolarDB is a cloud-native relational database by Alibaba Cloud. Built on a storage-compute decoupled architecture, it combines software and hardware optimization to deliver high performance, high availability, security, mass storage, and second-level elasticity. PolarDB is 100% compatible with MySQL and PostgreSQL, highly compatible with Oracle syntax, and supports centralized and distributed deployments. Compared to self-managed databases, PolarDB delivers up to 6x transaction performance and 400x analytical performance at 50% of the total cost of ownership (TCO).
Choose the PolarDB engine that fits your application — each maintains full ecosystem compatibility.
|
PolarDB database |
Ecosystem compatibility |
Service architecture |
Product form |
|
100% compatible with MySQL |
Shared storage, compute-storage decoupled |
Public cloud, Apsara Stack Enterprise Edition, DBStack |
|
|
100% compatible with PostgreSQL, highly compatible with Oracle syntax |
|||
|
Shared-nothing, integrated centralized and distributed architecture |
Benefits
|
Ecosystem compatibility
|
High performance
|
High availability
|
|
Mass storage
|
Easy to scale
|
Security
|
Service architecture
PolarDB for MySQL
PolarDB for MySQL uses a cloud-native, storage-compute decoupled architecture that combines commercial-grade stability, performance, and scalability with open-source simplicity and rapid iteration.
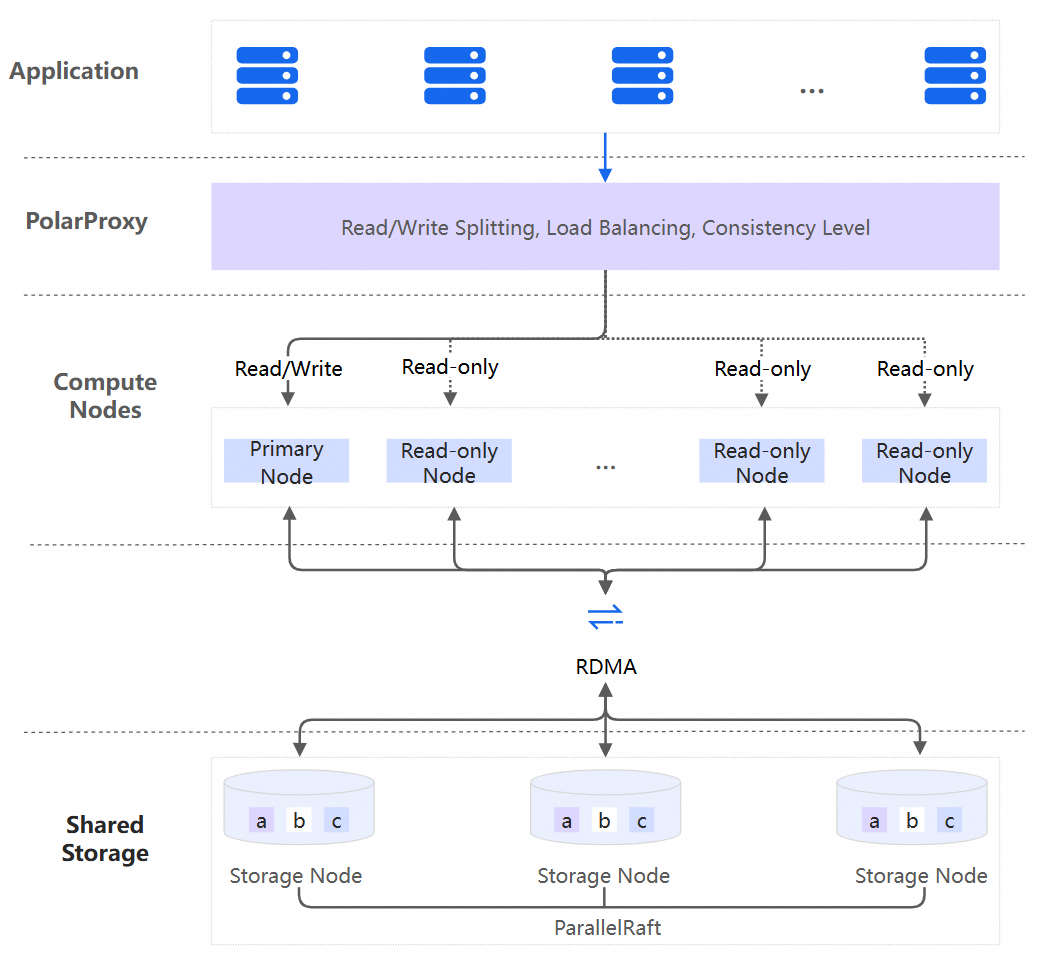
-
Database proxy (Proxy)
A network proxy between applications and the database. Provides security authentication, automatic read/write splitting, load balancing, consistency levels, connection pools, persistent connections, and overload protection.
-
Database compute nodes
-
PolarDB uses a multi-node cluster architecture. A Cluster Edition cluster contains one read/write node and multiple read-only nodes. A Multi-master Cluster contains multiple read/write nodes and multiple read-only nodes.
-
Read/write nodes and read-only nodes use active-active failover to provide high database availability.
-
Compute nodes provide the SQL engine feature and are available in General-purpose and Dedicated specifications.
-
-
Shared distributed storage
Multiple compute nodes share a single data copy, reducing storage costs. Built on a distributed block storage and file system, capacity scales online to hundreds of terabytes.
PolarDB for PostgreSQL
PolarDB for PostgreSQL clusters support centralized and distributed deployments:
-
Centralized
Built on a cloud-native, storage-compute decoupled architecture, it combines commercial-grade stability and performance with open-source simplicity and rapid iteration.
-
Distributed
A distributed database built on centralized PolarDB for PostgreSQL clusters. Uses a two-layer CN/DN architecture for distributed scalability with storage-compute decoupling, while retaining all centralized cluster features.
|
Centralized (Enterprise and Standard Editions)
|
Distributed
|

PolarDB Distributed Edition
In a PolarDB for X-Engine cluster, storage nodes (DNs) start as a centralized deployment 100% compatible with MySQL 5.7 and 8.0. When you need distributed scaling, upgrade in place — distributed components connect to existing storage nodes without data migration or application changes.
|
Centralized (Standard Edition)
|
Distributed (Enterprise Edition)
|


Video introduction
How to use PolarDB
Manage PolarDB clusters, databases, and accounts through:
Quick start
|
PolarDB database |
Billing |
Operation Guides |
Whitepapers |