WAL parallel replay accelerates data synchronization on standby nodes by splitting write-ahead log (WAL) replay into concurrent subtasks, reducing recovery time and replica lag across your PolarDB cluster.
Enable the feature with a single parameter in postgresql.conf:
polar_enable_parallel_replay_standby_mode = ONPrerequisites
Before you enable WAL parallel replay, verify that your cluster meets the following requirements:
PolarDB for PostgreSQL (Compatible with Oracle) with Oracle syntax compatibility 2.0
Minor engine version 2.0.14.5.1.0 or later
To check your minor engine version, run SHOW polardb_version; in the PolarDB console or view it on the Version management page. If your version does not meet the minimum requirement, upgrade the minor engine version before enabling this feature.
How WAL parallel replay works
Why parallelism helps
WAL replay is on the critical path for high availability (HA). On a read-only node, the LogIndex background worker and a backend process already replay WAL records in different buffers—an implicit form of parallelism. WAL parallel replay applies the same concept to the standard log replay path, reducing latency in three scenarios:
Crash recovery for the primary database, read-only nodes, and secondary databases
Continuous WAL replay by the LogIndex background worker on a read-only node
Continuous WAL replay by the Startup process on a secondary database
Parallel task model
A single WAL log can modify multiple data blocks. WAL parallel replay decomposes each log into the smallest possible subtasks: replaying one WAL log on one data block. Formally, the i-th WAL log (with log sequence number LSN<sub>i</sub>) that modifies m blocks produces m subtasks:
Task(i,j) = LSN(i) → Block(i,j) where j ∈ [0, m]Subtasks that operate on different data blocks have no dependency on each other and can run in parallel. For example, given three WAL logs that modify overlapping blocks:
| Subtask group | Tasks | Relationship |
|---|---|---|
| Group A | Task(0,0), Task(1,0) | Same block — run sequentially within the group |
| Group B | Task(0,1), Task(1,1) | Same block — run sequentially within the group |
| Group C | Task(0,2), Task(2,0) | Same block — run sequentially within the group |
Groups A, B, and C can all run in parallel with each other because they operate on different data blocks. Within each group, tasks run in order to maintain block-level consistency.
Parallel task execution framework
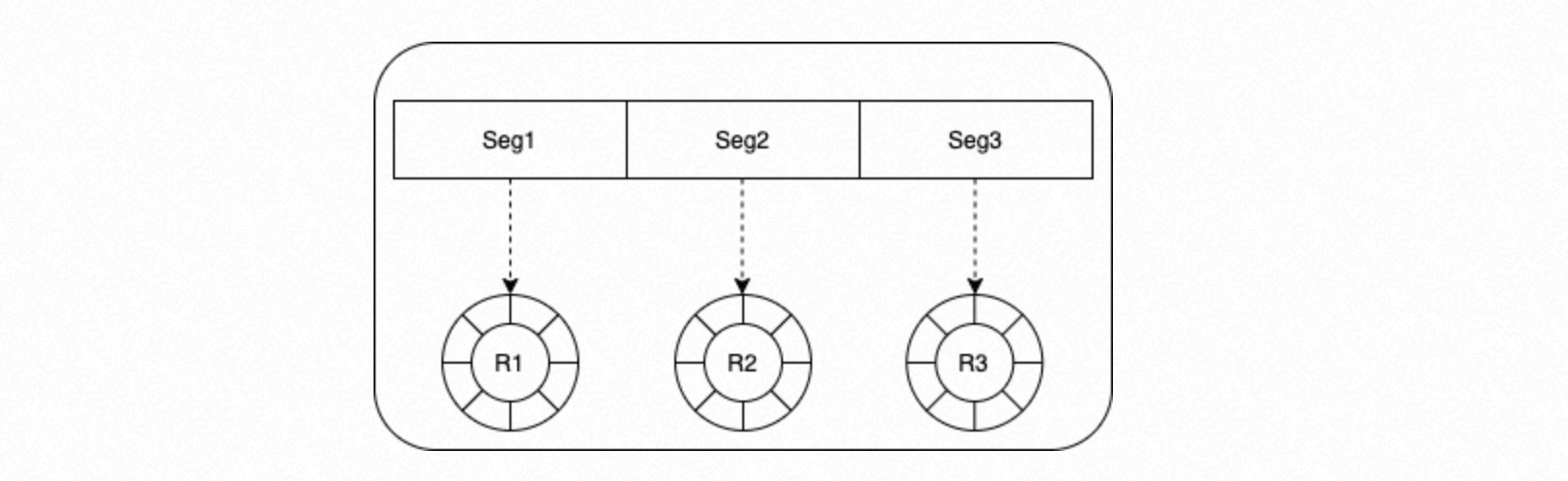
The framework distributes subtasks across worker processes using shared memory divided into per-process circular queues.
