GanosBase and PolarDB for PostgreSQL support polymorphic tiered storage, which lets you move spatial data, large objects (LOBs), and partitioned data to Object Storage Service (OSS) while keeping full SQL transparency. Combined with a materialized cache layer on Elastic Block Storage (EBS), this approach cuts storage costs by 90% or more with acceptable performance trade-offs for analytical and archival workloads.
How it works
Polymorphic tiered storage moves cold data — expired partitions, LOB fields, or raster block data — to OSS, while keeping hot data and indexes on EBS. A materialized cache layer sits between your queries and OSS, automatically caching frequently accessed data blocks so reads don't always reach object storage.
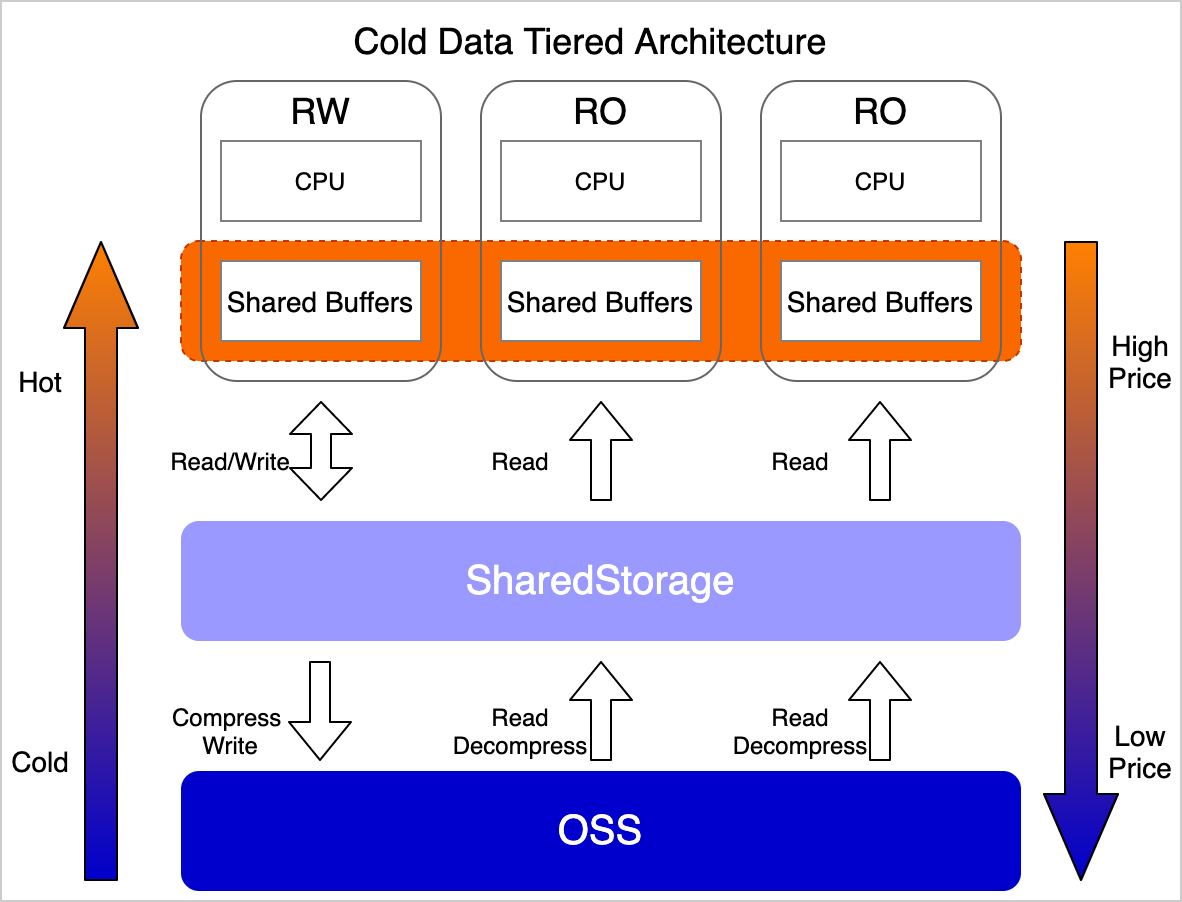
Data moves through three stages:
Ingest: Data is written to EBS (high-performance disk storage).
