PolarDB for PostgreSQL supports promoting a read-only node to the primary node without a cluster restart, which reduces the recovery time objective (RTO) during failover or planned switchovers.
When to use this feature
Promote a read-only node to the primary node in these scenarios:
-
Failover: The primary node fails and you need a read-only node to take over read and write traffic.
-
Planned switchover: You want to shift the primary role to a different node for maintenance or resource rebalancing without stopping the cluster.
Supported versions
Your PolarDB for PostgreSQL cluster must run one of the following minor engine versions:
| PostgreSQL version | Minimum minor engine version |
|---|---|
| PostgreSQL 18 | 2.0.18.0.1.0 |
| PostgreSQL 17 | 2.0.17.2.1.0 |
| PostgreSQL 16 | 2.0.16.3.1.1 |
| PostgreSQL 15 | 2.0.15.7.1.1 |
| PostgreSQL 14 | 2.0.14.5.1.0 |
| PostgreSQL 11 | 2.0.11.2.1.0 |
To check your minor engine version, run SHOW polardb_version; or view the minor engine version in the PolarDB console. If the version does not meet the requirement, upgrade the minor engine version before proceeding.
Background
PolarDB for PostgreSQL uses a one-writer, multiple-reader architecture based on shared storage. Read-only nodes in this architecture differ from standby nodes in traditional databases:
| Standby node (traditional database) | Replica node (PolarDB for PostgreSQL) | |
|---|---|---|
| Storage | Independent storage | Shared storage with the primary node |
| Data sync | Transfers complete Write-Ahead Logging (WAL) logs | Transfers WAL metadata only |
Traditional databases can promote a standby node to the primary node without a restart to ensure high availability (HA) and reduce RTO. Because Replica nodes differ from traditional standby nodes, PolarDB for PostgreSQL provides a dedicated online promotion mechanism suited to its shared-storage architecture.
Promote a read-only node
Use pg_ctl to promote a Replica node to the primary node:
pg_ctl promote -D [datadir]Replace [datadir] with the data directory path of the Replica node.
What happens during promotion:
-
The Replica node continues serving read-only requests until the Startup process exits, but the data served may not be up-to-date.
-
All backend sessions are disconnected to prevent stale reads on the new primary node.
-
Read and write services become available after the Startup process exits.
How it works
The online promotion feature uses a trigger mechanism. The promotion is triggered in one of the following ways:
-
Run
pg_ctl promote. Thepg_ctlutility sends a signal to the postmaster process, which coordinates the promotion across all processes. -
Define a trigger file path in the
recovery.conffile. The promotion starts when the trigger file is created.
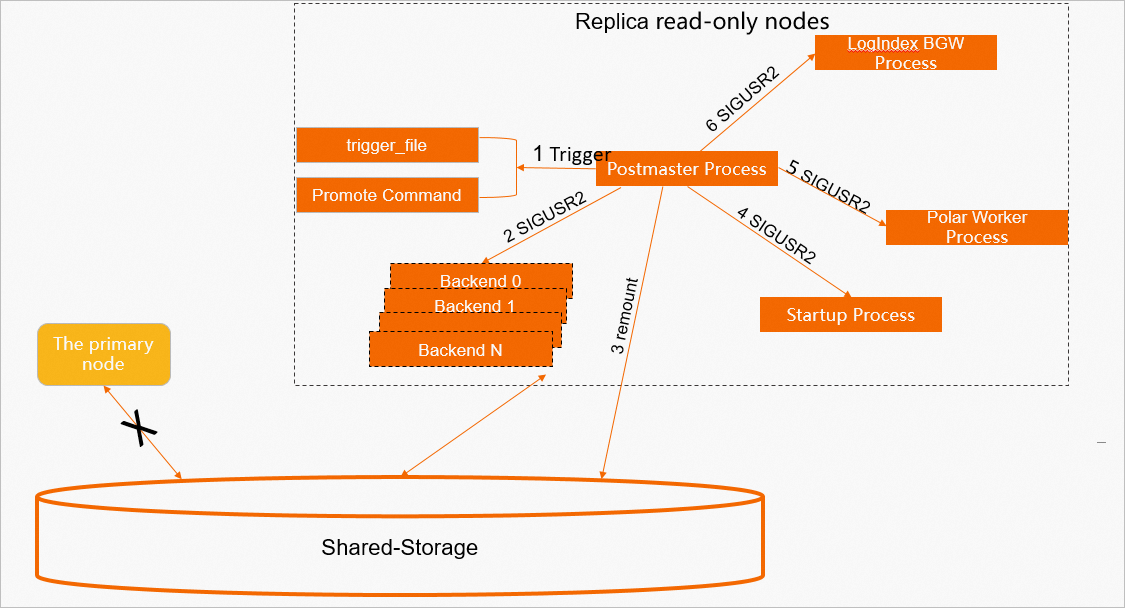
Once triggered, three processes handle the promotion in sequence: the postmaster process, the Startup process, and the LogIndex background worker (BGW).