Dispatcher process
The Dispatcher process controls scheduling. It maintains three data structures:
| Data structure | Purpose |
|---|---|
| Task HashMap | Maps each Task Tag to the ordered list of tasks with that tag. Tasks sharing a Task Tag have a dependency and must run sequentially. |
| Task Running Queue | Tracks tasks currently being executed. |
| Task Idle Nodes | Tracks idle Task Node slots in each worker's circular queue. |
The Dispatcher uses two scheduling policies:
Affinity-first: If a task with the same Task Tag is already running, assign the new task to the same worker process that is handling the last task in that tag's list. This reduces inter-process synchronization overhead by keeping dependent tasks on one process.
Round-robin fallback: If the preferred worker's queue is full, or no task with the same Task Tag is running, assign the task to the next available worker in sequence. This distributes load evenly across the process group.
Task Node states
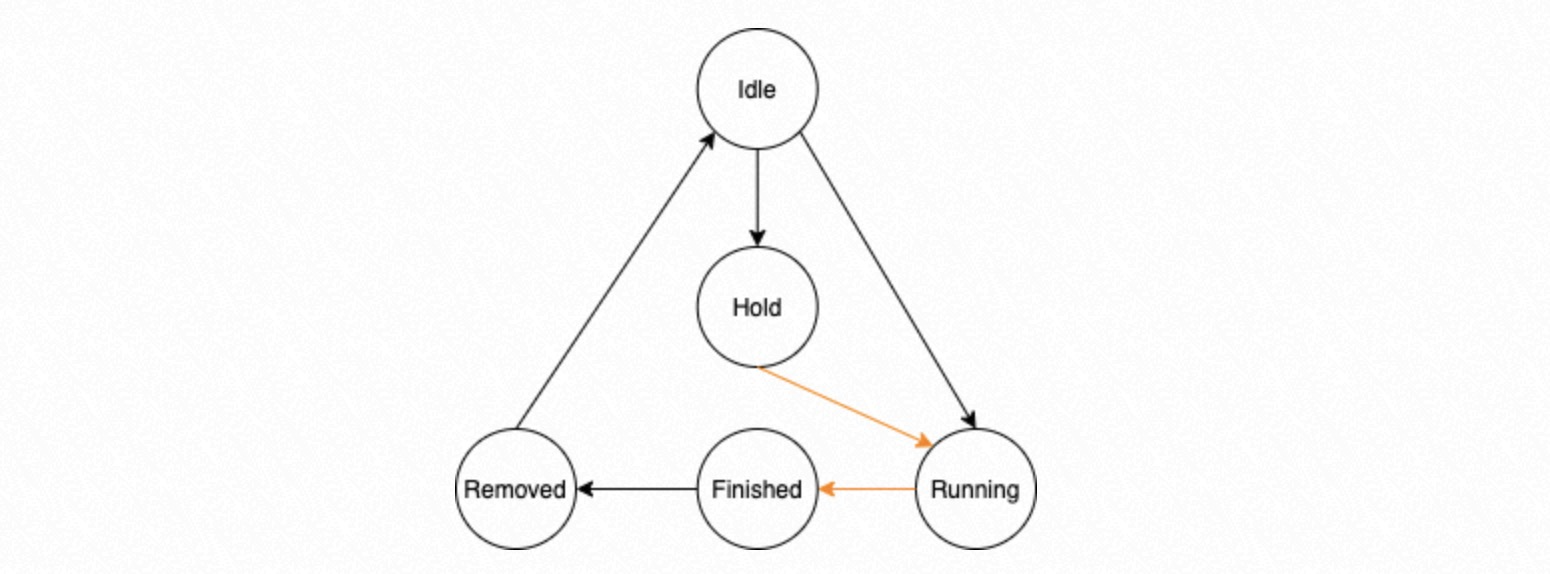
Each slot in a circular queue is a Task Node. A Task Node moves through five states:
| State | Description |
|---|---|
| Idle | Not assigned a task. |
| Running | Assigned a task; waiting to execute or executing. |
| Hold | Has a dependency on a preceding task; waiting for that task to finish. |
| Finished | A worker process has completed the task. |
| Removed | All prerequisite tasks are also Finished. The Dispatcher removes the task and its prerequisites from the management struct, ensuring dependent results are handled in the correct order. |
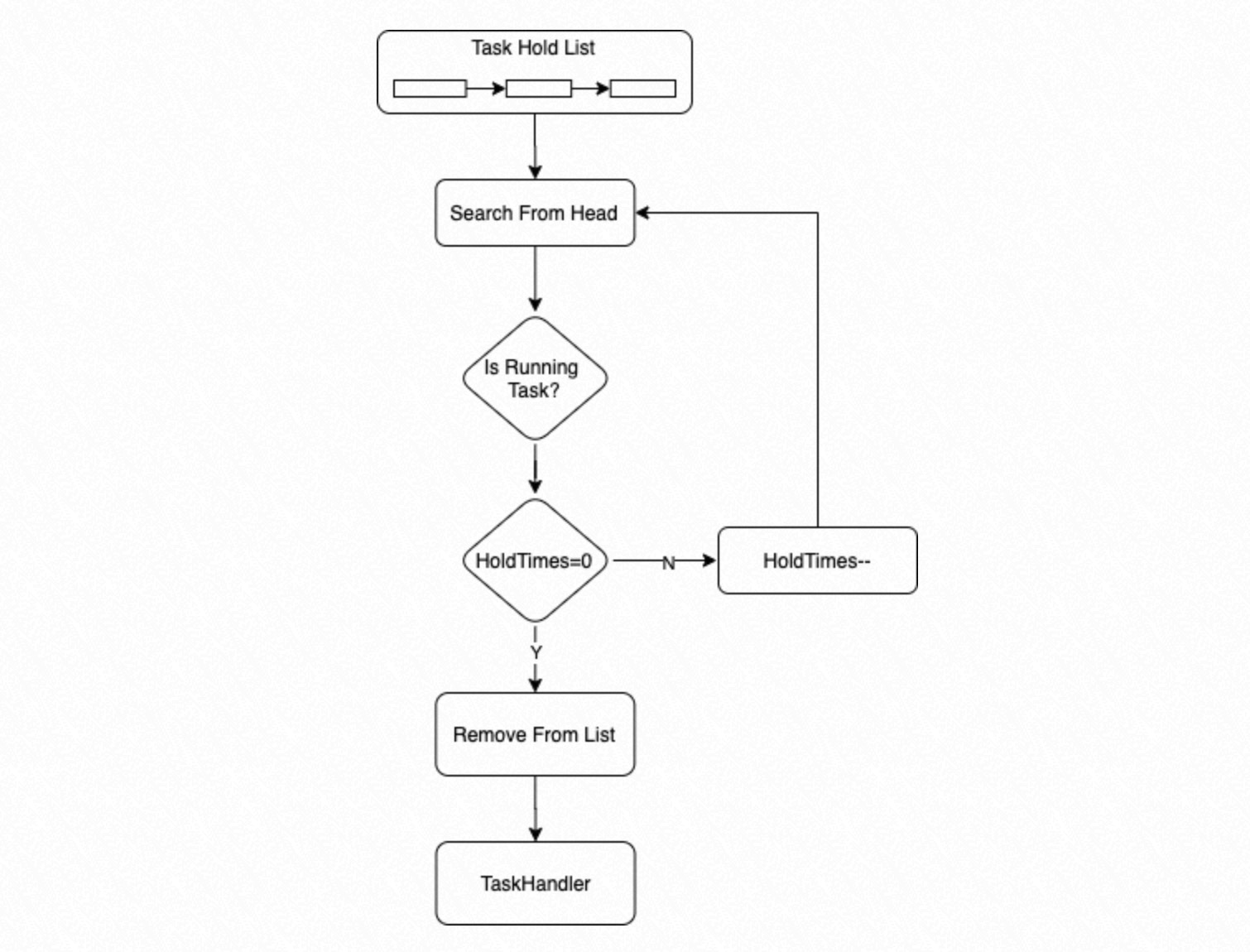
State transitions driven by the Dispatcher process appear as black lines in the state machine diagram. Transitions driven by the parallel replay process group appear as orange lines.
