This topic describes basic components for row-column fusion in In-Memory Column Index (IMCI) and the HybridIndexSearch operator used to handle long-tail requests.
Background information
The Online Transaction Processing (OLTP) and Online Analytical Processing (OLAP) workloads have become more common in business systems. To ensure timeliness and easy O&M, some business systems use hybrid transaction/analytical processing (HTAP) databases instead of the OLTP-ETL-OLAP architecture. HTAP databases can process Transaction Processing (TP) and Analytical Processing (AP) requests in an efficient manner within a single database system. However, because TP and AP requests use different modes to access data, the request processing efficiency of HTAP databases depends on different storage formats and computing modes. Therefore, HTAP databases need to store data in two different formats, and select different modes to calculate data when processing TP and AP requests. The following figure shows how PolarDB processes OLTP and OLAP workloads.

PolarDB processes HTAP workloads in the way shown in the preceding figure. After you enable the IMCI feature, read-only nodes maintain an additional replica of IMCIs, and calculate column-oriented data in a vectorized manner when processing AP requests. This calculation method is called column-oriented calculation. The read-only nodes calculate row-oriented InnoDB data by using the one-tuple-at-a-time method of MySQL when processing TP requests. This calculation method is called row-oriented calculation. Row and column indexes replay write operations on the read-only nodes by using physical replication links. In PolarDB, the storage, executor, and optimizer that process TP and AP requests are independent of each other. This ensures that the TP and AP requests are processed on separated paths. A SQL statement selects column-oriented calculation or row-oriented calculation based on your business requirements.
Long-tail requests
For most requests in OLTP and OLAP workloads, the column- and row-oriented calculation methods can be executed based on the optimal plan. However, the calculation methods are not suitable for a small number of requests in the following scenarios:
For queries that use WHERE, JOIN, or LIMIT clauses on a small number of columns in a wide table, IMCIs can significantly improve the query performance. However, if IMCIs are used in queries that involve the details of a filtered column, the project must obtain all column information, which greatly increases the number of read workloads. In this case, row indexes are more suitable.
For example, a segment in an execute plan is
join (t1 join t2). The WHERE conditions on the t1 table filter out a large amount of data and contain InnoDB indexes. The JOIN conditions on the t2 table do not contain InnoDB indexes and involve only a small number of columns. For a query that involves the WHERE and JOIN conditions, we recommend that you use the row-oriented calculation method and the InnoDB indexes to query the t1 table, and then use the column-oriented calculation method to query the t2 table for Hash Join operations.In the example described in the preceding scenario, the JOIN conditions on the t2 table contain InnoDB indexes. In this case, we recommend that you use the row-oriented calculation method to perform Hash Join operations in the
t1 join t2segment. Other segments in the plan may be executed by using the column-oriented calculation method.
To process long-tail requests in the OLTP and OLAP workloads in an more efficient manner, the optimizer and executor of IMCIs provide a row-column fusion architecture.
Key challenges
You may encounter the following challenges when you implement row-column fusion in a system that uses the row-column separation architecture:
Optimizer cost estimation: The IMCI optimizer uses different cost models from that of the MySQL optimizer. If you use the cost models of MySQL to calculate the cost of row-oriented execution segments and then use the cost models of IMCIs to calculate the cost of column-oriented execution segments, you cannot obtain the cost of the entire execution plan. You must specify a unified CPU and I/O cost unit, and then calculate the final cost based on the complexity of row- and column-oriented algorithms and the statistics of row and column indexes.
Access from executors to different indexes: The MySQL and IMCI executors must simultaneously access InnoDB indexes and IMCIs. The MySQL executor executes a SQL request and accesses InnoDB-related operations and contexts by using a single thread. However, the IMCI executor processes a SQL request by using a single leader and multiple workers. If a worker needs to access InnoDB indexes, additional processing is required.
