In a distributed database, running computations at the coordinator layer means fetching raw data across the network before processing it — which is slow. PolarDB-X 1.0 uses pushdown to move operator execution as close to the data as possible: filters, aggregations, sorts, joins, and subqueries run inside each MySQL shard, so only reduced, pre-processed results travel over the network.
To inspect how the optimizer rewrites a specific query, run:
EXPLAIN OPTIMIZER <your_sql>;The following operator types support pushdown:
| Operator type | Examples |
|---|---|
| Filter | WHERE, HAVING conditions |
| Project | Column selection |
| Sort | ORDER BY |
| Limit | LIMIT |
| Agg | COUNT, GROUP BY |
| JOIN | Inner join, outer join |
| Subquery | IN, EXISTS subqueries |
| Function | NOW() and similar functions |
| Deduplication | DISTINCT |
Each section below explains how the optimizer pushes that operator to LogicalView — the operator that represents the MySQL storage layer in the execution plan — and when pushdown does not apply.
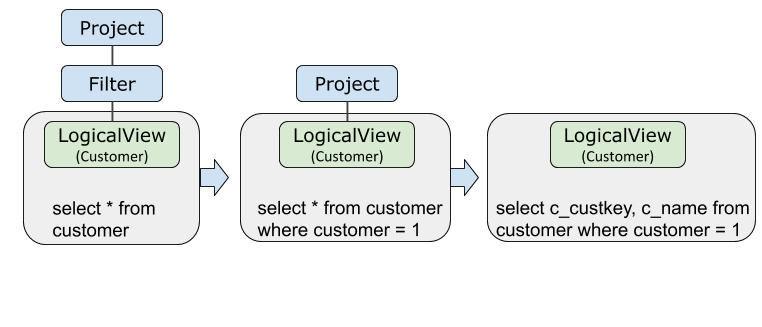
Project and Filter pushdown
When a query includes a filter on the shard key, the optimizer pushes both the Filter and Project operators down to LogicalView. The storage layer discards rows and drops unused columns before sending any data to the coordinator, cutting network transmission.
EXPLAIN OPTIMIZER SELECT c_custkey, c_name FROM customer WHERE c_custkey = 1;c_custkey is the shard key of customer. Because the filter is on the shard key, the optimizer evaluates the condition entirely at the storage layer.
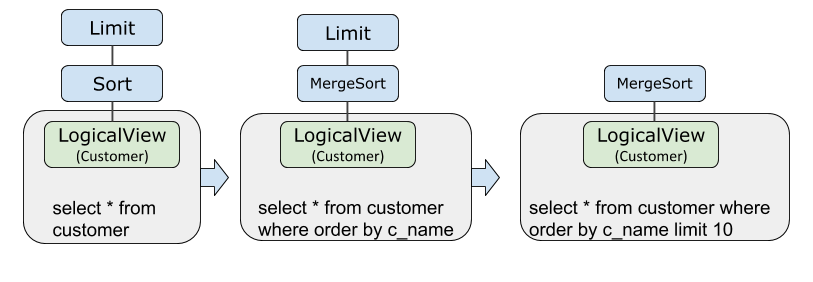
Limit and Sort pushdown
The optimizer pushes Sort and Limit together to LogicalView. Each shard sorts and limits its own rows locally, so the coordinator receives pre-sorted, pre-filtered rows rather than raw data.
EXPLAIN OPTIMIZER SELECT * FROM customer ORDER BY c_custkey LIMIT 10;This reduces network transmission, enables parallel sorting across shards, and lowers memory usage at the coordinator layer.
Agg pushdown
The optimizer pushes the Agg operator to LogicalView so that each shard computes a partial aggregate locally. The coordinator then merges partial results instead of raw rows, reducing both network transmission and coordinator memory usage.
EXPLAIN OPTIMIZER SELECT COUNT(*) FROM customer GROUP BY c_nationkey;The execution plan differs depending on whether c_nationkey is the shard key:
When c_nationkey is the shard key:

When c_nationkey is not the shard key:

JOIN pushdown
JOIN pushdown brings the join computation to the storage layer, enabling parallel execution across shards. Both of the following conditions must be met:
-
Tables t1 and t2 use the same sharding method — identical database sharding keys, table sharding keys, sharding functions, and shard count.