Archive: Data is moved to OSS based on age, type, or access frequency — using SQL commands or scheduled jobs.
Query: SQL queries access both EBS and OSS data transparently. The materialized cache serves frequently accessed cold data at near-disk speeds.
Technical advantages
| Dimension | Details |
|---|---|
| Cost | OSS storage costs less than 10% of EBS. Data compression reduces the data volume transferred to OSS — with a general compression ratio of 20–40%, a spatio-temporal data compression ratio of 60–70%, and an average compression ratio of 50%. |
| Performance | The materialized cache provides 90% of disk performance for update and insert operations, and 80% for point queries. Analytical workloads typically see a 1.76x increase in query time — acceptable for non-real-time scenarios. |
| Transparency | CRUD operations, index scans, and join queries work without SQL changes after data is moved to OSS. |
| Reliability | OSS provides 99.9999999999% data reliability and 99.995% availability. Snapshot backups use copy-on-write (COW), completing in seconds with minimal storage overhead. |
| Flexibility | Store at table, field, or partition granularity. Mix storage combinations: table data in OSS with indexes on EBS, LOB columns in OSS with remaining columns on EBS, or expired partitions in OSS with hot partitions on EBS. |
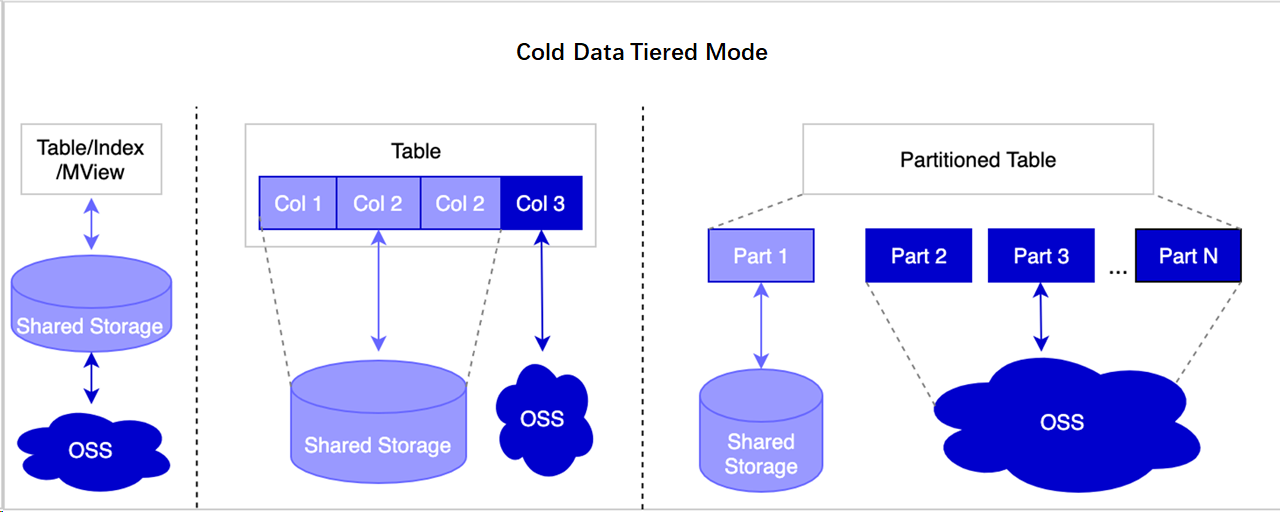
When to use each storage combination
Choose a storage combination based on your access pattern and performance requirements:
| Scenario | Recommended combination | Performance impact |
|---|---|---|
| Non-real-time statistical analysis (e.g., NDVI, aggregations) | Table data in OSS, indexes on EBS | ~76% slower than disk queries |
| Field-level LOB archival (images, JSON, text blobs) | LOB columns in OSS, other columns on EBS | Transparent; cache warms on access |
| Time-series partition archival (trajectory, logs) | Expired partitions in OSS, hot partitions on EBS | Near-transparent with cache; no SQL changes |
| Query speed is critical | Keep data on EBS | No performance impact |
Polymorphic tiered storage works best for data with decreasing access frequency over time. For data that must be accessed at high frequency with low latency, keep it on EBS.
