Elastic parallel query (ePQ) distributes analytical queries across all read-only nodes in a PolarDB for PostgreSQL cluster, letting you scale out query performance without redistributing data.
Prerequisites
Before you begin, ensure that you have:
A PolarDB for PostgreSQL cluster running PostgreSQL 11 (revision 1.1.28 or later)
To check your revision version, run:
SHOW polar_version;Background
PolarDB for PostgreSQL is built on a shared storage architecture that provides theoretically unlimited I/O throughput. Native PostgreSQL, however, executes each SQL statement on a single node — regardless of how many read-only nodes are in the cluster. This creates two problems for analytical workloads:
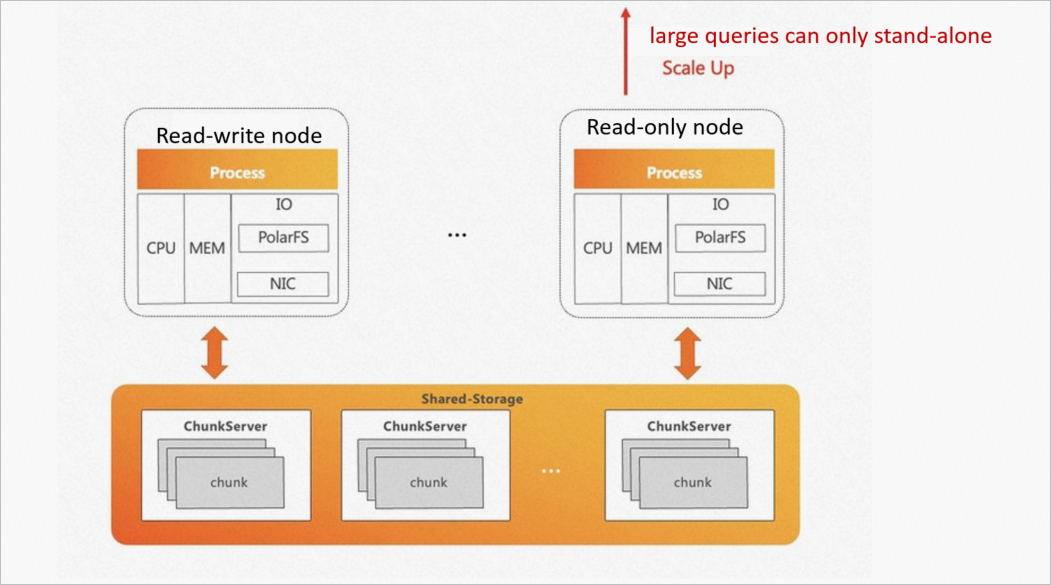
Single-node execution: CPU and memory on other nodes sit idle during complex queries. Scaling up a single node is the only option; horizontal scale-out is not possible.
Underutilized I/O: Because queries are bound to one node, the full I/O bandwidth of the shared storage pool is never used.
ePQ solves both problems by spreading query execution across multiple read-only nodes while keeping all nodes connected to the same shared storage.
Industry HTAP approaches
Three HTAP architectural approaches are common in the industry:
| Approach | Advantages | Disadvantages |
|---|---|---|
| Fully isolated — transactional and analytical systems use completely separate storage and compute | Workloads never affect each other | Data must be imported into the analytical system with latency; running two systems in parallel increases cost and O&M complexity |
| Fully shared — transactional and analytical systems share both storage and compute | Minimizes cost; maximizes resource utilization | Analytical and transactional queries can affect each other; scale-out requires data redistribution, slowing expansion |
| Shared storage, separate compute — transactional and analytical systems share storage but use isolated compute resources | Combines low storage cost with workload isolation; scale-out requires no data redistribution | — |
PolarDB for PostgreSQL uses the third approach. Its storage-compute decoupled architecture naturally supports shared storage with physically isolated compute resources for each workload type.
