PolarDB-X is a cloud-native distributed database that combines the stability of Alibaba's DRDS and X-DB technologies, the cloud-native technologies of PolarDB, and NewSQL capabilities for distributed data consistency.
Architecture evolution
Three generations of distributed database technology shaped PolarDB-X: sharding for horizontal scale, NewSQL for ACID guarantees across nodes, and cloud-native database technology for elastic infrastructure. PolarDB-X integrates all three, building on Distributed Relational Database Service (DRDS) and X-DB for proven stability, PolarDB's cloud-native technologies, and NewSQL techniques for global consistency in distributed transactions.

Overall architecture
The following figure shows how a PolarDB-X instance is structured, with compute and storage separated into distinct node types.
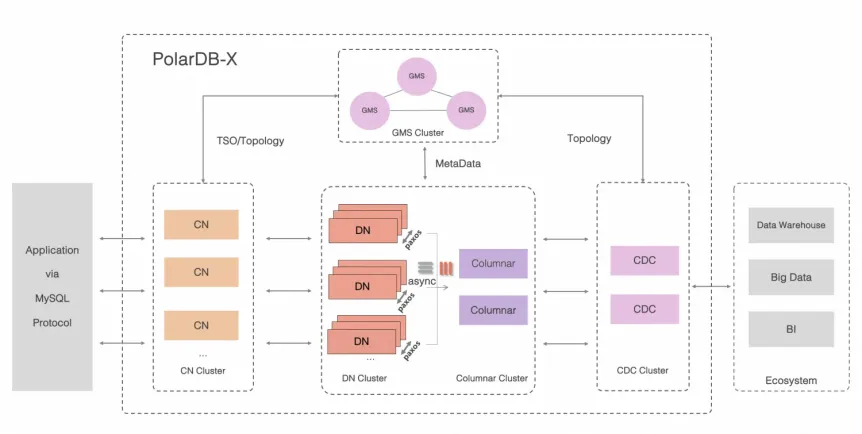
PolarDB-X is organized into five node types that together handle everything from SQL parsing to durable storage.
| Node | Role |
|---|---|
| Global Meta Service (GMS) | Manages distributed metadata (tables, schemas, statistics, accounts, and permissions) and distributes global timestamps via Timestamp Oracle (TSO). |
| Compute Node (CN) | Runs the stateless SQL engine—parses, optimizes, and executes distributed queries. Coordinates distributed transactions using two-phase commit (2PC) and maintains global indexes. |
| Data Node (DN) | Stores and replicates data. Uses Paxos for high availability and multiversion concurrency control (MVCC) for transaction isolation. Supports pushdown computation (Project, Filter, Join, and Agg) to reduce data movement. |
| Change Data Capture (CDC) | Produces a binary log stream fully compatible with MySQL's binary log protocol and data format, enabling downstream consumers to subscribe to changes as they would from a MySQL instance. |
| Columnar node | Maintains persistent columnstore indexes updated in real time from distributed transaction logs. Works with object storage and CNs to serve snapshot-consistent analytical queries at scale. |
Core modules
The following figure shows PolarDB-X's internal processing pipeline, from network ingress to storage.

Like a traditional relational database, PolarDB-X processes each request through a layered pipeline: network → SQL parsing → optimization (logical and physical) → execution → storage. The execution layer supports three modes: single-node two-phase execution, single-node parallel execution, and cross-node parallel execution. The storage layer is compatible with traditional standalone database optimization techniques, so existing tooling and access patterns transfer directly.
Deployment
PolarDB-X instances run on Kubernetes, deployed on high-performance physical servers.
Node configuration: Each instance requires at least two nodes. After creation, scale in or out by at least one node at a time. Available instance sizes include 4c16g, 8c32g, and 16c64g.
Resource isolation: Choose from three instance families:
General-purpose — idle CPU cores are shared across instances on the same server, improving cost-effectiveness.
Dedicated — CPU cores are exclusive to the instance, delivering more consistent performance.
