PolarDB for MySQL uses redo-log-based physical replication to implement semisynchronous replication across zones, reducing write performance overhead to approximately 10% — significantly less than MySQL's binlog-based semisynchronous replication. When a write transaction commits, the primary zone waits for acknowledgment from at least one secondary zone that it has received the commit-marking redo log entry, then returns a success response to the application.
How it works
Standard MySQL semisynchronous replication relies on binary logs. Binary logs are generated only at commit time, so the entire log set must transfer to a secondary database before the primary database can return a success response to the client.
PolarDB for MySQL takes a different approach. Redo logs are generated continuously as data changes during transaction execution and streamed to the secondary zone in real time over a physical replication link. The primary zone only waits for the secondary zone to acknowledge the commit-marking redo log entry — not the full log set — before committing and responding. This reduces commit latency under the semisynchronous model.

Maximum commit wait time
If the secondary zone does not confirm receipt within the configured maximum wait time, the write transaction times out and the primary zone automatically commits. This limit is enforced at the kernel layer to prevent secondary zone issues from blocking writes indefinitely.
The parameter innodb_polar_wait_slave_reply_max_time controls this timeout. Its default value is 500 ms, which is appropriate for most deployments. Cross-zone network latency is typically within 1 ms. Setting this value too low — for example, 0 or 1 ms — causes the system to fall back to asynchronous replication almost immediately.
Adaptive mechanism
PolarDB for MySQL monitors network connectivity between the primary and secondary zones and automatically switches to asynchronous replication when timeouts occur frequently. When the network recovers, the system switches back to semisynchronous replication automatically.
The adaptive mechanism monitors network packets, not individual transactions. A small number of transactions may commit during a timeout window before the switch completes. The adaptive mechanism cannot be disabled independently. To keep semisynchronous replication active under high-latency conditions, increase innodb_polar_wait_slave_reply_max_time.
Version requirements
Semisynchronous replication across zones is available only on PolarDB for MySQL Enterprise Edition clusters with major version 8.0.1.
| Capability | Minimum revision version |
|---|---|
| Semisynchronous replication across zones | 8.0.1.35.1 |
| Adaptive mechanism | 8.0.1.1.40 |
innodb_polar_wait_slave_reply_max_time parameter |
8.0.1.1.44.2 |
To enable semisynchronous replication, turn on cross-zone automatic switchover. See Enable cross-zone automatic switchover.
RPO and RTO
| Replication mode | Recovery Point Objective (RPO) | Recovery Time Objective (RTO) | Notes |
|---|---|---|---|
| Asynchronous | Less than 100 ms in most cases; less than 60s in the worst case | Less than 30s | Evaluate the business impact before enabling cross-zone automatic switchover. |
| Semisynchronous | 0, when no fallback occurs | Less than 30s | Performance is reduced by about 10%. If the wait time exceeds 500 ms, the mode falls back to asynchronous replication, and RPO is no longer 0. |
When does RPO = 0 apply? RPO is strictly 0 only when every transaction waited for redo log confirmation from the secondary zone before committing — that is, when no fallback occurred. When the adaptive mechanism switches to asynchronous replication, it detects the issue at the network packet level rather than the transaction level. By the time the switch completes, a small number of transactions may have already committed during the timeout window. In practice, RPO remains infinitely close to 0, but is not strictly 0 when adaptive fallback occurs.
Performance test results
Note: The following results reflect the tested version and may differ from the current version.
| Test attribute | Details |
|---|---|
| Tool | Sysbench (oltp_write_only mode) |
| Cluster specifications | 16 cores, 64 GB |
| Tested version | PolarDB for MySQL 8.0.1, revision 8.0.1.35.1 |
| Data volume | 10 tables, 10 million rows per table |
| Metric | QPS (queries per second) |
| Comparison | Asynchronous replication vs. PolarDB semisynchronous vs. MySQL semisynchronous |
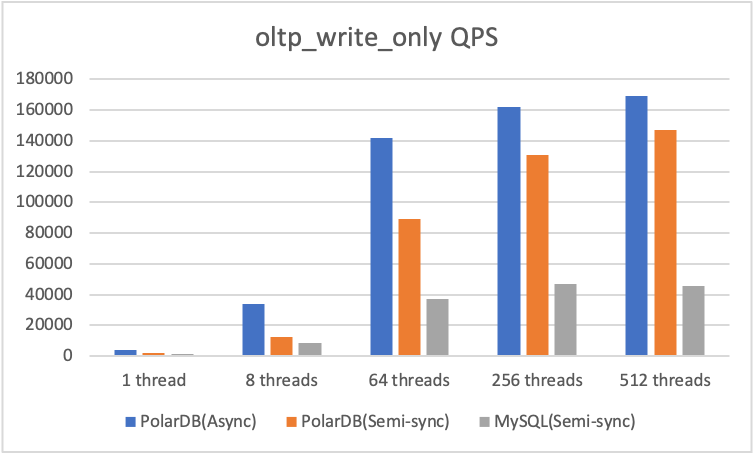
In high-concurrency scenarios, enabling semisynchronous replication reduces QPS by about 10%. PolarDB for MySQL's redo-log-based approach outperforms MySQL's binlog-based semisynchronous replication.
FAQ
Why does performance degrade by more than 10% after I enable semisynchronous replication?
The ~10% figure applies to high-concurrency scenarios, where multiple redo logs are processed in batches and network round-trip overhead is amortized across many transactions. In low-concurrency scenarios — especially with a single write thread — redo I/O cannot be batched. Each transaction incurs a full network round trip, which significantly increases latency. Semisynchronous replication is most efficient when write concurrency is high enough for batch processing to take effect.
The innodb_polar_wait_slave_reply_max_time parameter is not visible in the console. How do I adjust it?
This parameter is available only on Enterprise Edition clusters with major version 8.0.1 and revision 8.0.1.1.44.2 or later. If it does not appear in the console, check whether the cluster version meets the requirement. To upgrade, see Revision version management.
The default value of 500 ms is appropriate for most cases. Increase the value if you need write transactions to always wait for replication to the secondary zone before committing. Set it lower to limit the maximum commit delay — but cross-zone network latency is typically within 1 ms, so values near 0 or 1 ms are likely to trigger fallback to asynchronous replication.
When does the adaptive mechanism take effect? Can I disable it while keeping semisynchronous replication active?
The adaptive mechanism activates automatically whenever semisynchronous replication is enabled. It continuously monitors synchronization status and adjusts the replication mode in real time. It cannot be disabled independently. To minimize fallbacks, set innodb_polar_wait_slave_reply_max_time to a higher value so the system tolerates more latency before triggering a switch.
Is a fallback the same as the adaptive mechanism switching to asynchronous replication?
No. "No fallback" means every transaction waited for redo log confirmation before committing — in that case, RPO is strictly 0. When the adaptive mechanism switches to asynchronous replication, it operates at the network packet level rather than the transaction level. Some transactions may have already committed during the timeout window before the switch completes. Only a small number of transactions are affected, so RPO remains infinitely close to 0 — but not strictly 0 when adaptive fallback occurs.