How it works
Architecture
PolarDB for PostgreSQL implements hybrid transactional and analytical processing (HTAP) by combining shared storage with physically isolated compute resources:
| Layer | What runs there | Purpose |
|---|---|---|
| Shared storage | All data | Single copy; millisecond-fresh reads for both workload types |
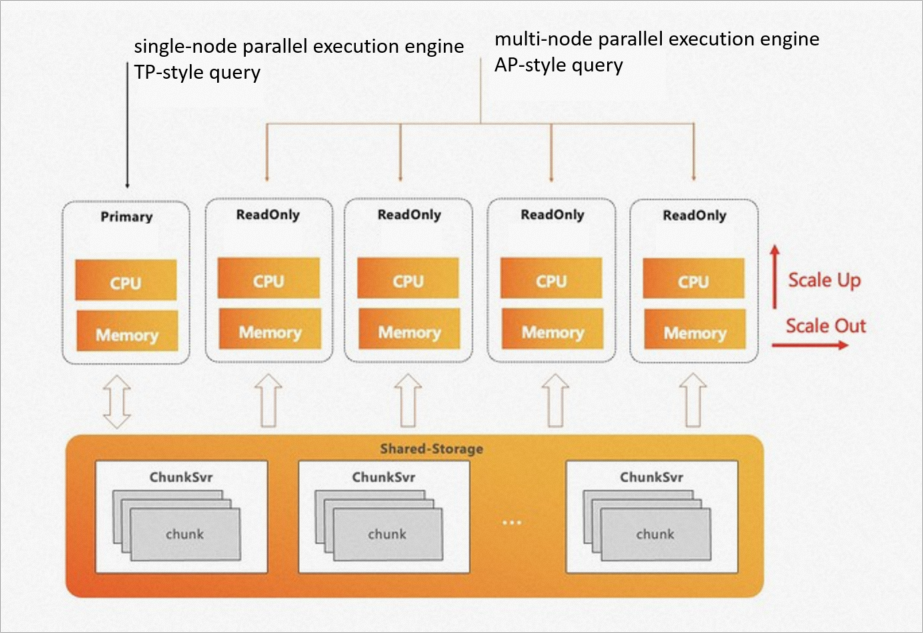
| Primary node | OLTP + single-node parallel query (PQ) | Handles transactional traffic |
| Read-only nodes | ePQ engine | Handles high-complexity analytical queries |
This design means transactional and analytical workloads never compete for CPU or memory. Scale-out takes effect immediately — no data redistribution required.
ePQ engine
ePQ is not the same as PostgreSQL's built-in parallel query. Native PQ parallelizes execution within a single node using multiple CPU cores. ePQ parallelizes execution across nodes using the shared storage architecture.
In a conventional massively parallel processing (MPP) database, data is distributed across nodes using hash, random, or replication strategies. Each node worker scans only its local data. When PolarDB runs the same workload, all compute nodes can access all data in shared storage — so a naive MPP approach would cause every worker to scan the entire table, producing duplicate results.
ePQ solves this with PxScan operators, which map shared-storage data to a shared-nothing model:
A table is divided into virtual partitions.
Each worker scans only its assigned virtual partitions — no duplicates, no coordination overhead.
Shuffle operators redistribute the scanned data across workers based on join or aggregation keys.
Each worker processes its redistributed data locally, following the volcano model, as if executing on a single node.
The result: ePQ uses standard query execution semantics but achieves true multi-node parallelism.

Serverless scaling
Standard MPP engines require you to specify a fixed set of nodes before running a query. ePQ takes a different approach — any read-only node can serve as the coordinator node, eliminating the single point of failure common in MPP systems.
