PolarDB buffer management controls how the primary node writes pages to shared storage, preventing read-only nodes from reading inconsistent page versions and minimizing the WAL records they need to replay.
Shared-storage consistency challenge
In a shared-storage architecture, all nodes in a PolarDB cluster—one primary node and multiple read-only nodes—read and write the same underlying physical pages. Unlike traditional streaming replication, where each replica maintains its own local copy of data, shared storage means every node sees the same page. This introduces a consistency challenge: a page on shared storage reflects a specific point in write-ahead logging (WAL) replay history, and different nodes may be at different points.
When a read-only node reads a page from shared storage, the page may be in one of two problematic states:
Future page: The page has WAL records applied beyond the read-only node's current log sequence number (LSN). For example, the read-only node has replayed WAL up to LSN 200, but the page on shared storage already reflects changes up to LSN 300.
Outdated page: The page has fewer WAL records applied than the read-only node's current LSN. For example, the read-only node is at LSN 200, but the page only reflects changes up to LSN 180.
Key concepts
| Term | Description |
|---|---|
| Buffer pool | An in-memory cache for frequently accessed data pages. Each node in a PolarDB cluster has its own buffer pool. |
| LSN | A log sequence number uniquely identifies a WAL record. LSNs increase monotonically across the system. |
| Apply LSN | The LSN of the most recent WAL record replayed on a read-only node for a specific page. |
| Oldest apply LSN | The smallest apply LSN for a page across all read-only nodes. |
| Consistency LSN | The smallest oldest LSN among all buffers for a page. All changes up to this LSN are guaranteed to be in shared storage. |
| LogIndex | A persistent hash table that maps each page to the LSNs of all WAL records generated for it. |
| Flush list | A sorted list of all dirty pages in the buffer pool, ordered by oldest LSN in ascending order. Enables O(1) consistency LSN lookup. |
| Hot buffer | A buffer that is updated so frequently that its latest LSN always exceeds the oldest apply LSN, preventing it from meeting flush conditions. |
| Copy buffer pool | A pool that holds frozen copies of hot buffers. Copies are not updated and can eventually be flushed once the oldest apply LSN catches up. |
| BGWRITER | A background writer process that scans the flush list and flushes early buffers to shared storage. |
Flushing control
Before writing a dirty page from its buffer pool to shared storage, the primary node checks whether all read-only nodes have replayed the most recent WAL record for that page. This check uses two LSN values:
Consistency LSNs
When a read-only node requests a page, it scans the page's LogIndex to find all WAL records that need to be replayed, then replays them in sequence. Pages with a long change history require replaying many WAL records, which increases read latency.
Consistency LSNs reduce this overhead. Once all changes up to a page's consistency LSN are written to shared storage, the read-only node no longer needs to replay WAL records from before that point. The primary node sends both the write LSN and the consistency LSN to each read-only node; each read-only node sends its apply LSN back to the primary. All LSNs below the consistency LSN can then be removed from the LogIndex, reducing the replay work needed on each page read.
Hot buffers
Flushing control works well for most buffers but creates a problem for frequently updated pages. If a buffer is updated often enough, its latest LSN may always be higher than the oldest apply LSN. This buffer never meets the flush condition and is called a hot buffer. If a page has hot buffers, its consistency LSN cannot advance.
PolarDB resolves this with a copy buffering mechanism: when a buffer consistently fails to meet flush conditions, PolarDB copies it to the copy buffer pool. The copy's latest LSN is frozen at the moment of copying and is not updated as the original buffer continues to receive writes. As the oldest apply LSN advances, the copy eventually meets the flush condition and is flushed to shared storage.
The flush rules when copy buffering is active:
If a buffer fails the flush condition and both the number of recent updates and the time elapsed since the latest LSN exceed their thresholds, copy the buffer to the copy buffer pool.
When the buffer is updated again and meets the flush condition, flush it to shared storage and delete its copy from the copy buffer pool.
If the buffer still fails the flush condition but its copy in the copy buffer pool meets the condition, flush the copy to shared storage.
After copying a buffer to the copy buffer pool, if the original buffer is updated again, PolarDB assigns it a new oldest LSN and moves it to the tail of the flush list.
For example: a hot buffer has oldest LSN 30 and latest LSN 500. PolarDB copies it to the copy buffer pool. The original buffer is then updated at LSN 600—its oldest LSN becomes 600 and it moves to the tail of the flush list. The copy retains latest LSN 500, which is now frozen. When the oldest apply LSN on all read-only nodes reaches 500, the copy meets the flush condition and is flushed to shared storage.
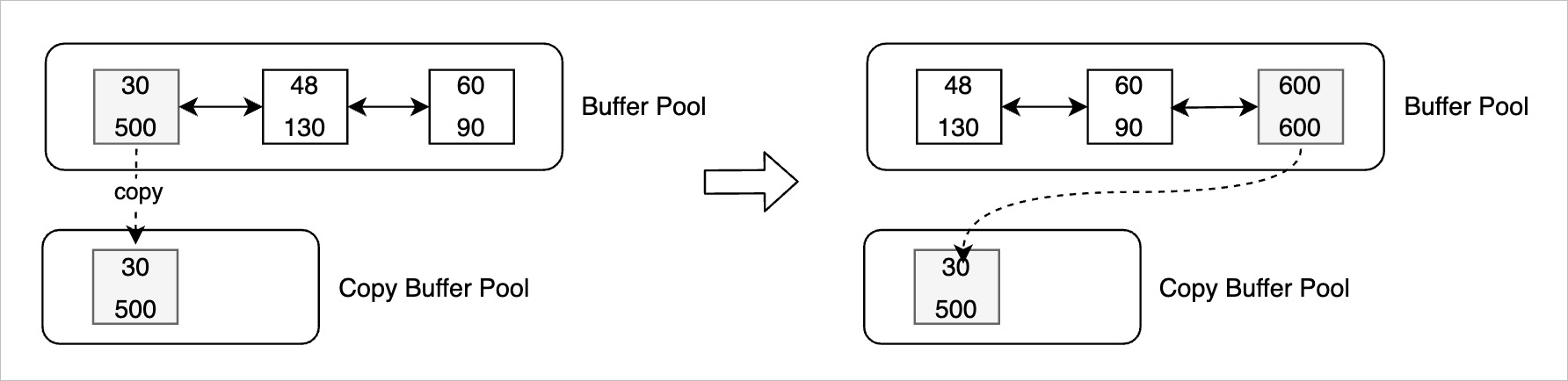
With copy buffering active, the consistency LSN is the minimum of the oldest LSN in the flush list and the oldest LSN in the copy buffer pool. The copy buffer pool can hold older LSNs than the flush list head, so both must be compared.
Lazy checkpoints
PolarDB supports consistency LSNs, which are similar to checkpoints. If regular checkpoint LSNs are used, PolarDB flushes all dirty pages in the buffer pool and other in-memory pages to shared storage, which may require a long period of time and high I/O throughput and affect normal queries. Because all changes up to the consistency LSN are already in shared storage, PolarDB can use the consistency LSN in place of a traditional checkpoint LSN: if recovery is needed, PolarDB starts replaying WAL from the consistency LSN rather than from the beginning.
PolarDB uses this property to implement lazy checkpoints: instead of flushing all dirty pages at checkpoint time, it uses the current consistency LSN as the checkpoint LSN. The underlying mechanism is the same BGWRITER process that continuously flushes dirty pages and maintains consistency LSNs.
Lazy checkpoints are incompatible with the full page write feature. Enabling full page write automatically disables lazy checkpoints.