Best practices
The following examples demonstrate three common use cases.
Case 1: Automatically archive expired partitions to cold storage
Trajectory data is stored in a monthly partitioned table. Partitions older than three months are automatically moved to OSS using a scheduled job.
Prerequisites
Before you begin, make sure you have:
A PolarDB for PostgreSQL cluster (version 14 or later, as polymorphic tiered storage was developed based on PolarDB for PostgreSQL 14)
A test database (see )
Privileged account access to the
postgresdatabase for pg_cron setup
Set up the partitioned table
Create a partitioned table and insert test data:
-- Create a partitioned table
CREATE TABLE traj(
tr_id serial,
tr_lon float,
tr_lat float,
tr_time timestamp(6)
)PARTITION BY RANGE (tr_time);
CREATE TABLE traj_202301 PARTITION OF traj
FOR VALUES FROM ('2023-01-01') TO ('2023-02-01');
CREATE TABLE traj_202302 PARTITION OF traj
FOR VALUES FROM ('2023-02-01') TO ('2023-03-01');
CREATE TABLE traj_202303 PARTITION OF traj
FOR VALUES FROM ('2023-03-01') TO ('2023-04-01');
CREATE TABLE traj_202304 PARTITION OF traj
FOR VALUES FROM ('2023-04-01') TO ('2023-05-01');
-- Insert test data
INSERT INTO traj(tr_lon,tr_lat,tr_time) values(112.35, 37.12, '2023-01-01');
INSERT INTO traj(tr_lon,tr_lat,tr_time) values(112.35, 37.12, '2023-02-01');
INSERT INTO traj(tr_lon,tr_lat,tr_time) values(112.35, 37.12, '2023-03-01');
INSERT INTO traj(tr_lon,tr_lat,tr_time) values(112.35, 37.12, '2023-04-01');
-- Create an index
CREATE INDEX traj_idx on traj(tr_id);Enable OSS archival utilities
Run this in the test database to enable the polar_osfs_toolkit extension, which provides one-click archival functions for tables, indexes, and partitions:
CREATE extension polar_osfs_toolkit;Set up the pg_cron extension
Connect to the postgres database with a privileged account. Only privileged accounts can create pg_cron in the postgres database.
-- Only privileged accounts can execute this statement in the postgres database
CREATE EXTENSION pg_cron;For more information, see pg_cron.
Schedule the archival job
Connect to the postgres database with a privileged account and create a scheduled task named task1. This task calls polar_alter_subpartition_to_oss to move partitions older than three months to OSS automatically.
-- Schedule the task (runs every minute in this test example)
SELECT cron.schedule_in_database('task1', '* * * * *', 'select polar_alter_subpartition_to_oss(''traj'', 3);', 'db01');Expected output:
schedule_in_database
----------------------
1The* * * * *schedule runs every minute and is intended for testing only. In production, adjust the cron expression to match your archival frequency — for example,0 2 * * *to run daily at 2:00 AM.
Verify the archival result
Check the storage location of an archived partition using psql in the test database:
\d+ traj_202301Expected output (key field highlighted):
Table "public.traj_202301"
Column | Type | ...
---------+--------------------------------+ ...
tr_id | integer | ...
tr_lon | double precision | ...
tr_lat | double precision | ...
tr_time | timestamp(6) without time zone | ...
Partition of: traj FOR VALUES FROM ('2023-01-01 00:00:00') TO ('2023-02-01 00:00:00')
...
Tablespace: "oss" -- Partition is now stored in OSS
Access method: heapCheck the historical execution records in the postgres database:
SELECT * FROM cron.job_run_details;Archived partitions no longer occupy EBS disk space. CRUD operations continue to work without any SQL changes.