How consistency is maintained across nodes:
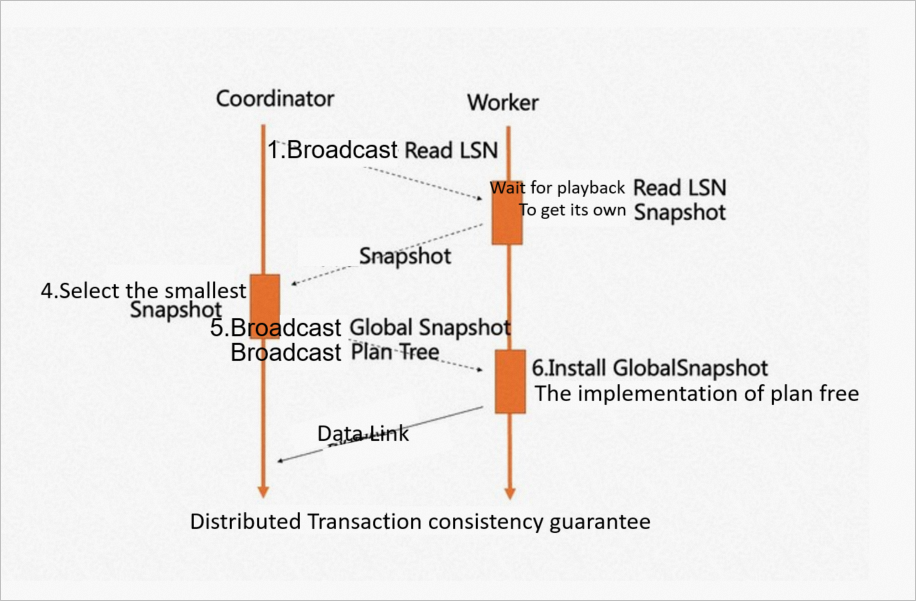
When a query starts, the system selects a coordinator node and uses its read log sequence number (ReadLSN) as the agreed LSN. The earliest snapshot version across all participating nodes becomes the agreed global snapshot version. Two mechanisms keep data consistent:
LSN replay waiting: worker nodes replay the write-ahead log (WAL) up to the agreed LSN before scanning.
Global snapshot synchronization: all workers use the same transaction snapshot, ensuring consistent reads.
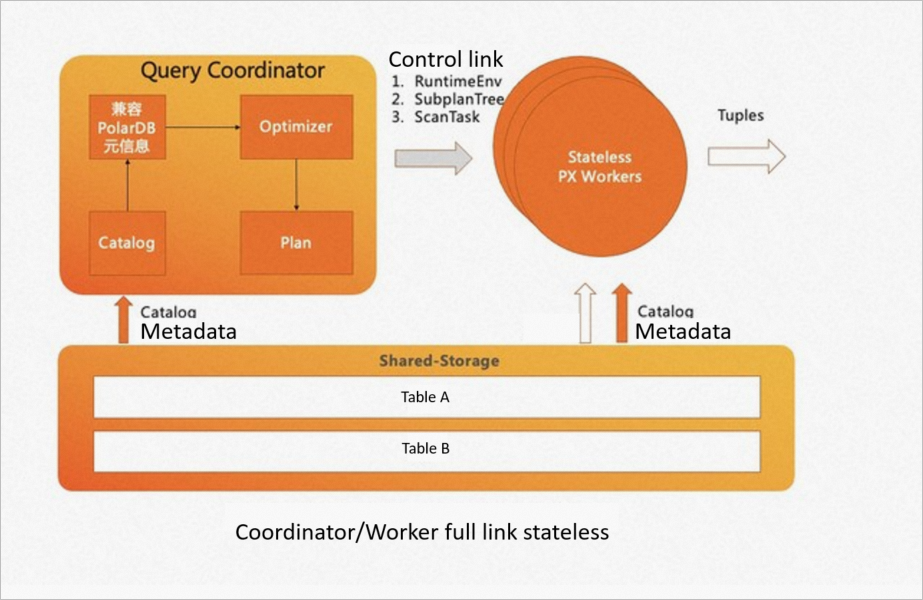
All external dependencies from the coordinator — GUC parameters, session state, topology — are stored in shared storage and synchronized to worker nodes over the control link. This makes both the coordinator and workers fully stateless.