Strongly consistent read of row and column indexes: An IMCI and an InnoDB index asynchronously replay write operations on a primary node. The point at which the redo logs in one index may not align with that in another index. InnoDB determines data visibility by using read views based on Log Sequence Numbers (LSNs), while IMCIs determine data visibility by using sequences similar to LSM-tree storage engines. In the asynchronous redo log replay scenario, row and column indexes can only implement eventual consistency for read operations. However, inconsistent visibility between row-oriented data and column-oriented data in row-column fusion execution segments causes incorrect execution results.
Basic components for row-column fusion
Optimizer cost model
In the row-column separation architecture, the preceding types of long-tail requests are considered AP requests based on cost and are executed by IMCIs. Therefore, the system selects the IMCI-based optimizer and estimates the cost of row-oriented execution segments. This way, long-tail requests can be executed based on row-column fusion execution plans.
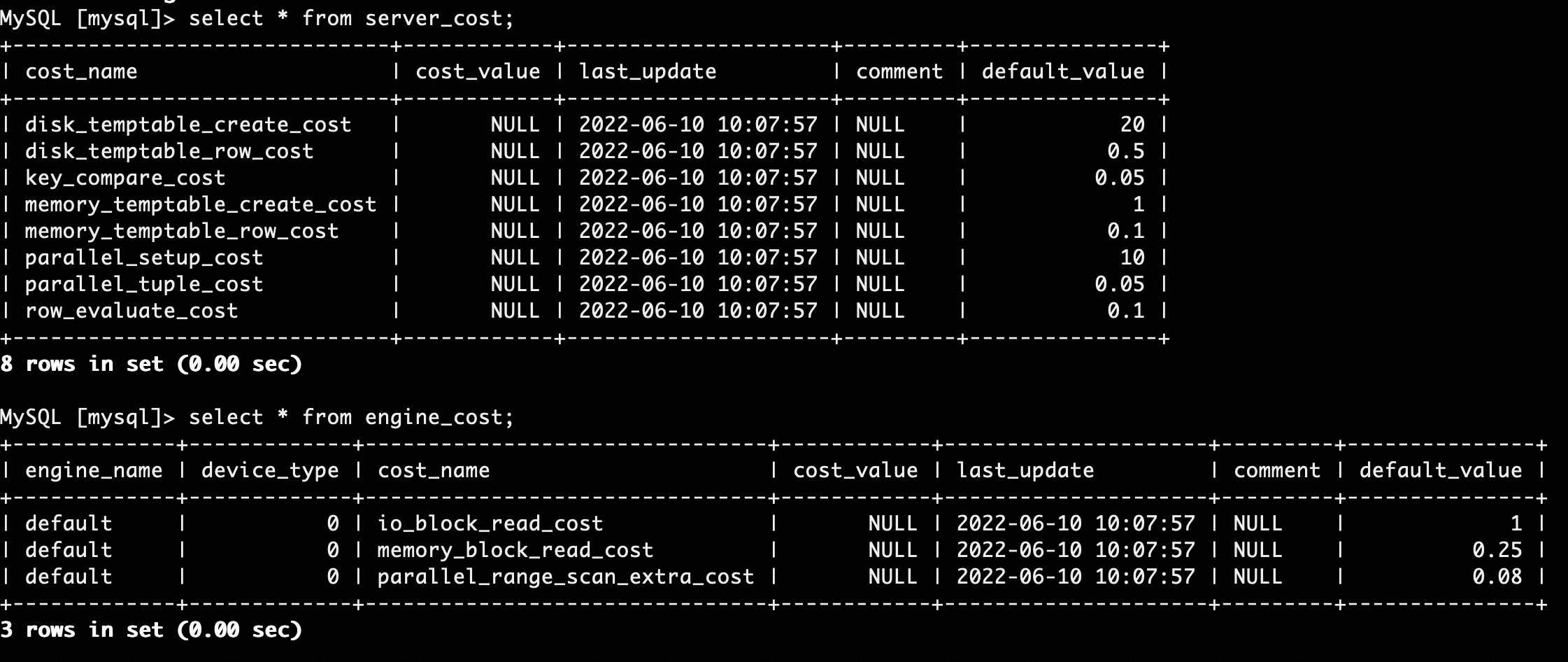
When the system estimates the cost of row-oriented execution, the following principles must be met:
For an execution segment, the system relatively overestimates the cost of row-oriented execution and underestimates the cost of column-oriented execution. Long-tail requests are originally executed in the column-oriented manner. The cost estimation of the column-oriented execution can ensure that when a long-tail request is executed based on row-column fusion execution plans, the execution efficiency of the request is the same as or even higher than that of the original execution plans.
