X-Engine is an OLTP storage engine for MySQL, developed by the Database Products Business Unit of Alibaba Cloud. It uses a redesigned log-structured merge-tree (LSM tree) architecture to reduce storage costs and handle high-concurrency workloads at scale.
X-Engine is phased out. For more information, see [EOS/Discontinuation] ApsaraDB RDS for MySQL instances that run the X-Engine storage engine are no longer available for purchase from November 1, 2024.
Background
Alibaba Group has been deploying MySQL databases at scale since 2010. As data volumes grew exponentially, two problems became increasingly difficult to solve by adding servers alone:
Processing highly concurrent transactions
Storing large amounts of data cost-effectively
The root cause was a mismatch between hardware and software. Modern systems run on multi-core CPUs, cache-only memory architecture (COMA), non-uniform memory access (NUMA), and heterogeneous accelerators such as GPUs and field-programmable gate arrays (FPGAs). But database software — B-tree indexing with fixed page sizes, ARIES-based (recovery and isolation exploiting semantics) transaction recovery, and independent lock managers — was designed for slow spinning disks. According to Michael Stonebreaker (Turing Award winner) in his paper "OLTP Through the Looking Glass, and What We Found There," conventional relational databases spend less than 10% of their time actually processing data. The remaining 90% is spent waiting for locks, managing buffers, and synchronizing logs.
X-Engine was built to close that gap.
The LSM tree trade-off
Every storage engine design must balance three forms of amplification:
| Amplification | Definition | LSM tree | B-tree |
|---|---|---|---|