What serverless scaling enables:
Add compute nodes or increase the degree of parallelism (DOP) on each node; changes take effect immediately.
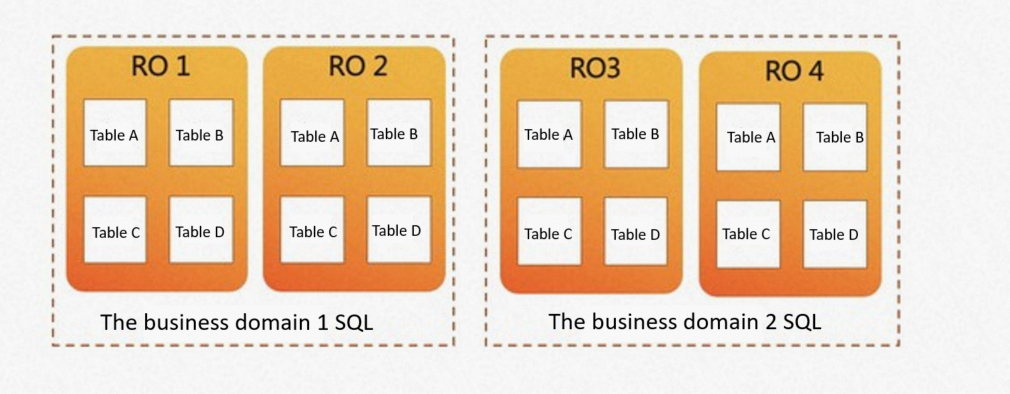
Route different business domains to different node sets. For example, business domain 1 can run analytical queries on RO1 and RO2, while business domain 2 uses RO3 and RO4 — with no data movement between them.
Skew removal
In any MPP system, the slowest worker determines the overall query latency. Skew has two sources:
Data skew: uneven data distribution across partitions. PostgreSQL's TOAST table storage can introduce unavoidable data skew for large column values.
Computational skew: differences in worker speed caused by concurrent transactions, buffer pool state, network jitter, or I/O fluctuations.
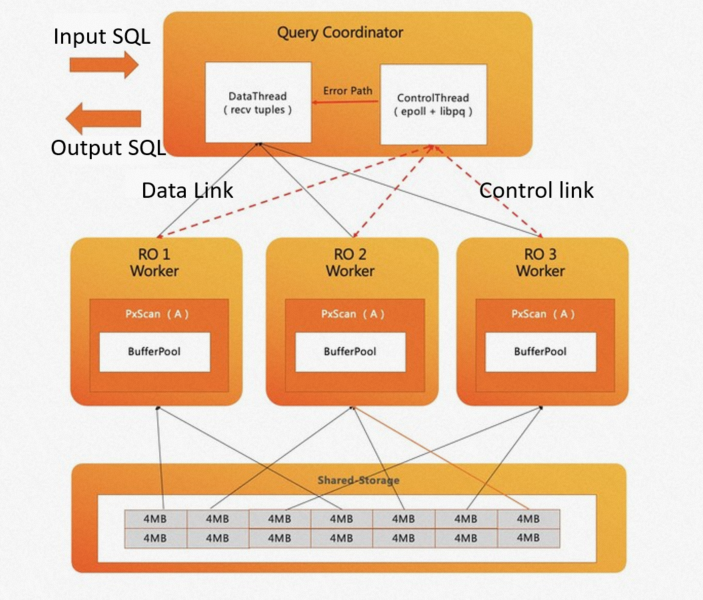
ePQ addresses both with an adaptive scanning mechanism. When a scan begins, the coordinator creates a task manager in memory that dynamically assigns data blocks to workers:
The coordinator runs two threads: a data thread (manages data connections and collects tuples) and a control thread (tracks the scan progress of each worker).