Case 2: Store LOB fields in OSS for a non-partitioned table
Large objects (LOBs) include BLOB, TEXT, JSON, JSONB, ANYARRAY, and spatio-temporal data types. This example stores a TEXT column in OSS while keeping the rest of the table on EBS — enabling field-level hot and cold data separation.
Create the table
CREATE TABLE blob_table(id serial, val text);Move the LOB column to OSS
ALTER TABLE blob_table ALTER COLUMN val SET (storage_type='oss');This sets OSS as the storage location for all new values written to the val column.
Insert data and verify the storage location
Insert data:
INSERT INTO blob_table(val) VALUES((SELECT string_agg(random()::text, ':') FROM generate_series(1, 100000)));Verify the val column is stored in OSS:
WITH tmp AS (
SELECT 'pg_toast_'||b.oid||'_'||c.attnum AS tblname
FROM pg_class b, pg_attribute c
WHERE b.relname='blob_table' AND c.attrelid=b.oid AND c.attname='val'
)
SELECT t.spcname AS storage_engine
FROM pg_tablespace t, pg_class r, tmp m
WHERE r.relname = m.tblname AND t.oid=r.reltablespace;Expected output:
storage_engine
----------------
oss
(1 row)TheALTER COLUMNstatement only affects data inserted after it runs. Existing data stays on EBS until you runVACUUM FULL, which rewrites the table and moves historical LOBs to OSS. If you skipVACUUM FULL, historical data remains on EBS and only new inserts go to OSS. RunningVACUUM FULLlocks the table for reads and writes until completion — plan accordingly for large tables.
Case 3: Cost-effective spatio-temporal analysis with OSS
Remote sensing image (raster data) analysis is a common spatio-temporal workload. This example shows how storing raster block data in OSS reduces costs while keeping analysis results comparable.
This example uses advanced GanosBase features. Focus on the final cost and performance comparison if you want to skip intermediate steps.
Prerequisites
Before you begin, make sure you have:
A PolarDB for PostgreSQL cluster with the
ganos_rasterextension availableFour Landsat remote sensing images (
.TIFformat)
Import remote sensing images
Create a test database named
rastdb.Prepare data. This example uses four Landsat remote sensing images:

Create the
ganos_rasterextension:CREATE EXTENSION ganos_raster CASCADE;For more information, see Raster model.
Import the images:
CREATE TABLE raster_table (id integer, rast raster); INSERT INTO raster_table VALUES (1, ST_ImportFrom('rbt','/home/postgres/LC08_L1TP_113028_20190912_20190917_01_T1.TIF')); INSERT INTO raster_table VALUES (2, ST_ImportFrom('rbt','/home/postgres/LC08_L1TP_113029_20191030_20191114_01_T1.TIF')); INSERT INTO raster_table VALUES (3, ST_ImportFrom('rbt','/home/postgres/LC08_L1TP_114028_20191005_20191018_01_T1.TIF')); INSERT INTO raster_table VALUES (4, ST_ImportFrom('rbt','/home/postgres/LC08_L1TP_114029_20200905_20200917_01_T1.TIF'));
Calculate disk usage
In GanosBase, raster data stores metadata in the base table and block data in a separate block table. Create this function to calculate the block data size on disk (excluding any blocks already in OSS):
CREATE OR REPLACE FUNCTION raster_data_internal_total_size( rast_table_name text, rast_column_name text)
RETURNS int8 AS $$
DECLARE
sql text;
sql2 text;
rec record;
size int8;
totalsize int8;
tbloid Oid;
BEGIN
size := 0;
totalsize := 0;
-- Query the block data table of the raster object
sql = format('select distinct(st_datalocation(%s)) as tblname from %s where st_rastermode(%s) = ''INTERNAL'';', rast_column_name, rast_table_name, rast_column_name);
for rec in
execute sql
loop