Dedicated host — the physical server is reserved entirely for your instances.
Deployment options: In Alibaba Cloud public cloud, deploy across regions and availability zones. In hybrid cloud environments, use DBStack to deploy and operate PolarDB-X on existing hardware without migrating infrastructure.
Network and security: Supports virtual private cloud (VPC), IP allowlists, asymmetric encryption, and Transparent Data Encryption (TDE).
MySQL compatibility and tooling
PolarDB-X is compatible with MySQL protocols and supports common drivers and languages.

Supported drivers include Java Database Connectivity (JDBC) and Open Database Connectivity (ODBC), with client libraries available for Java, Go, C, C++, and Python.
PolarDB-X integrates with the following Alibaba Cloud services to cover the full database lifecycle:
Data Management Service (DMS): A cloud-based database management platform with over 10 years of usage within Alibaba. Provides a web-based, multi-database management console with no installation or infrastructure management required. Helps enterprise users build database DevOps solutions with the security, efficiency, and compliance standards of Alibaba Group.
Database Autonomy Service (DAS): Uses machine learning and the experience of database experts to automate perception, repair, optimization, O&M, and security management, reducing the risk of failures caused by manual operations.
Data Transmission Service (DTS): Supports relational databases, NoSQL databases, and analytics services. Provides data migration, change tracking, and real-time synchronization to transfer data within milliseconds in an asynchronous manner, backed by the active geo-redundancy architecture used during Alibaba Group's annual Double 11 Shopping Festival. DTS can provide real-time data streams for thousands of downstream applications.
Data Disaster Recovery: A cloud-native backup platform that protects databases deployed in data centers, third-party clouds, public clouds, and hybrid cloud environments.
Key capabilities
High availability
PolarDB-X uses X-Paxos for strongly consistent replication, delivering a recovery point objective (RPO) of 0 on node failover. Replication within a Paxos group is always synchronous, so no data is lost when a node fails. These capabilities have been consistently proven during the Double 11 Shopping Festival over the years.
Several deployment topologies are available depending on your availability requirements:
| Topology | Replication | Use when |
|---|---|---|
| Three data centers in one region | Synchronous (Paxos) | Standard high availability within a region |
| Five data centers across three regions | Synchronous (Paxos) | Strict RPO=0 across regional failures |
| Three data centers across two zones | Asynchronous (binary log) | Cost-sensitive cross-zone redundancy |
| Geo-disaster recovery | Asynchronous (binary log) | Disaster recovery to a remote region |
| Active geo-redundancy | Asynchronous (binary log) | Multi-region active-active writes |
For cross-region replication, PolarDB-X uses batching and pipelining to optimize network throughput and reduce replication lag.
MySQL compatibility
PolarDB-X supports MySQL SQL syntax, functions, and driver protocols. Beyond syntax, it preserves MySQL ecosystem integration at the protocol level:
Global consistency: Timestamp Oracle (TSO) provides a globally ordered timestamp for every transaction, enabling consistent reads across all data nodes.
Full ACID: Combined TSO and two-phase commit (2PC) deliver full atomicity, consistency, isolation, and durability (ACID) guarantees. Supported isolation levels are Read Committed and Repeatable Read.
Global secondary indexes: Maintained with strong consistency between index tables and base tables across distributed transactions, using a cost-based optimizer (CBO) for index selection.
Online DDL: Schema changes are applied online with metadata consistency across all nodes, so DDL operations do not block concurrent workloads.
Binary log compatibility: PolarDB-X produces binary logs using the standard MySQL dump protocol, with the same binary log format and data structures as MySQL. Any tool or service that consumes MySQL binary logs works with PolarDB-X without modification.
Hardware compatibility: Runs on operating systems and CPUs from major Chinese vendors, including Kirin, Kunpeng, and Hygon.
Horizontal scalability
PolarDB-X uses a shared-nothing architecture for horizontal scaling. Nodes can be added or removed online without downtime.