Faster workers receive additional data blocks. In the example below, RO1 and RO3 each scan four blocks, while RO2 — experiencing computational skew — handles six blocks.
The adaptive scanner also accounts for buffer pool affinity: each worker is preferentially assigned the same data blocks it scanned previously. This maximizes buffer pool hit rates and reduces I/O bandwidth usage.
Performance
ePQ vs. PQ
Test environment: 16 read-only nodes, 256 GB memory per node, 1 TB TPC-H dataset.
| Metric | Result |
|---|---|
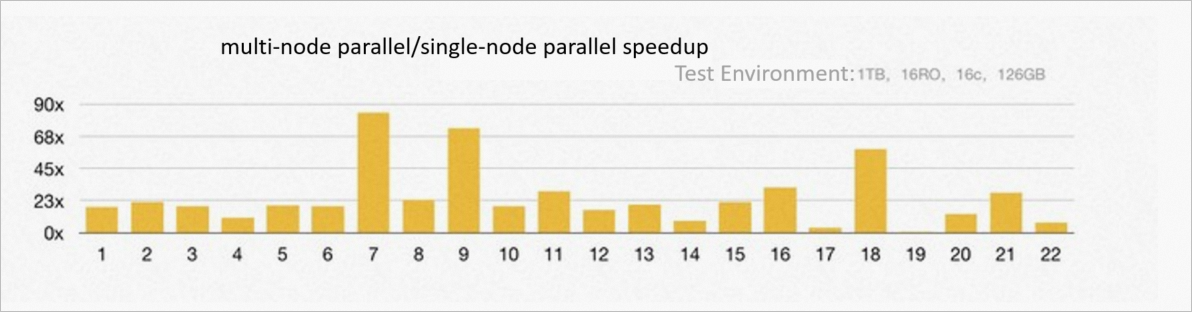
| Average speedup across 22 TPC-H queries | 23x faster than single-node PQ |
| Queries accelerated more than 60x | 3 |
| Queries accelerated more than 10x | 19 |
Linear scaling with CPU cores:
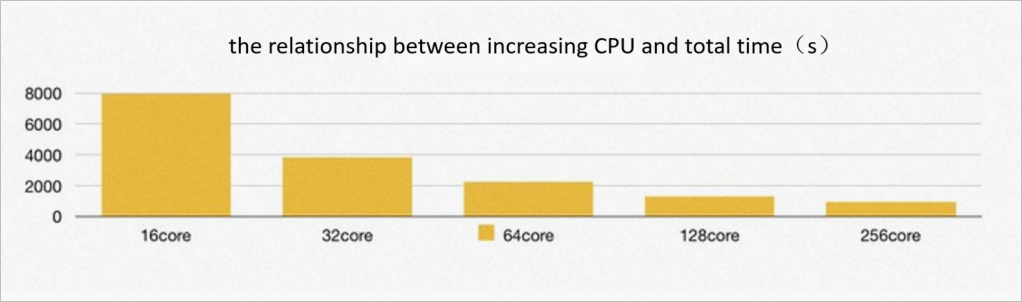
As CPU core count increases from 16 to 128, total TPC-H execution time and per-query execution time improve linearly — evidence of true horizontal scalability. Beyond 256 CPU cores, no significant improvement occurs because shared storage I/O bandwidth becomes the bottleneck.
