Each cluster in a global database network (GDN) — including the primary cluster and secondary clusters — has its own cluster endpoint. Connect your application to the nearest cluster endpoint based on region. The GDN automatically handles read/write splitting: read requests go to the local cluster, and write requests are forwarded to the primary cluster.
How request routing works
Routing is determined by the database proxy configuration of each cluster. Connect to the cluster endpoint — read/write requests are automatically routed based on the following logic:
| Target | Routed requests |
|---|---|
| Primary node of the primary cluster only | DML (INSERT, UPDATE, DELETE), DDL (create/delete tables or databases, alter schemas), SHOW, transaction commands (BEGIN, COMMIT), LISTEN/UNLISTEN/NOTIFY, ANALYZE, two-phase commit protocol, requests inside a transaction, function definitions and calls, requests using temporary tables, multiple statements, PREPARE statements with writes |
| Read-only nodes or the primary node | Read requests outside a transaction, EXPLAIN, PREPARE statements with reads |
| All nodes | USE, DISCARD, DEALLOCATE |
Behavior for transaction-related requests may vary based on the transaction splitting configuration. Behavior for function calls may vary based on the user-defined function routing rule configuration.
If session consistency is enabled, some read requests may be routed to the primary node of the primary cluster to maintain data consistency.
Endpoint compatibility
Not all endpoint types support GDN read/write splitting. Verify your endpoint configuration before connecting:
| Endpoint type | Read/Write mode | GDN read/write splitting |
|---|---|---|
| Cluster endpoint | Read/Write (Automatic Read/Write Splitting) | Supported |
| Custom endpoint | Read/Write (Automatic Read/Write Splitting) | Supported |
| Primary endpoint | — | Not supported |
| Custom endpoint | Read-only | Not supported |
For secondary clusters, set Primary Node Accepts Read Requests to No and Consistency Level to Eventual Consistency (Weak) to minimize the impact of replication delay.
View a cluster endpoint
Log on to the PolarDB console. In the left navigation pane, click Global Database Network (GDN).
On the Global Database Network (GDN) page, find the target GDN and click its Global Database Network ID to go to the GDN details page.
In the Cluster List section, find the target secondary cluster and click View in the Cluster Endpoint column. You can only view the endpoint information for the default cluster, including the VPC and Internet addresses.

To view additional endpoints, click View Or Manage More Endpoints. You are redirected to the cluster details page, where all endpoints are listed in the Database Connection section.
Connect to a GDN cluster
Connect to the nearest cluster endpoint from your application. The GDN handles read/write routing automatically. The following sections cover the available connection methods.
Use DMS
Data Management (DMS) is a graphical database management tool provided by Alibaba Cloud. It supports data management, schema management, user management, security audit, data trends, data tracking, business intelligence (BI) charts, performance optimization, and server management. Use DMS to manage your PolarDB cluster directly from the browser.
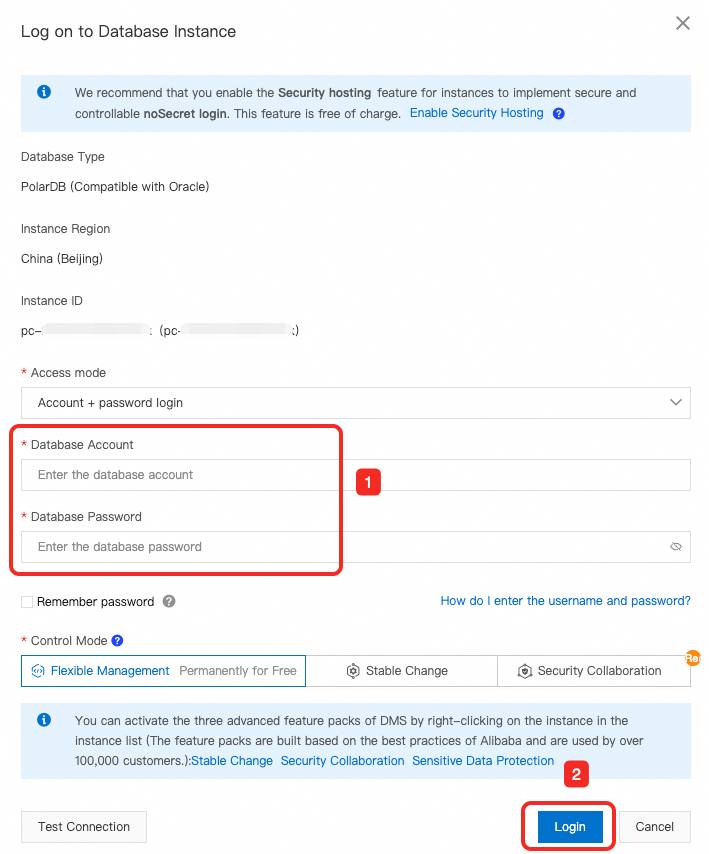
Log on to the PolarDB console. Click the cluster ID to go to its Basic Information page. In the upper-right corner, click Log On To Database.