| Write amplification | Extra I/O beyond the logical write | Lower | Higher |
| Read amplification | Extra I/O to satisfy a read (multiple levels to merge) | Higher | Lower |
| Space amplification | Extra storage beyond the logical data size | Requires compaction to reclaim | Moderate |
LSM trees trade read amplification for write amplification. X-Engine addresses all three dimensions through tiered storage, a transaction pipeline, fine-grained compaction with data reuse, and multi-layer caching — accepting the read overhead of LSM while minimizing it as much as possible.
How X-Engine works
Data organization and tiered storage
X-Engine divides data across storage tiers based on access frequency:
Hot data (frequently accessed): stored in memory using lock-free skip lists and append-only data structures
Cold data (infrequently accessed): flushed to persistent storage tiers — non-volatile memory (NVM), SSDs, and HDDs — in order of cost and speed
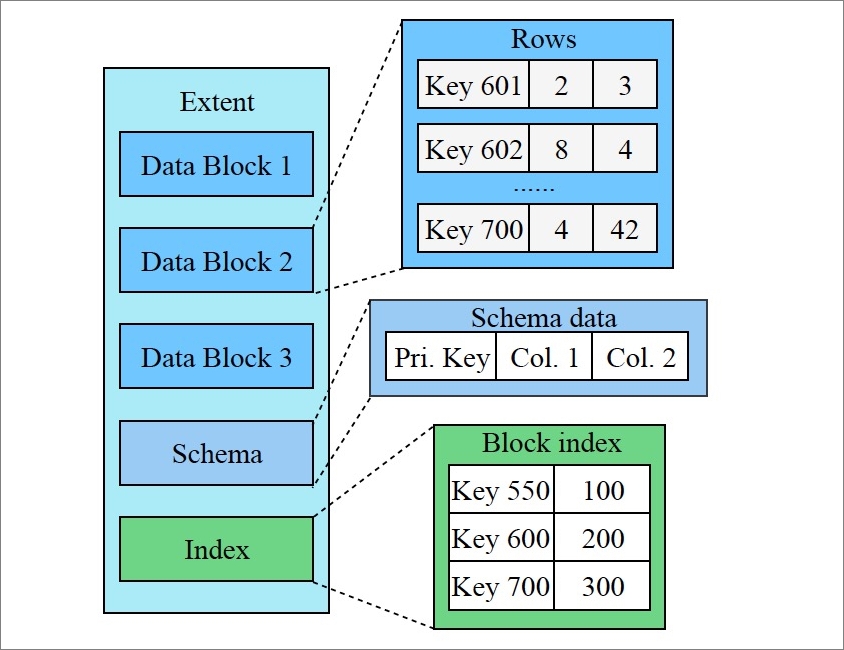
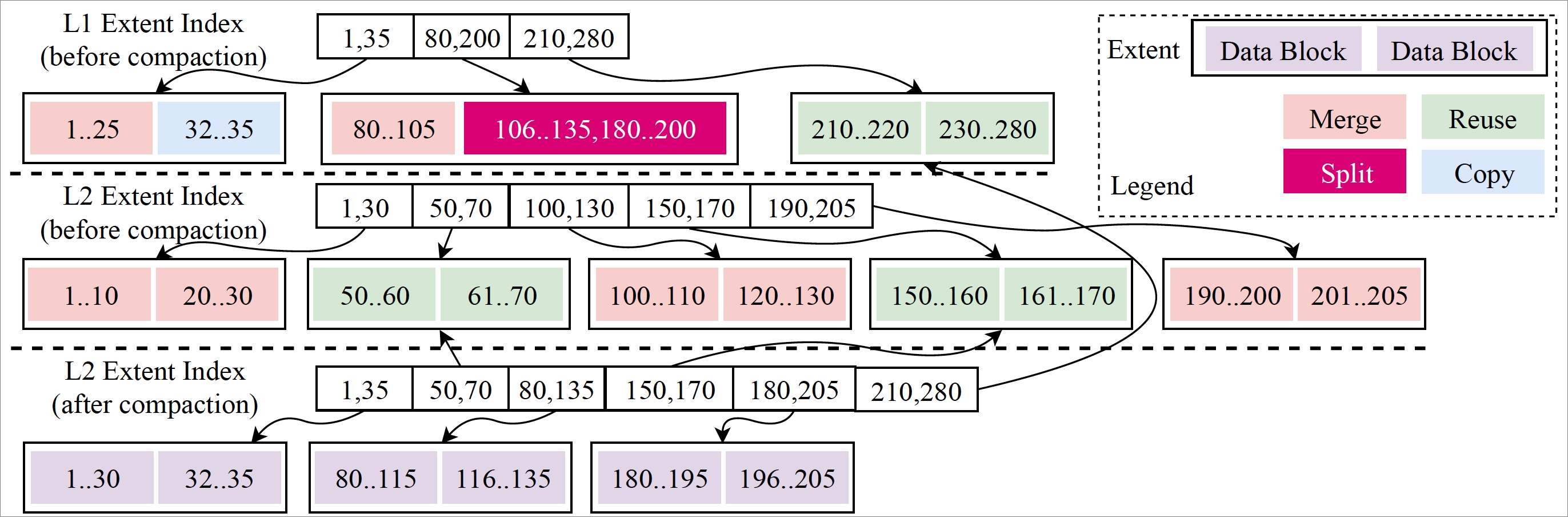
Each persistence level is divided into extents of a fixed size. An extent is a small, complete sorted string table (SSTable) that stores data with a continuous key range. Each key range is further divided into read-only, variable-length data blocks (equivalent to pages in conventional databases, but immutable).
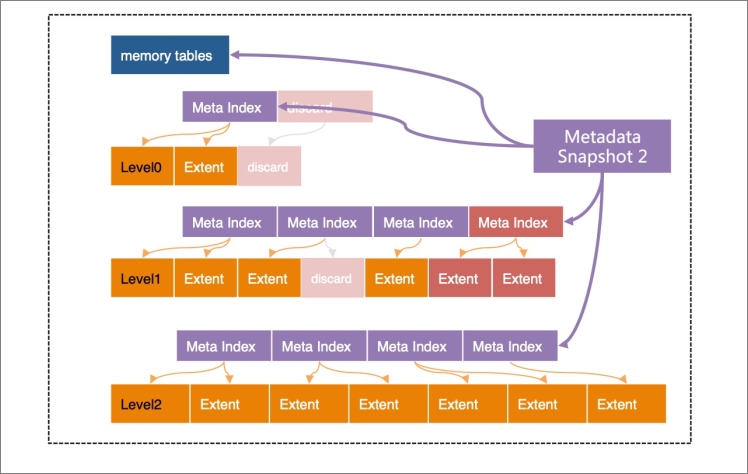
All extents at each level are indexed by a metadata tree with a B-tree-like structure. The root node is a metadata snapshot — a point-in-time view of all data up to a given log sequence number (LSN). All structures except the active memory table are read-only, which is the foundation for X-Engine's snapshot-level isolation.