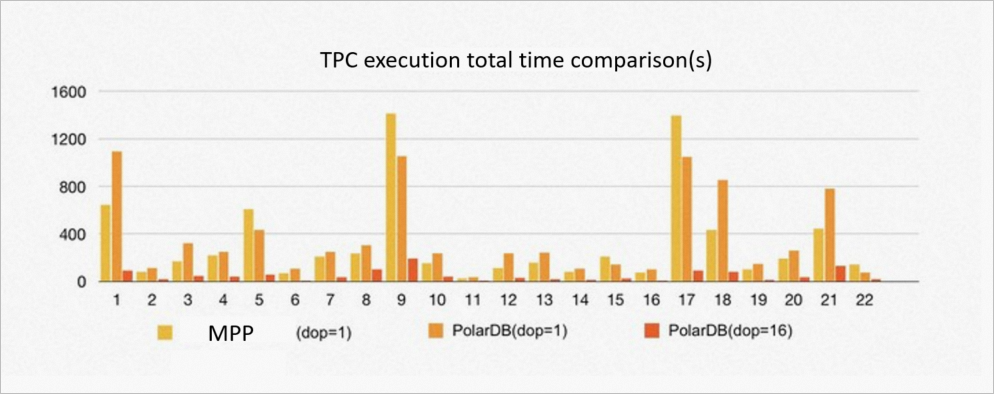
ePQ vs. MPP databases
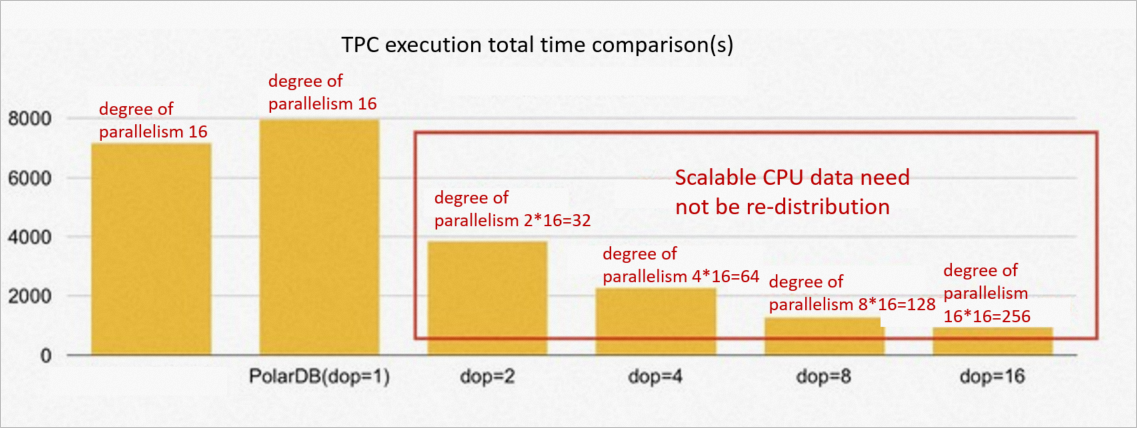
Test environment: 16 read-only nodes, 256 GB memory, 1 TB TPC-H dataset. Same degree of parallelism.
At the same degree of parallelism, PolarDB reaches 90% of MPP database performance. The gap exists because MPP databases store data with hash distribution by default, enabling partition-wise joins without shuffle. PolarDB's shared storage exposes data as an equivalent of random distribution, so shuffle redistribution is always required before joins.
The key advantage is that PolarDB can increase the degree of parallelism per node without any data movement. At a degree of parallelism of 8 per node, PolarDB outperforms the MPP database by 5–6x. Changing the degree of parallelism takes effect immediately.
Features
Parallel queries
ePQ supports the following parallel query capabilities:
All basic operators: seq scan, index scan, join, aggregate, and subquery.
Shared storage optimizations: shuffle operator sharing, SharedSeqScan sharing, and SharedIndexScan sharing. When a large table joins a small table, SharedSeqScan and SharedIndexScan use a table-replication-like mechanism to reduce broadcast overhead.
Partitioned tables: hash, range, and list partitioning; static and dynamic pruning of multi-level partitions; partition-wise joins.
Degree of parallelism (DOP) control: at the global, table, session, and query levels.