-
The JOIN condition includes an equivalence predicate between the shard keys of t1 and t2.
When both conditions hold, the optimizer pushes the JOIN operator to LogicalView.
EXPLAIN OPTIMIZER SELECT * FROM t1, t2 WHERE t1.id = t2.id;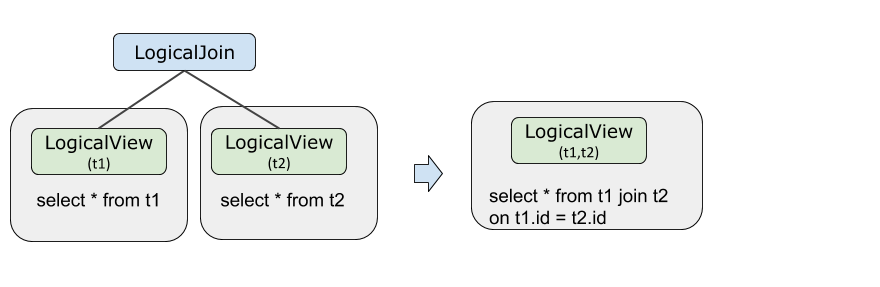
A JOIN between any table and a broadcast table is always pushed down, regardless of sharding method, because broadcast tables replicate their data to every shard.
JoinClustering
When a query joins three or more tables, not all pairs may meet the pushdown conditions. JoinClustering reorders the JOIN sequence to place pushdown-eligible pairs in adjacent positions, maximizing the number of JOINs that execute at the storage layer.
EXPLAIN SELECT t2.id FROM t2 JOIN t1 ON t2.id = t1.id JOIN l2 ON t1.id = l2.id;The original join order is t2 → t1 → l2. After JoinClustering, t2 and l2 are placed adjacent because they share the same sharding method, so their join is pushed down to LogicalView together:
Project(id="id")
HashJoin(condition="id = id AND id = id0", type="inner")
Gather(concurrent=true)
LogicalView(tables="t2_[0-3],l2_[0-3]", shardCount=4, sql="SELECT `t2`.`id`, `l2`.`id` AS `id0` FROM `t2` AS `t2` INNER JOIN `l2` AS `l2` ON (`t2`.`id` = `l2`.`id`) WHERE (`t2`.`id` = `l2`.`id`)")
Gather(concurrent=true)
LogicalView(tables="t1", shardCount=2, sql="SELECT `id` FROM `t1` AS `t1`")The t2–l2 join runs inside each shard in parallel. The remaining HashJoin with t1 runs at the coordinator layer, because t1 uses a different sharding method.
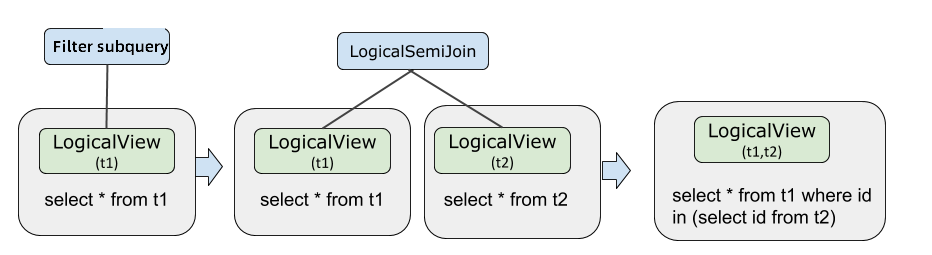
Subquery pushdown
Subquery pushdown brings subquery execution to the storage layer, enabling parallel evaluation alongside the outer query.
The optimizer uses a three-step process:
-
Convert the subquery to
Semi JoinorAnti Join. -
Apply the JOIN pushdown conditions. If both conditions are met, push
Semi JoinorAnti JointoLogicalView. -
Restore the pushed-down operator back to subquery form in the final execution plan.
EXPLAIN OPTIMIZER SELECT * FROM t1 WHERE id IN (SELECT id FROM t2);