In the dialog box, enter the database account and password for the cluster, then click Login.
After logging on, go to Database Instances > Instances Connected in the left navigation pane to manage the cluster.

Use pgAdmin
The following steps use pgAdmin 4 v9.0 to connect to a PolarDB cluster.
Download and install the pgAdmin 4 client.
Open pgAdmin 4, right-click Servers, and select Register > Server....

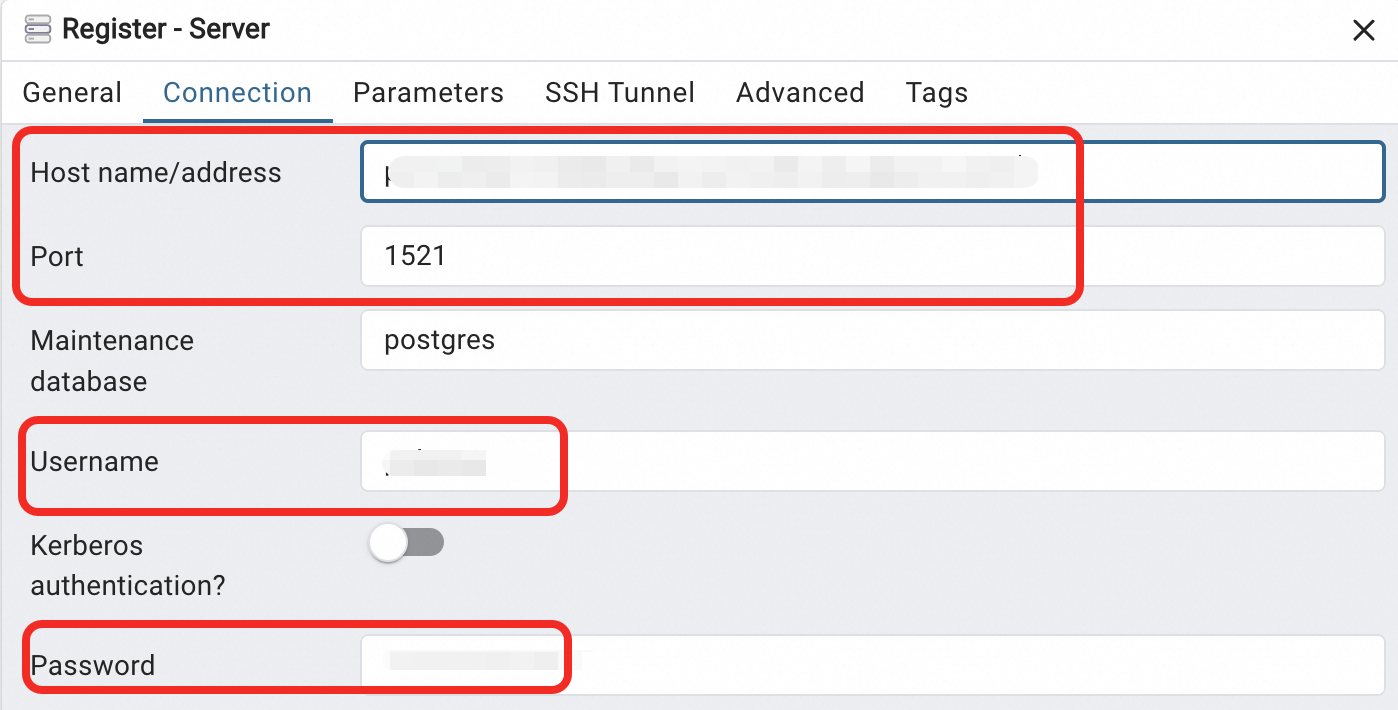
On the General tab, set a connection name. Switch to the Connection tab, fill in the cluster connection details, and click Save.
Parameter Description Host name/address The cluster endpoint of the PolarDB cluster. Use the Private endpoint if your client is on an ECS instance in the same VPC. Use the Public endpoint for on-premises access. Port The port number. The default is 1521. Username The database account for the cluster. Password The password for the database account. 
Verify the connection. A successful connection displays the cluster tree in pgAdmin.