sql2 = format('select a.oid from pg_class a, pg_tablespace b where a.reltablespace = b.oid and b.spcname=''oss'' and a.relname=''%s'';', rec.tblname);
execute sql2 into tbloid;
if (tbloid > 0) then
size := 0;
else
-- Calculate the size of each data table
sql2 = format('select pg_total_relation_size(''%s'');',rec.tblname);
execute sql2 into size;
end if;
totalsize := (totalsize + size);
end loop;
return totalsize;
END;
$$ LANGUAGE plpgsql;Run the function to check initial disk usage:
SELECT pg_size_pretty(raster_data_internal_total_size('raster_table','rast'));Expected output:
pg_size_pretty
----------------
1319 MB
(1 row)Calculate NDVI on disk (baseline)
Normalized Difference Vegetation Index (NDVI) analysis requires mosaicking the four images before computing the index. Run this with data on EBS and record the time:
CREATE TABLE rast_mapalgebra_result(id integer, rast raster);
INSERT INTO rast_mapalgebra_result SELECT 1, ST_MapAlgebra(
ARRAY(SELECT st_mosaicfrom(ARRAY(SELECT rast FROM raster_table ORDER BY id), 'rbt_mosaic','','{"srid":4326,"cell_size":[0.005,0.005]')),
'[{"expr":"([0,3] - [0,2])/([0,3] + [0,2])","nodata": true, "nodataValue":0}]',
'{"chunktable":"rbt_algebra","celltype":"32bf"}');Expected output:
INSERT 0 1
Time: 39874.189 ms (00:39.874)For more information about ST_MosaicFrom, see ST_MosaicFrom.
Archive block data to OSS
Create a function to move block data from all raster objects in a table to OSS. The metadata stays on EBS; only block data is archived.
CREATE OR REPLACE FUNCTION raster_data_alter_to_oss( rast_table_name text, rast_column_name text)
RETURNS VOID AS $$
DECLARE
sql text;
sql2 text;
rec record;
BEGIN
-- Query the data table of the raster object
sql = format('select distinct(st_datalocation(%s)) as tblname from %s where st_rastermode(%s) = ''INTERNAL'';', rast_column_name, rast_table_name, rast_column_name);
for rec in
execute sql
loop
-- Move each block table to the OSS tablespace
sql2 = format('alter table %s set tablespace oss;',rec.tblname);
execute sql2;
end loop;
END;
$$ LANGUAGE plpgsql;Run the archival and verify the result:
SELECT raster_data_alter_to_oss('raster_table', 'rast');
-- Verify disk usage after archival
SELECT pg_size_pretty(raster_data_internal_total_size('raster_table','rast'));Expected output:
pg_size_pretty
----------------
0 bytes
(1 row)Block data is now in OSS. The 0 bytes result confirms no block data remains on EBS.
Recalculate NDVI from OSS
Run the same NDVI calculation with block data in OSS:
INSERT INTO rast_mapalgebra_result SELECT 2, ST_MapAlgebra(
ARRAY(SELECT st_mosaicfrom(ARRAY(SELECT rast FROM raster_table ORDER BY id), 'rbt_mosaic','','{"srid":4326,"cell_size":[0.005,0.005]')),
'[{"expr":"([0,3] - [0,2])/([0,3] + [0,2])","nodata": true, "nodataValue":0}]',
'{"chunktable":"rbt_algebra","celltype":"32bf"}');Expected output:
INSERT 0 1
Time: 69414.201 ms (01:09.414)
Cost and performance comparison
| Metric | EBS (disk) | OSS |
|---|---|---|
| Storage volume | 1,319 MB | ~1,012 MB (after compression) |
| Monthly storage cost | USD 0.31 (at USD 0.238/GB) | USD 0.023 (at USD 0.0232/GB, ZRS) |
| Cost ratio | 10 | 1 |
| NDVI calculation time | 39 seconds | 69 seconds |
| Performance ratio | 1 | 1.76x slower |
OSS storage costs less than one-tenth of EBS. The computing performance loss is less than 100% — a 1.76x increase in query time is acceptable for non-real-time statistical analysis. This is the core trade-off of polymorphic tiered storage.
What's next
Learn about OSS pricing tiers: Overview of cold data
Review storage cost details: PSL4 vs PSL5 comparison
Explore raster data operations: Raster model