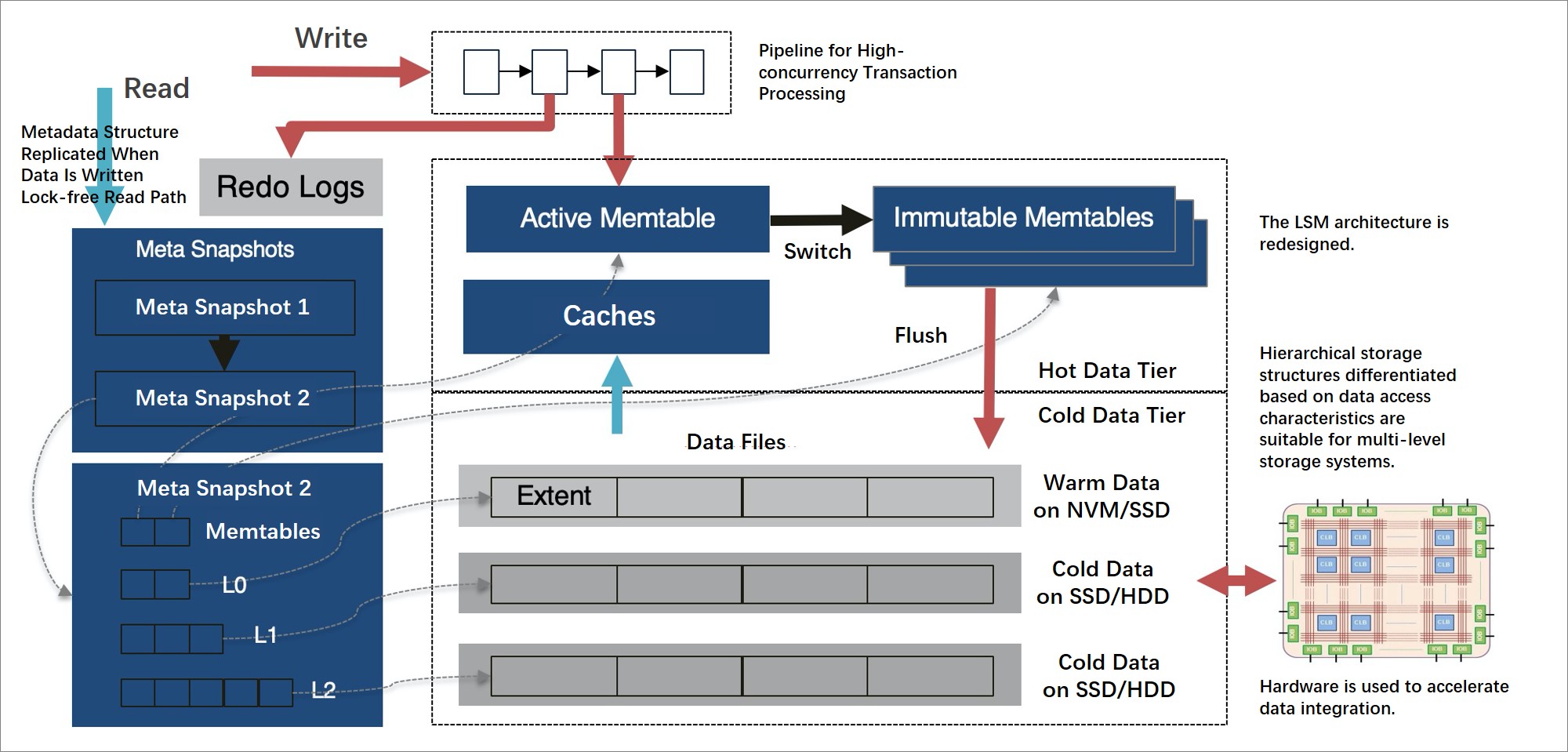
The architecture and optimization techniques are described in the paper "X-Engine: An Optimized Storage Engine for Large-scale E-Commerce Transaction Processing," presented at the 2019 SIGMOD Conference. This was the first time a company from the Chinese mainland published OLTP database engine research at an international academic conference.
