When a partitioned table uses a column with uneven value distribution as the partition key, one partition can accumulate disproportionately more data than others. This imbalance—called a hot data partition—concentrates read/write load on a single storage node and degrades overall query performance. This topic explains how PolarDB-X resolves this problem by splitting a hot data partition into multiple smaller partitions.
How it works
How hot data partitions form
PolarDB-X distributes partitions across storage nodes as evenly as possible. In a HASH partitioned table, the consistent hashing algorithm maps each partition key value to a hash value, which determines the partition where the data resides.
Consider an orders table where the primary key is an auto-increment id column:
CREATE TABLE orders (
id int(11) NOT NULL AUTO_INCREMENT,
seller_id int(11) DEFAULT NULL,
PRIMARY KEY (id)
)If you partition this table by id using HASH partitioning, data is evenly distributed. However, queries typically filter by seller_id, not id. Without partition pruning on seller_id, every query must scan all partitions.
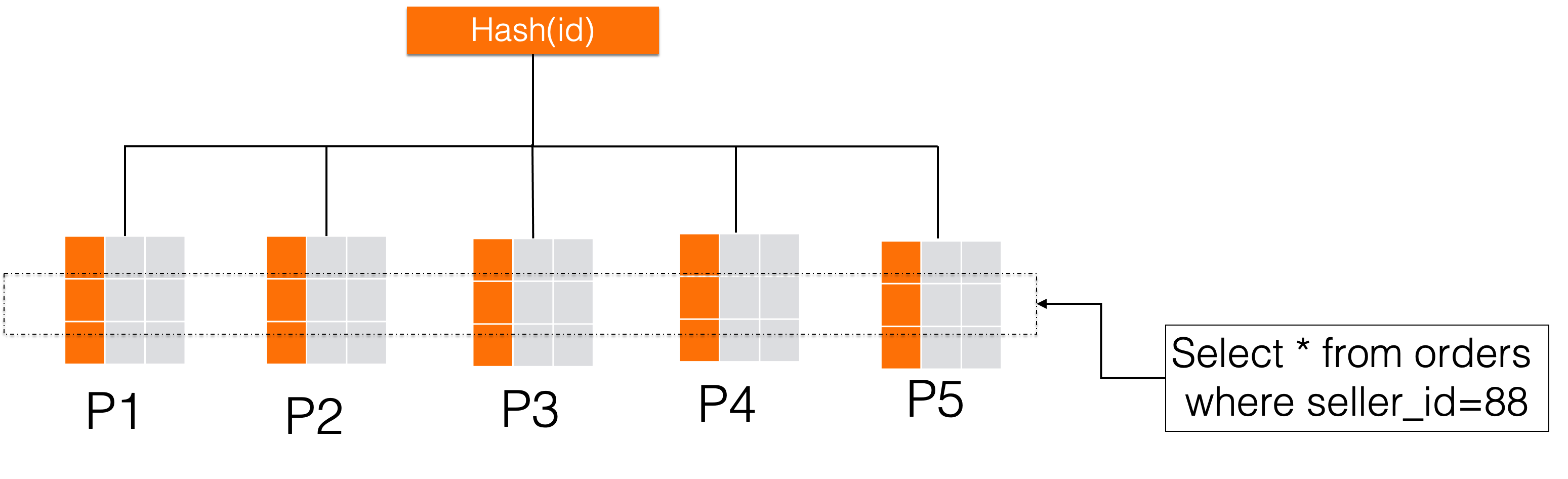
If you instead partition by seller_id, the optimizer can apply partition pruning and skip most partitions on each query. The trade-off: all rows for the same seller land in the same partition. For high-volume sellers (commonly called "big sellers"), this creates a hot data partition.
For example, if seller 88 has a large number of orders, all of that seller's data goes to partition P5—making P5 a hot data partition.