Only the ratio of a cost constant to another constant of the MySQL optimizer is referred. The preceding figure shows the cost constants of the MySQL optimizer. The cost constants of IMCIs have different orders of magnitude. Therefore, you cannot use the absolute values of the constants. However, you can refer to the ratio of a constant to another constant.
IMCIs use the following configurations based on the preceding principles:
In the IMCI optimizer, the io_block_read_cost constant value of InnoDB is the same as the pack io cost constant value of IMCIs. Although a single page in InnoDB is 16 KB in size and a pack in an IMCI contains 65,536 rows whose size is larger than 16 KB, the I/O cost constant value of InnoDB is the same as that of the IMCI based on the first principle and taking into account the concurrent requests sent by the self-developed distributed file system Polar File System (PolarFS) and the file discretization granularity of PolarFS.
The percentage of memory_block_read_cost is the same as that of row_evaluate_cost based on the second principle.
The costs of row-column fusion execution plans are calculated by using the preceding cost constants based on the algorithms and statistics of MySQL and IMCIs.
Multi-engine access in the executor
After the IMCI optimizer selects row-column fusion execution plans for long-tail requests, a new hybrid operator is introduced in the IMCI executor to calculate row-oriented execution segments. The following figure shows the execution process of SQL statements.

The new hybrid operator needs to access InnoDB in the IMCI executor, follow the implementation principle of the server layer of MySQL, and use the handlers in table objects to interact with InnoDB. The preceding figure shows that although tables are opened in the prepare phase, relevant objects and operation calls are implemented by using a single MySQL thread. Therefore, in a worker of an IMCI, you must re-open tables and clone or reference relevant objects.
Log replay and transaction processing of storage engines
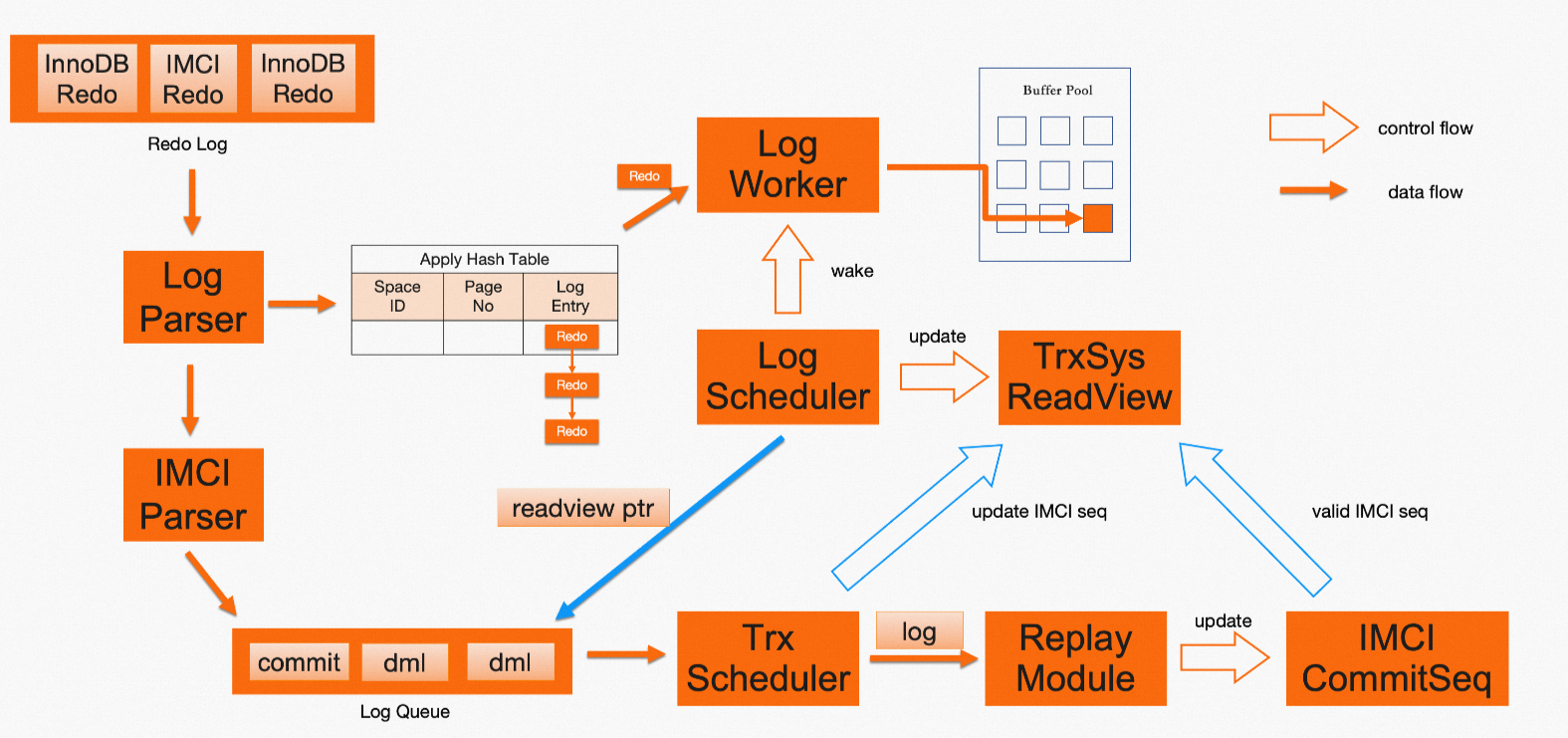