Process group
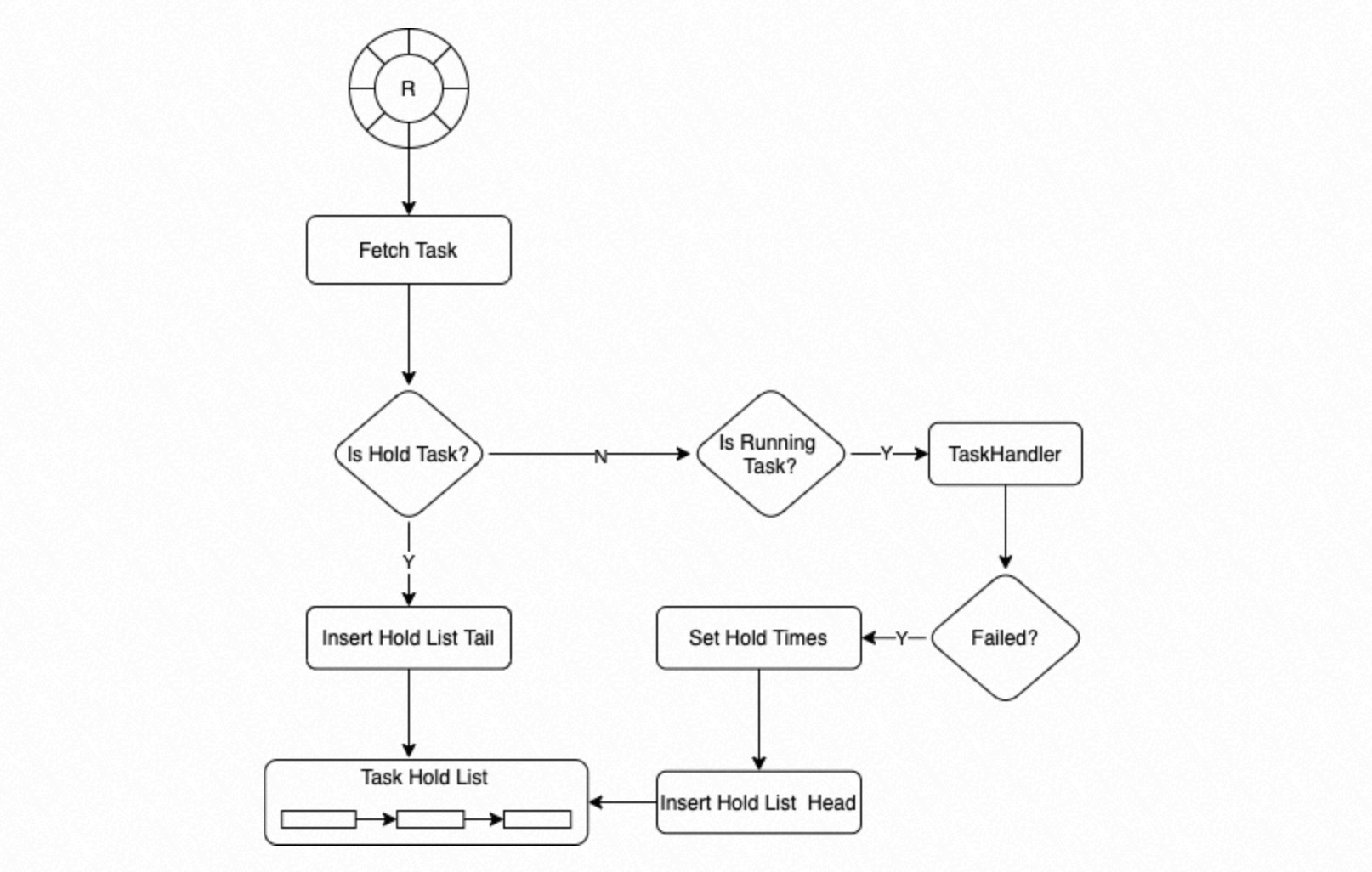
Each worker process in the process group loops over its circular queue and processes Task Nodes based on state:
Hold: Insert the Task Node at the tail of the Hold List and continue.
Running: Call
TaskHandlerto execute the task. IfTaskHandlerfails, set the retry count to the default (3) and insert the Task Node at the head of the Hold List.