postgres is the default system database. Do not perform any operations on this database.Use psql
Download psql from PostgreSQL Downloads, or use the psql bundled with PolarDB-Tools. The connection method is the same on Windows and Linux.
Syntax:
psql -h <host> -p <port> -U <username> -d <dbname>| Parameter | Description |
|---|---|
host | The cluster endpoint. Use the Private endpoint for ECS instances in the same VPC. Use the Public endpoint for on-premises access. |
port | The port number. The default is 1521. |
username | The database account. |
dbname | The database name. |
Example:
psql -h pc-xxx.rwlb.rds.aliyuncs.com -p 1521 -U testusername -d postgresFor more information about psql options, see the psql documentation.
Connect from code
PolarDB for PostgreSQL (Compatible with Oracle) uses the standard PostgreSQL wire protocol. Use any PostgreSQL-compatible driver and replace the connection parameters (endpoint, port, account, and password) with your GDN cluster values.
Java
Use the PostgreSQL JDBC driver in a Maven-based project.
Add the driver dependency to
pom.xml:<dependency> <groupId>org.postgresql</groupId> <artifactId>postgresql</artifactId> <version>42.2.18</version> </dependency>Connect to the cluster. Replace
<HOST>,<PORT>,<USER>,<PASSWORD>,<DATABASE>,<YOUR_TABLE_NAME>, and<YOUR_TABLE_COLUMN_NAME>with your cluster values.import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.Statement; public class PolarDBConnection { public static void main(String[] args) { String url = "jdbc:postgresql://<HOST>:<PORT>/<DATABASE>"; String user = "<USER>"; String password = "<PASSWORD>"; try { // Load the PostgreSQL JDBC driver. Class.forName("org.postgresql.Driver"); // Establish the connection. Connection conn = DriverManager.getConnection(url, user, password); // Create a Statement object. Statement stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery("SELECT * FROM <YOUR_TABLE_NAME>"); while (rs.next()) { System.out.println(rs.getString("<YOUR_TABLE_COLUMN_NAME>")); } // Close resources. rs.close(); stmt.close(); conn.close(); } catch (Exception e) { e.printStackTrace(); } } }
Python
Use the psycopg2 library with Python 3.
Install psycopg2:
pip3 install psycopg2-binaryConnect to the cluster. Replace
<HOST>,<PORT>,<USER>,<PASSWORD>,<DATABASE>, and<YOUR_TABLE_NAME>with your cluster values.import psycopg2 try: conn = psycopg2.connect( host="<HOST>", # Cluster endpoint database="<DATABASE>", user="<USER>", password="<PASSWORD>", port="<PORT>" ) cursor = conn.cursor() cursor.execute("SELECT * FROM <YOUR_TABLE_NAME>") records = cursor.fetchall() for record in records: print(record) except Exception as e: print("Error:", e) finally: if 'cursor' in locals(): cursor.close() if 'conn' in locals(): conn.close()
Go
Use the database/sql package with the lib/pq driver in Go 1.23.0.
Install the driver:
go get -u github.com/lib/pqConnect to the cluster. Replace
<HOST>,<PORT>,<USER>,<PASSWORD>,<DATABASE>, and<YOUR_TABLE_NAME>with your cluster values.package main import ( "database/sql" "fmt" "log" _ "github.com/lib/pq" // Initialize the PostgreSQL driver. ) func main() { connStr := "user=<USER> password=<PASSWORD> dbname=<DATABASE> host=<HOST> port=<PORT> sslmode=disable" db, err := sql.Open("postgres", connStr) if err != nil { log.Fatal(err) } defer db.Close() // Verify the connection. err = db.Ping() if err != nil { log.Fatal(err) } fmt.Println("Connected to PostgreSQL!") rows, err := db.Query("SELECT * FROM <YOUR_TABLE_NAME>") if err != nil { log.Fatal(err) } defer rows.Close() }
API reference
| API | Description |
|---|---|
| DescribeDBClusterEndpoints | Queries the endpoint information of a PolarDB cluster. |
| ModifyDBClusterEndpoint | Modifies endpoint properties, including read/write mode, auto-add nodes, consistency level, transaction splitting, primary node read requests, and connection pool settings. |