Transaction processing
Transaction processing in X-Engine has two phases:
Read and write phase: X-Engine checks for write-write and read-write conflicts. If no conflicts are detected, all modified data is written to a transaction buffer.
Commit phase: Data is written to the write-ahead log (WAL), written to memory tables, committed, and the result is returned.
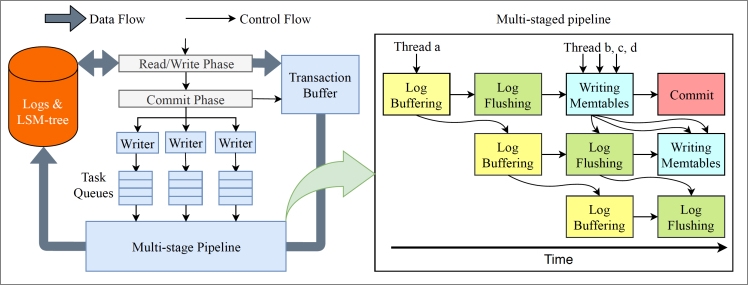
The pipeline: from group commit to parallel stages
Most storage engines use group commit to reduce I/O cost: multiple transactions are batched and flushed to disk together. This allows you to combine I/O operations. However, the transactions that are to be committed at a time still need to wait for a long period of time — for example, when logs are being written to the disk, nothing else is done except to wait for the data to be flushed to the disk.
X-Engine replaces this with a four-stage pipeline:
Copy logs to the log buffer
Flush logs to disk
Write data to memory tables
Commit data
Transaction threads enter the pipeline and freely pick up any available stage. Threads at different stages run concurrently, and no thread waits for another. This eliminates the stall points of group commit and increases transaction throughput by more than 10 times compared with similar engines such as RocksDB.
Read operations
LSM trees accumulate records with the same primary key across multiple levels, each tagged with a sequence number (SN). A read must find the record with the correct SN according to the transaction's isolation level, which may require searching every level.
X-Engine uses three mechanisms to keep reads fast:
Bloom filter: Quickly determines whether a key exists at a given level, skipping levels that cannot contain it.
Row cache: Caches the latest version of hot rows above all persistent levels. A single-row query that misses the memory table hits the row cache before falling through to disk.
SuRF (succinct range filter): A range scan filter (best paper at the 2018 SIGMOD Conference) that determines whether range data exists at a given level, reducing the number of levels scanned during range queries. Asynchronous I/O and prefetching are also used for range scans.