Flexible node targeting: initiate ePQ from any node, or restrict queries to a specific subset of nodes. PolarDB automatically maintains cluster topology and supports shared storage, primary/secondary, and three-node cluster modes.
Parallel DML
ePQ extends parallel execution to DML operations through two modes:
| Mode | Read workers | Write workers | Use when |
|---|---|---|---|
| One write, multiple reads | Multiple workers on read-only nodes | One worker on the primary node | Standard write workloads requiring consistency |
| Multiple writes, multiple reads | Multiple workers on read-only nodes | Multiple workers on the primary node | High-throughput write workloads; read DOP and write DOP are configured independently |
Index creation acceleration
B-tree index creation spends roughly 80% of its time sorting data and building index pages, and 20% writing those pages. ePQ accelerates this by offloading data sorting to read-only nodes and using a pipelined technique to build and batch-write index pages.
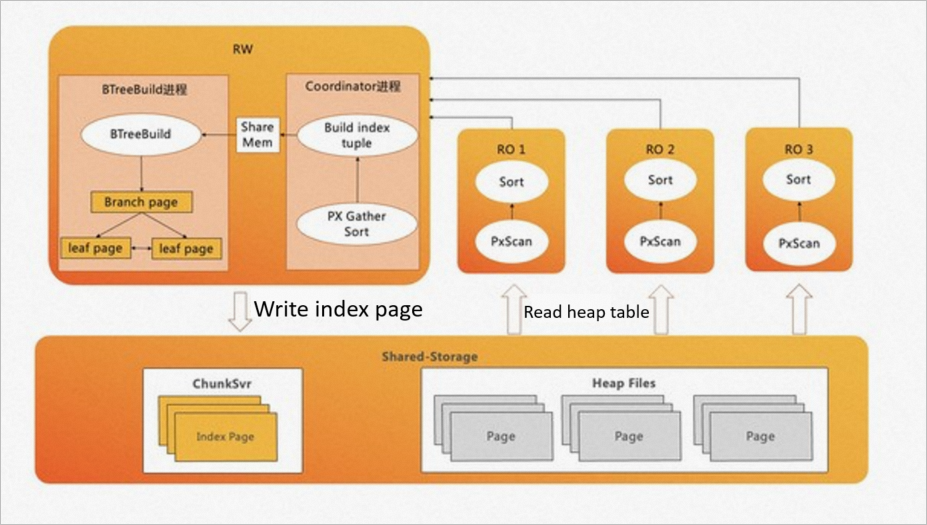
Index creation acceleration supports B-tree indexes in standard and concurrent modes. INCLUDE mode and expression-type index columns are not supported.
Enable and configure ePQ
ePQ is disabled by default. The following sections cover the key configuration scenarios.
Configuration parameters
Core parameters:
| Parameter | Default | Valid values | Description |
|---|---|---|---|
polar_enable_px | off | on, off | Enables or disables ePQ for the current session. |
polar_px_max_workers_number | 30 | 0–2147483647 | Maximum total worker processes across all sessions on a single node. When this limit is reached, new ePQ queries on that node run without parallelism. Set this based on available CPU cores. |
polar_px_dop_per_node | 1 | 1–128 | Degree of parallelism per node for the current session. Set this equal to the number of CPU cores for best throughput. |
polar_px_nodes | *(all read-only nodes)* | Comma-separated node names | Restricts ePQ to the specified read-only nodes. Leave blank to use all available nodes. |
px_worker (table option) | *(ePQ disabled per table)* | -1 (enable), 0 (disable) | Controls ePQ eligibility per table. Because ePQ consumes additional resources, enable it selectively on the tables that benefit most. |
Index creation acceleration parameters:
| Parameter | Default | Valid values | Description |
|---|---|---|---|
polar_px_enable_btbuild | OFF | ON, OFF | Enables B-tree index creation acceleration. |
polar_px_dop_per_node | 1 | 1–128 | Degree of parallelism used during index creation. |
polar_px_enable_replay_wait | *(auto)* | — | Automatically enabled during index-accelerated sessions to ensure all recently committed data is included in the index. Resets to the default value after index creation completes. |
polar_bt_write_page_buffer_size | 0 | 0–8192 (blocks) | Controls write I/O behavior when building indexes. Set to 4096 to buffer index page writes in the kernel and flush in batches — this reduces index creation time by approximately 20%. The default value of 0 flushes each index page block by block as it fills. |
Run ePQ on a single table
Create the table and insert data.