Postmaster process
-
The postmaster process detects the trigger file or receives the promote command and starts the online promotion.
-
It sends SIGTERM to all backend processes to disconnect all sessions.
-
It remounts the shared storage in read/write mode.
This step requires support from the underlying storage.
-
It sends SIGUSR2 to the Startup process to end log replay and handle the promotion.
-
It sends SIGUSR2 to the Polar Worker auxiliary process to stop parsing LogIndex data that is only needed during normal Replica operation.
-
It sends SIGUSR2 to the LogIndex BGW process to handle the promotion.
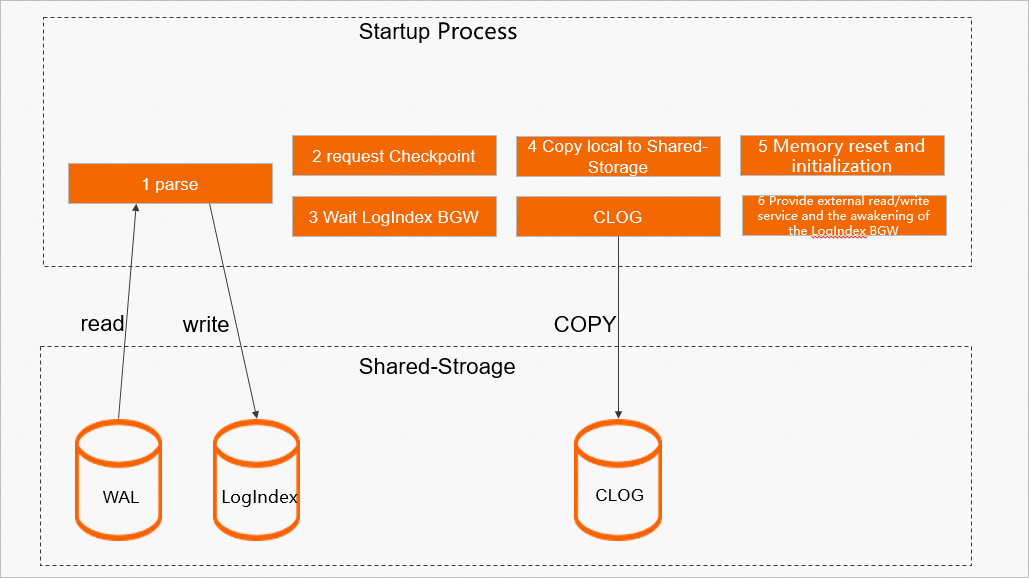
Startup process
-
The Startup process replays all WAL logs generated by the old primary node and generates the corresponding LogIndex data.
-
It confirms that the last checkpoint from the old primary node has completed on the Replica node, ensuring that checkpoint data is flushed to disk.
-
It waits for the LogIndex BGW process to enter the
POLAR_BG_WAITING_RESETstate. -
It copies local data, such as the commit log (clog), from the Replica node to shared storage.
-
It resets the WAL Meta Queue memory space, reloads slot information from shared storage, and resets the LogIndex BGW replay offset to the minimum of its current offset and the consistency offset. This new offset becomes the starting point for the next replay by the LogIndex BGW process.
-
It sets the node role to primary and sets the LogIndex BGW state to
POLAR_BG_ONLINE_PROMOTE. At this point, the cluster can serve read and write requests.