The process also scans the Hold List from the beginning on each iteration:
If a task's state is Running and its wait count is 0, execute the task immediately.
If the wait count is greater than 0, decrement it by 1 and skip.
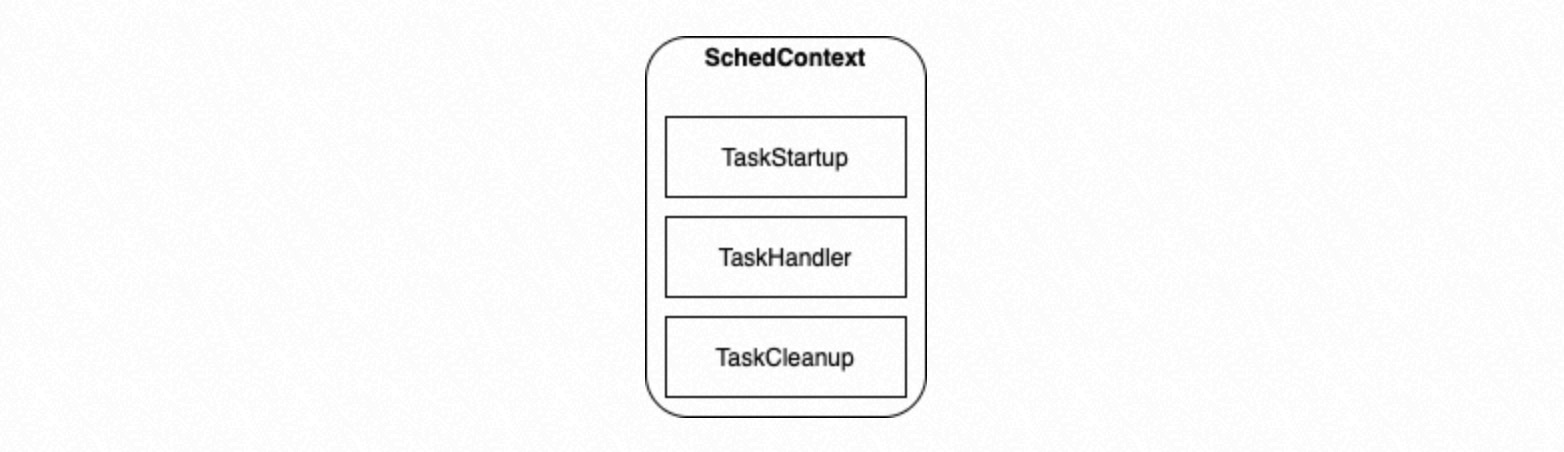
When the process group is initialized, SchedContext binds three function pointers to the process:
| Function | Description |
|---|---|
TaskStartup | Runs once before the process begins executing tasks. |
TaskHandler | Executes a specific task based on the incoming Task Node. |
TaskCleanup | Runs cleanup actions before the process exits. |
WAL parallel replay workflow
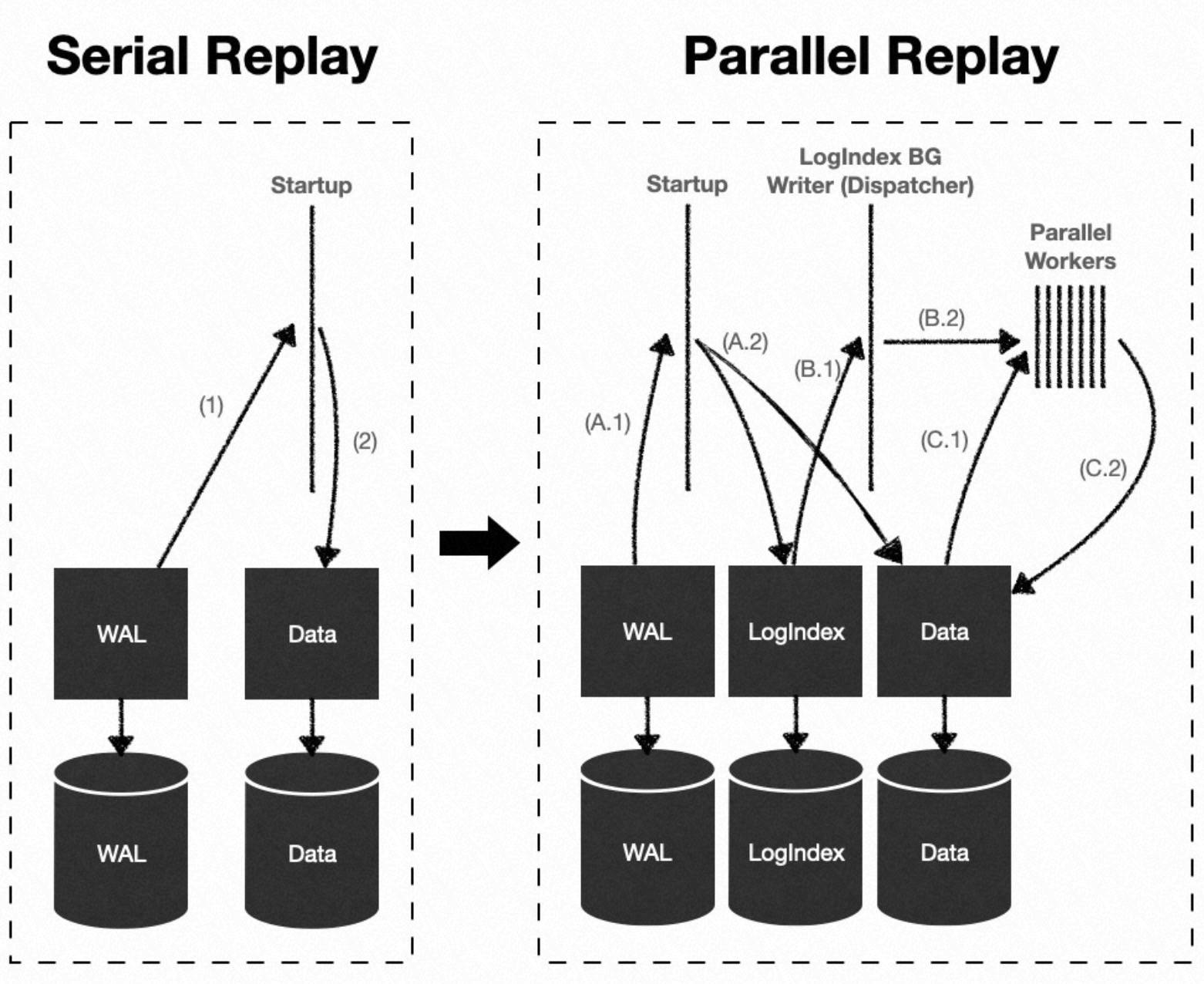
LogIndex records the mapping between WAL logs and the data blocks they modify, indexed by LSN. During continuous replay on a standby node, four process roles coordinate:
| Role | Responsibility |
|---|---|
| Startup process | Parses WAL logs and builds LogIndex data. Does not replay WAL logs directly. |
| LogIndex BGW replay process | Acts as the Dispatcher. Uses LSNs to retrieve LogIndex data, builds {LSN → PageTag} Task Nodes in LogIndex insertion order, and assigns them to the parallel replay process group. PageTag serves as the Task Tag. |
| Parallel replay process group | Executes replay subtasks. Each subtask replays one WAL log on one data block. |
| Backend process | When reading a data block, retrieves the LogIndex data for that PageTag to get the list of LSNs that modified the block, then replays the full log chain on that block. |
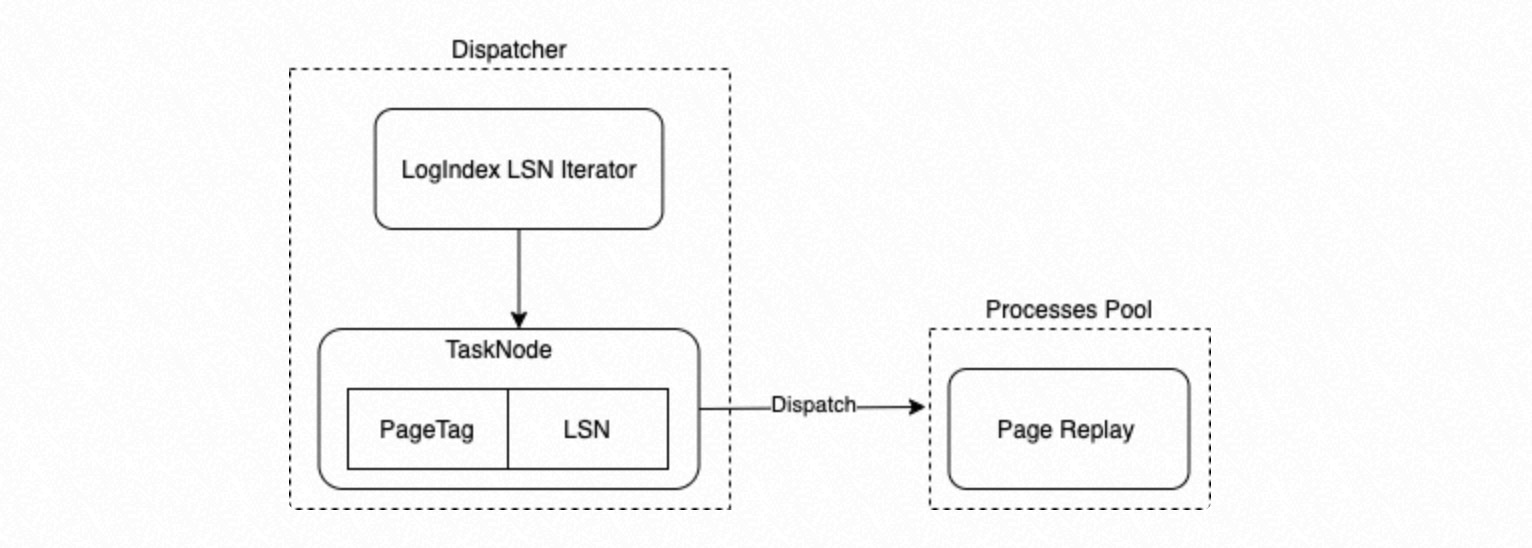
Scheduling diagram
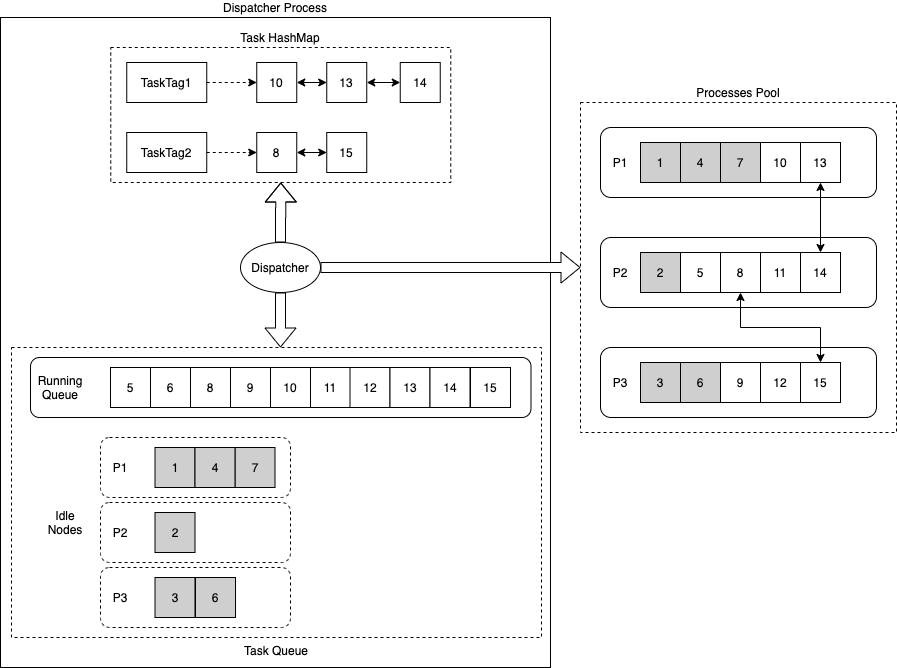
Key concepts
| Term | Definition |
|---|---|
| Block (data block) | A data block. |
| WAL (write-ahead logging) | The mechanism that records changes before applying them to data blocks, ensuring crash recovery. |
| Task Node | A slot in a worker's circular queue that holds one subtask. |
| Task Tag | A classification identifier for subtasks. Subtasks sharing the same Task Tag must execute in sequence. |
| Hold List | A per-process linked list used to schedule and retry subtasks that are waiting on a dependency. |
Enable WAL parallel replay
Add the following parameter to postgresql.conf on the standby node:
polar_enable_parallel_replay_standby_mode = ON