PolarDB-X is a cloud-native distributed database. Its design is based on six core principles: data distribution, horizontal scaling, high availability, distributed transactions, hybrid transactional and analytical processing (HTAP), and MySQL compatibility.
Data distribution
PolarDB-X horizontally partitions table data across multiple data nodes (DNs) using hash and range partitioning. The distributed SQL layer automatically routes queries to the correct nodes and aggregates results across partitions — all transparent to the application.
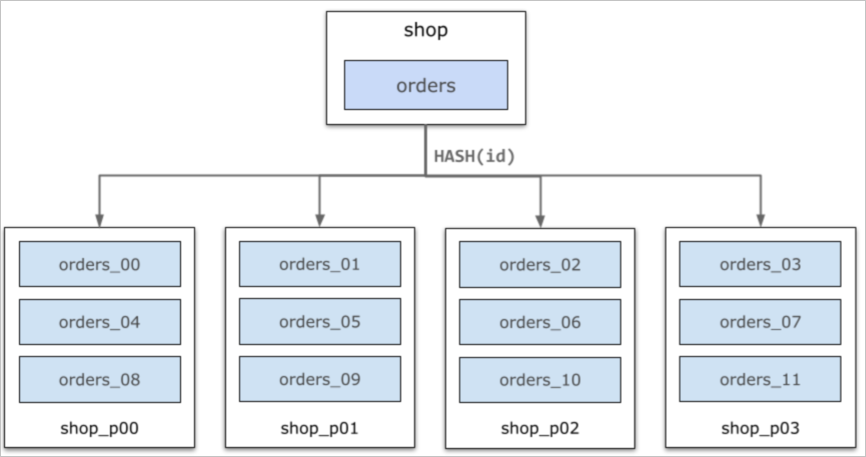
For example, consider a shop table in the orders database. PolarDB-X distributes this table across 12 partitions (orders_00 through orders_11) based on the hash value of each row's ID. These 12 partitions are evenly spread across four data nodes.
Scale-out
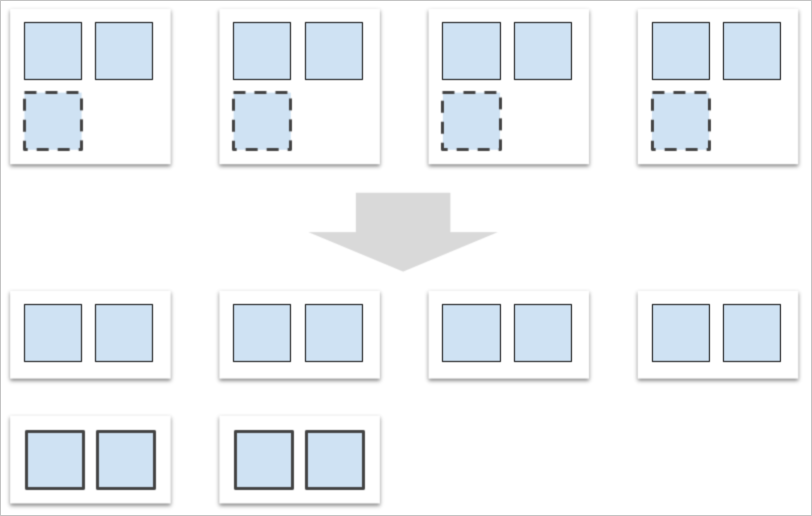
To scale as data volume grows, add more data nodes. When a new node joins the instance, PolarDB-X automatically rebalances partitions from existing nodes to the new ones.
For example, when scaling from 4 to 6 data nodes, PolarDB-X migrates a subset of partitions to the two new nodes. The migration runs in the background using idle resources and does not affect online workloads.
High availability and disaster recovery
Paxos-based replication
Production instances use multiple replicas for high availability and data durability. PolarDB-X uses X-Paxos, an enhanced Paxos consensus replication protocol developed by Alibaba, with performance and functionality optimizations proven at scale. X-Paxos has powered the Double 11 Shopping Festival for over a decade.
X-Paxos requires at least three nodes. Each write must be acknowledged by a majority of nodes before it commits, so the instance remains operational even when one node fails.