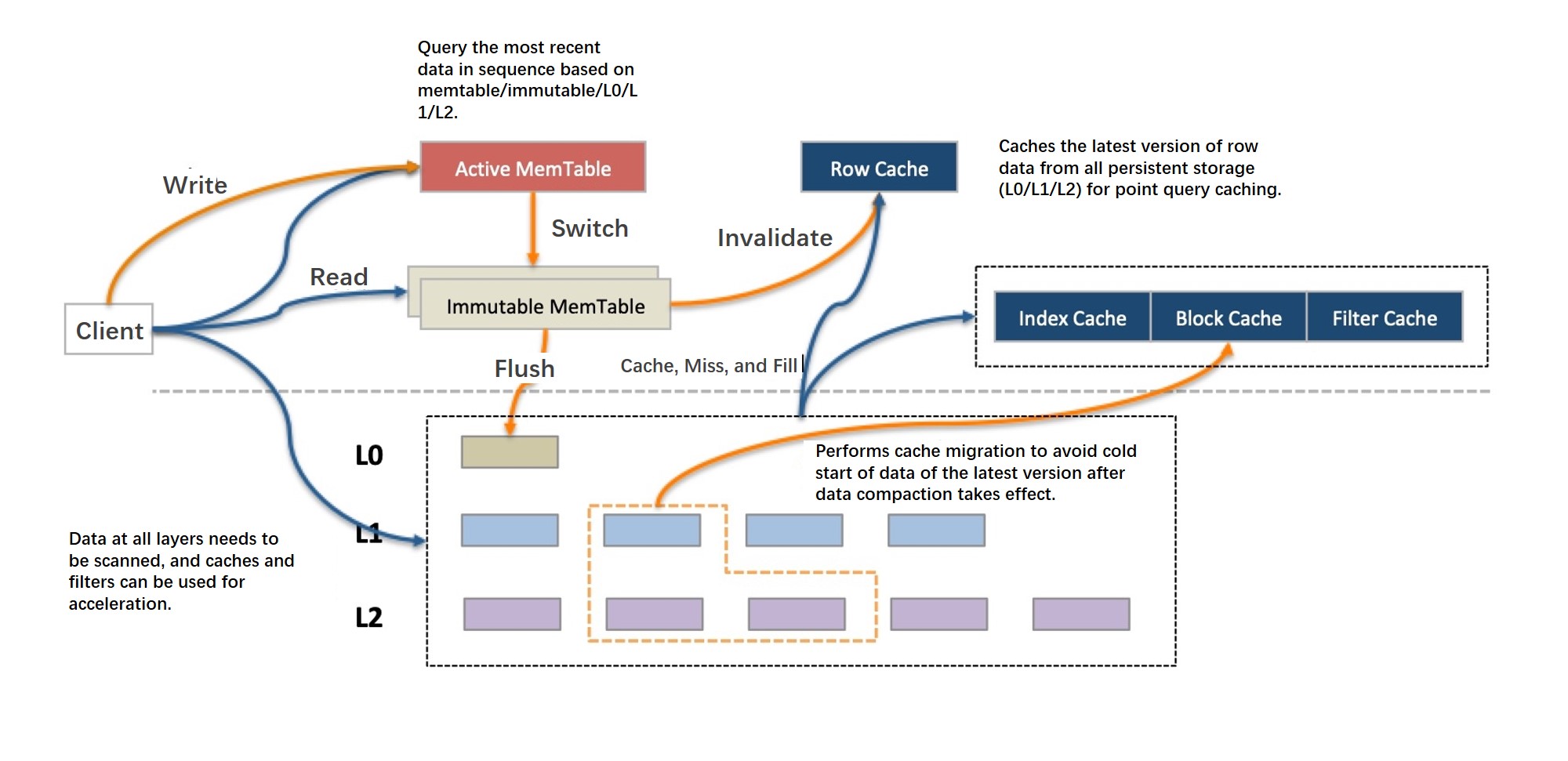
A block cache handles requests that miss both the memory table and the row cache, including range scan results. In standard LSM implementations, a compaction rewrites large amounts of data at once, invalidating large portions of the block cache and causing sharp read performance jitter. X-Engine reduces this through fine-grained compaction and data reuse (described below).
Compaction
Compaction in LSM trees has two goals:
Control the level structure: When compaction falls behind writes, the LSM tree accumulates too many levels — a condition called an *inverted LSM* — and every read must scan more levels. X-Engine's compaction scheduler is designed to prevent this.
Merge data: Records with the same key but different SNs are collapsed to keep only the version with the latest SN (where "latest" means greater than the earliest SN of any active transaction).