LogIndex BGW process
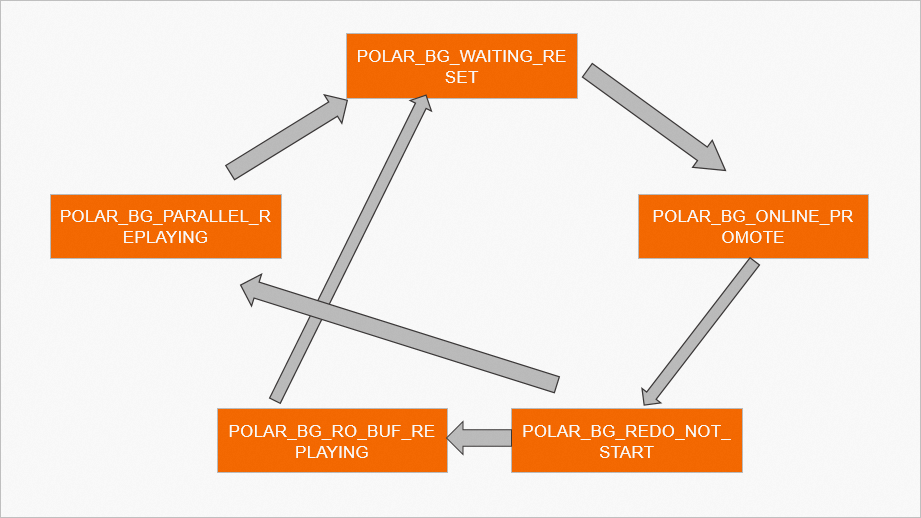
The LogIndex BGW process runs according to a state machine throughout its lifecycle. The following table describes the operations for each state.
| State | Description |
|---|---|
POLAR_BG_WAITING_RESET |
The process state is reset. It notifies other processes that the state machine has changed. |
POLAR_BG_ONLINE_PROMOTE |
Reads LogIndex data, organizes and distributes replay tasks, and uses the parallel replay process group to replay WAL logs. The process must replay all LogIndex data before switching to another state. After replay, it advances the replay offset of the background replay process. |
POLAR_BG_REDO_NOT_START |
The replay task has ended. |
POLAR_BG_RO_BUF_REPLAYING |
Normal Replica running state. Reads LogIndex data, replays WAL logs in sequence, and advances the replay offset after each round. |
POLAR_BG_PARALLEL_REPLAYING |
Reads LogIndex data, organizes and distributes replay tasks, and uses the parallel replay process group to replay WAL logs. Advances the replay offset after each round. |
After the LogIndex BGW process receives SIGUSR2 from the postmaster process, it runs the online promotion as follows:
-
It flushes all LogIndex data to disk and switches its state to
POLAR_BG_WAITING_RESET. -
It waits for the Startup process to switch the LogIndex BGW state to
POLAR_BG_ONLINE_PROMOTE, then replays all WAL logs in sequence:-
Before promotion: the background replay process replays only pages in the buffer pool.
-
During promotion: some pages from the old primary node may not have been flushed to disk. The background replay process replays all WAL logs in sequence and calls
MarkBufferDirtyto mark replayed pages as dirty, queuing them for flushing. -
After replay: it advances the replay offset and switches its state to
POLAR_BG_REDO_NOT_START.
-
Dirty page flushing control
Each dirty page has an Oldest Log Sequence Number (LSN). This LSN is ordered in the FlushList and determines the consistency offset.
After promotion, both WAL replay and new write operations occur simultaneously. On a primary node, the current WAL insertion offset is used directly as the buffer's Oldest LSN. Applying this same approach on the newly promoted node could advance the consistency offset before all buffers with smaller LSNs are flushed to disk.
To avoid this, PolarDB for PostgreSQL handles two categories of dirty pages during online promotion:
-
Dirty pages created when replaying WAL logs from the old primary node.
-
Dirty pages created by new write operations on the new primary node.
In both cases, PolarDB for PostgreSQL sets the Oldest LSN to the replay offset advanced by the LogIndex BGW process. The consistency offset advances only after all buffers marked with the same Oldest LSN are flushed to disk.