Multi-datacenter deployment
X-Paxos supports deploying a PolarDB-X instance across multiple data centers for datacenter-level disaster recovery. Common topologies include:
Three data centers in the same city: Provides local disaster recovery.
Three data centers across two regions: Often used for hybrid cloud deployments.
In both topologies, one data center acts as the primary and handles external traffic.

Distributed transactions
PolarDB-X natively supports distributed transactions with full atomicity, consistency, isolation, and durability (ACID) guarantees.
Consistent snapshot reads
PolarDB-X uses a Timestamp Oracle (TSO) combined with multiversion concurrency control (MVCC) to provide consistent snapshot reads across partitions. The mechanism works as follows:
When a compute node (CN) commits a transaction, it obtains a timestamp from the TSO.
The CN commits both the timestamp and the data to the multiversion storage engine on the target DN.
For reads that span multiple partitions, PolarDB-X retrieves a global timestamp as the read version and evaluates row visibility — returning only data from transactions committed before that timestamp.
This prevents reads from seeing intermediate states of in-flight distributed transactions, such as a partially completed money transfer.

Capabilities built on distributed transactions
Distributed transactions underpin several other PolarDB-X capabilities:
Read/write splitting: Transactional data versions are synchronized to learner replicas, so read-only instances do not serve stale data due to replication lag.
Point-in-time recovery (PITR): Distributed transactions are ordered by timestamp in the global change log. PolarDB-X uses these timestamps to identify the globally consistent data version at any point in time.
Centralized-distributed architecture
PolarDB-X supports an integrated centralized-distributed architecture, combining the scalability and resilience of distributed databases with the manageability and performance of centralized databases.
Data nodes run independently in centralized mode and are fully compatible with the single-node database model. As workloads grow, switch to distributed mode in place — no data migration or application changes required.
Two editions are available:
|
Edition |
Mode |
Use when |
|
Standard Edition |
Centralized |
Workloads fit a single-node model |
|
Enterprise Edition |
Distributed |
Workloads require horizontal scaling |
Upgrade from Standard Edition to Enterprise Edition in place.

HTAP
PolarDB-X supports hybrid transactional and analytical processing (HTAP), handling high-concurrency transactional requests and complex analytical queries in a single system.
Analytical queries operate on large datasets and involve computations such as time-range aggregations. These queries consume more resources than transactional queries and may take seconds to minutes to complete.
To accelerate analytical workloads, PolarDB-X uses In-Memory Column Index (IMCI) technology. IMCI, combined with vectorized operators, significantly improves analytical query performance.

MySQL compatibility
A core design goal of PolarDB-X is compatibility with MySQL and its ecosystem, covering SQL syntax, transaction behavior, and data import and export. For details, see Compatibility with MySQL.
Protocol and connectivity
PolarDB-X is compatible with the MySQL protocol. Connect using standard MySQL clients and drivers — including Java Database Connectivity (JDBC), ODBC, and Golang drivers. PolarDB-X also supports MySQL protocol features such as SSL, Prepare, and Load.
SQL syntax
PolarDB-X supports a broad range of MySQL DML, DAL, and DDL syntax:
Most MySQL functions, including JSON, encryption, and decryption functions
Views, common table expressions (CTEs), window functions, and analytical functions from MySQL 8.0
Various MySQL data types, including precision types such as TIMESTAMP and DECIMAL
Common MySQL string character sets and collations
Most
information_schemaviews
Binary log replication
PolarDB-X is compatible with the MySQL binary log replication protocol. A PolarDB-X cluster can act as either a source or destination in replication with a standard MySQL node. Because the binary log format matches MySQL, it also supports change data capture (CDC) scenarios — for example, using Canal to synchronize data from PolarDB-X to other storage systems.