Why a single partition key cannot be split
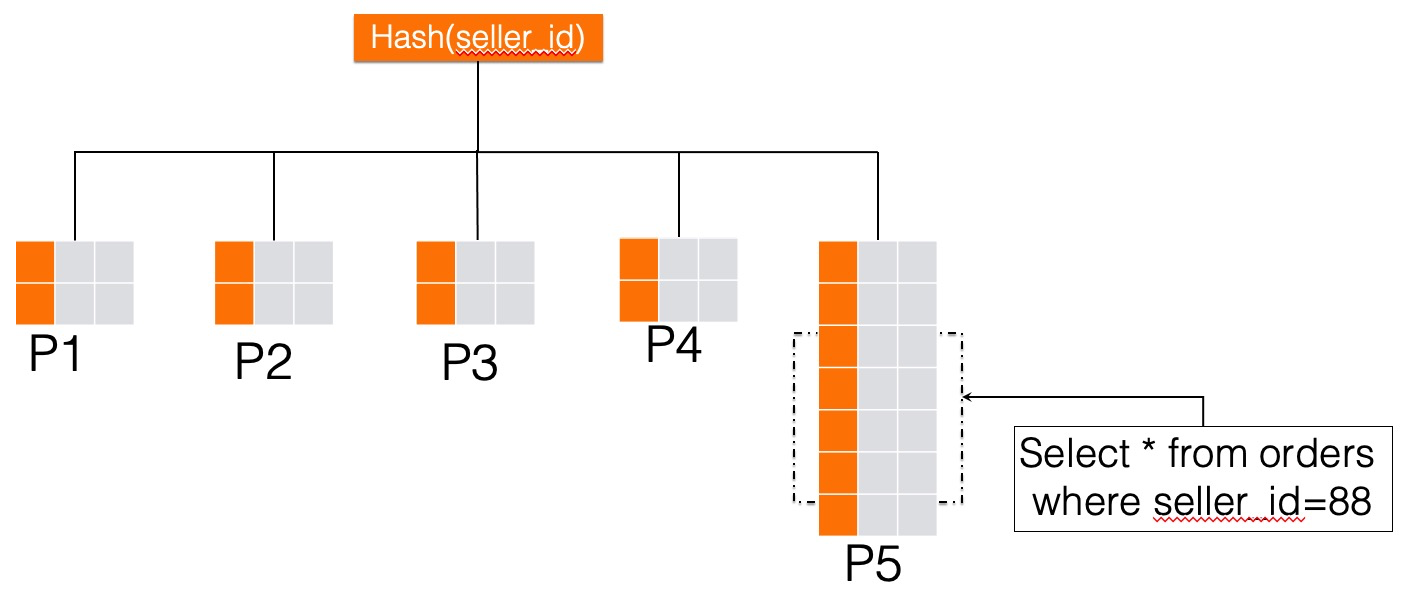
When only one partition key is used, all rows for seller 88 hash to the same value. No matter how many sub-partitions you create from P5, all of seller 88's rows still resolve to that single hash value and end up in the same partition. The data cannot be redistributed.
Adding a second partition key changes the hash space from one-dimensional to two-dimensional, giving the system a second axis along which to distribute the hot seller's data across multiple partitions.
Split a hot data partition
Splitting a hot data partition is a two-step process: add a second partition key column, then split the hot partition using that column.
Step 1: Add a second partition key column
Run the following statement to add id as the second partition key column:
alter table orders partition by key(seller_id,id) partitions 5This statement only modifies partition metadata—it does not rehash or redistribute existing data, and the number of partitions remains 5. The id column is not used for route computing; it serves as a placeholder that enables the two-dimensional hash space.
The following figures compare the hash space before and after adding the second partition key column.
Before the id column is specified

After the id column is specified

Step 2: Split the hot partition
Run the following statement to split the data of seller 88 out of P5 into two new partitions:
alter table orders split into H88_ partitions 2 by hot value(88)PolarDB-X splits seller 88's data from P5 into two partitions named H88_1 and H88_2, using the second partition key column (id) to distribute the rows.
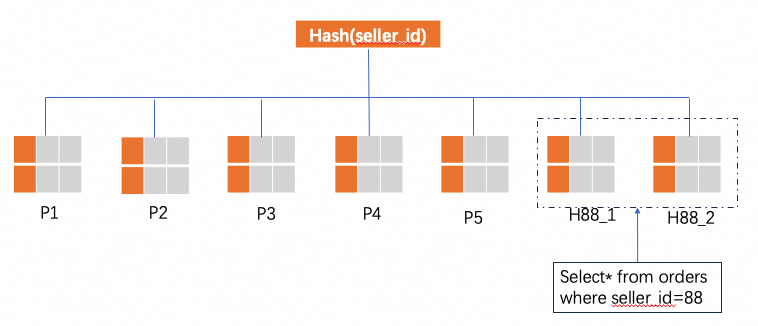
After the split:
-
Seller 88's data is routed to H88_1 and H88_2 instead of P5.
-
All other sellers' data (for example, in P1 and P2) remains unchanged.
Limitations
Hot data partition splitting is only supported on KEY partitioned tables. KEY partitioning is a type of HASH partitioning.