Data reuse: reducing compaction I/O
The extent design enables data reuse. When compacting two adjacent levels, only extents and data blocks whose key ranges overlap with data at the other level need to be rewritten. Non-overlapping extents and data blocks are referenced directly in the new metadata snapshot without copying.
| Dimension | Effect |
|---|---|
| I/O and CPU cost | Reduced — only the overlapping portion of data is rewritten |
| Cache invalidation | Reduced — most data blocks remain unchanged, so cached blocks stay valid after compaction |
| Fragmentation (trade-off) | Fine-grained reuse at the data block level can introduce fragmentation; X-Engine's compaction scheduling policies balance reuse rate against fragmentation |
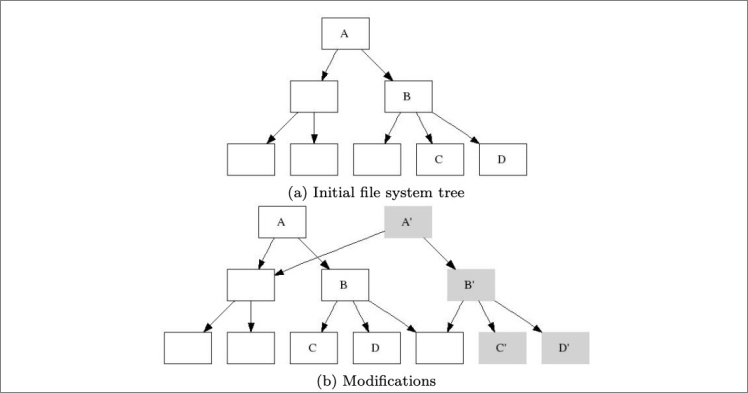
The copy-on-write technique underlies all of this: every compaction and memory table freeze writes results to new extents, then generates a new metadata index and a new metadata snapshot. The old snapshot is preserved until no active transaction references it, providing snapshot-level read isolation without locking.
The data structuring technology is similar to the approach described in B-trees, shadowing, and clones.
FPGA-accelerated compaction
Compaction is the most resource-intensive background operation in an LSM-based engine. X-Engine uses FPGA hardware to offload and accelerate compaction — the first time hardware acceleration has been applied to an OLTP storage engine. This work is described in the paper "FPGA-Accelerated Compactions for LSM-based Key Value Store," accepted by the 18th USENIX Conference on File and Storage Technologies (FAST'20) in 2020.
Key capabilities
| Capability | Mechanism | Benefit |
|---|---|---|
| High write throughput | LSM tree + transaction pipeline | More than 10x throughput vs. RocksDB |
| Low storage cost | Copy-on-write + encoding and compression on read-only data blocks | 50%–90% storage reduction vs. InnoDB |
| Fast single-row reads | Row cache above all persistence levels | Avoids disk I/O for hot rows |
| Fast range scans | SuRF range filter + async I/O + prefetching | Fewer levels scanned |
| Stable read performance | Fine-grained compaction + data reuse | Reduced cache invalidation jitter |
| Hardware-accelerated compaction | FPGA offload | Lower compaction CPU and I/O overhead |
When to use X-Engine
X-Engine is optimized for workloads with large data volumes and cost pressure, where a large proportion of data is cold and accessed infrequently. The following table maps workload characteristics to expected outcomes:
| Workload | Data temperature | Expected benefit |
|---|---|---|
| Transaction history databases | Mostly cold after initial write | High storage savings (50%–90% vs. InnoDB) |
| Chat or message history | High write volume, cold data dominates over time | Write throughput + storage efficiency |
| Peak traffic scenarios (e.g., flash sales) | Mixed hot/cold | Pipeline throughput handles burst load |
| Frequently updated hot rows | Mostly hot | Limited storage benefit; evaluate InnoDB |
X-Engine was deployed in production at Alibaba Group for use cases including transaction history databases, the DingTalk chat history database, and Alibaba Double 11 peak traffic (surging to hundreds of times greater than average).
For detailed guidance on matching workload characteristics to storage engine configuration, see Best practices.