Online transaction processing (OLTP): Scales to handle tens of millions of concurrent requests and petabytes of data.
Online analytical processing (OLAP): Uses massively parallel processing (MPP) to scale query performance linearly with node count, meeting complex query benchmarks such as TPC-H.
HTAP
PolarDB-X handles hybrid transactional/analytical processing (HTAP) workloads in a single instance. The system automatically classifies each query as transactional or analytical and routes it to the appropriate replica.
Transactional workloads follow the standard OLTP path.
Analytical workloads are routed to read replicas, with MPP enabled by default on the analytical path.
The compute layer enforces isolation between workload types using consistent reads on multiple replicas, so analytical queries do not affect the stability of transaction processing workloads.
Running TPC-C and TPC-H benchmarks simultaneously in the same instance demonstrates that analytical processing workloads do not affect the stability of transaction processing workloads. Future versions will include a high-performance columnar storage engine that provides HTAP capability for hybrid row-column storage.
Extreme elasticity
PolarDB-X supports shared storage inherited from PolarDB, which uses Remote Direct Memory Access (RDMA)-based network optimization. With shared storage, all compute nodes access the same underlying data volume. Adding a compute node connects it to the existing volume rather than copying data, so scaling completes in seconds. PolarDB-X can also write multiple data records at the same time, enabling you to expand the storage capacity of an instance based on your business requirements.
Ecosystem compatibility
PolarDB-X is fully compatible with the MySQL open-source ecosystem and maintains full control over its codebase. PolarDB-X integrates with existing MySQL tooling, workflows, and binary log consumers without modification. PolarDB-X can work with other Alibaba Cloud database services such as DTS, Data Disaster Recovery, and DMS to form a closed loop, connecting to the entire ecosystem of Alibaba Cloud.
Key terms
| Term | Definition |
|---|---|
| Global Meta Service (GMS) | The metadata and timestamp authority for the cluster. Stores table schemas, statistics, and access control information, and issues globally ordered timestamps via Timestamp Oracle (TSO). |
| Timestamp Oracle (TSO) | A global timestamp distributor built into GMS. Assigns a monotonically increasing timestamp to every transaction, enabling consistent reads across distributed nodes. |
| Compute Node (CN) | A stateless SQL engine that parses, plans, and executes queries. CNs coordinate distributed transactions and maintain global indexes. Because CNs are stateless, they scale independently of data nodes. |
| Data Node (DN) | A storage node that persists and replicates data using Paxos. DNs use MVCC for concurrent transaction isolation and support pushdown computation to minimize data movement across nodes. |
| Change Data Capture (CDC) | A component that exposes a MySQL-compatible binary log stream. Downstream consumers—replication tools, ETL pipelines, event-driven systems—subscribe to it the same way they would subscribe to a MySQL binary log. |
| Columnar node | A node that maintains columnstore indexes derived from the distributed transaction log. Columnstore indexes are updated in real time and stored in object storage, enabling analytical queries without affecting OLTP performance. |
| Two-phase commit (2PC) | The protocol CNs use to coordinate atomic commits across multiple DNs, ensuring that a transaction either commits on all nodes or rolls back on all nodes. |
| Paxos / X-Paxos | A consensus algorithm used by DNs for synchronous replication. X-Paxos is PolarDB-X's in-house implementation. A Paxos group tolerates the failure of a minority of its members without data loss. |
| MVCC | Multiversion concurrency control. DNs maintain multiple versions of each row so readers never block writers and writers never block readers. |
| Pushdown computation | The ability to push operators (Project, Filter, Join, and Agg) down to DNs, reducing the volume of data that CNs need to process and transfer across the network. |
| Shared-nothing architecture | A design where each node has its own CPU and memory with no shared state between nodes. Enables linear horizontal scaling by adding independent nodes. |
| TSO | See Timestamp Oracle (TSO). |
| MPP | Massively parallel processing. Distributes query execution across multiple CNs and DNs simultaneously, enabling linear query performance scaling for OLAP workloads. |