CREATE TABLE test (id int); INSERT INTO test SELECT generate_series(1, 1000000);Check the default execution plan (ePQ is off).
EXPLAIN SELECT * FROM test;QUERY PLAN -------------------------------------------------------- Seq Scan on test (cost=0.00..35.50 rows=2550 width=4) (1 row)Enable ePQ for the table and the session.
ALTER TABLE test SET (px_workers=1); SET polar_enable_px = on;Check the updated execution plan.
EXPLAIN SELECT * FROM test;QUERY PLAN ------------------------------------------------------------------------------- PX Coordinator 2:1 (slice1; segments: 2) (cost=0.00..431.00 rows=1 width=4) -> Seq Scan on test (scan partial) (cost=0.00..431.00 rows=1 width=4) Optimizer: PolarDB PX Optimizer (3 rows)The
PX Coordinatorandscan partialoperators confirm that ePQ is active. EachSeq Scanworker scans a virtual partition of the table rather than the full table.
Target specific nodes for ePQ
By default, ePQ uses all available read-only nodes. To restrict a query to a subset of nodes:
Install the monitoring extension and list available read-only nodes.
CREATE EXTENSION polar_monitor; SELECT name, host, port FROM polar_cluster_info WHERE px_node = 't';name | host | port -------+-----------+------ node1 | 127.0.0.1 | 5433 node2 | 127.0.0.1 | 5434 (2 rows)Restrict ePQ to node1.
SET polar_px_nodes = 'node1';Verify the setting.
SHOW polar_px_nodes;polar_px_nodes ---------------- node1 (1 row)Confirm that only the targeted node participates.
EXPLAIN SELECT * FROM test;QUERY PLAN ------------------------------------------------------------------------------- PX Coordinator 1:1 (slice1; segments: 1) (cost=0.00..431.00 rows=1 width=4) -> Partial Seq Scan on test (cost=0.00..431.00 rows=1 width=4) Optimizer: PolarDB PX Optimizer (3 rows)The plan shows
segments: 1, confirming that only node1 is participating.
Run ePQ on partitioned tables
Enable ePQ.
SET polar_enable_px = ON;Enable ePQ for partitioned tables.
ePQ is disabled for partitioned tables by default.
SET polar_px_enable_partition = true;(Optional) Enable ePQ for multi-level partitioned tables.
SET polar_px_optimizer_multilevel_partitioning = true;
ePQ supports the following operations on partitioned tables:
Parallel scan of range, list, and single-column hash partitions
Static and dynamic partition pruning
Parallel scan of partitioned tables with indexes
Joins involving partitioned tables
Multi-level partitioned table queries
Accelerate B-tree index creation
Enable the acceleration feature.
SET polar_px_enable_btbuild = on;Create the index with acceleration enabled.
CREATE INDEX t ON test(id) WITH (px_build = ON);Verify that the index was built with acceleration.
\d testTable "public.test" Column | Type | Collation | Nullable | Default --------+---------+-----------+----------+--------- id | integer | | | id2 | integer | | | Indexes: "t" btree (id) WITH (px_build=finish)The
px_build=finishstatus confirms the index was built using ePQ acceleration.
To reduce index creation time by approximately 20%, set the write buffer size:
SET polar_bt_write_page_buffer_size = 4096;This buffers index page writes in the kernel and flushes them in batches, reducing the overhead of frequent I/O scheduling.