The preceding figure shows the process of replaying an InnoDB index and an IMCI in an asynchronous manner. After the InnoDB index is replayed, the latest read view is updated. After the IMCI is replayed, the last commit sequence is updated. The replay process runs once after receiving a specific number of redo log files such as several redo log entries. The submitting status of InnoDB transactions and IMCI transactions in the redo log files is consistent. Therefore, after several redo log files are replayed on the indexes, the data visibility on the indexes is consistent based on the latest read view and last commit sequence that are updated. The read view and commit sequence are called corresponding. If a query uses the corresponding read view and commit sequence to determine data visibility, strong consistent reads can be achieved.
However, row and column indexes are replayed in an asynchronous manner. Due to the difference in replay speed, the latest read view and last commit sequence may not be corresponding at any time. In this case, you must find the corresponding read view and commit sequence that are recently updated. To resolve this issue, the process in the blue part is introduced in the asynchronous replay process, as shown in the preceding figure. The following section describes the process:
For several redo log files, InnoDB adds a dummy log object that contains the current latest read view in the log queue of IMCIs after updating the latest read view.
A single thread of an IMCI processes the log queue. The thread pushes regular log objects to the replay module and calculates the updated commit sequence after the replay is completed. Then, the thread processes the dummy log object and binds the commit sequence to the corresponding read view.
NoteSome regular log objects may not be replayed when the dummy log objects are processed. Therefore, the commit sequence that is bound to the read view may not take effect in IMCIs. The corresponding read view and commit sequence can be used only after the replay is completed.
After the preceding process is introduced, row-column fusion queries search for a read view whose corresponding commit sequence has taken effect in read views that are not purged to determine data visibility.
HybridIndexSearch
The HybridIndexSearch operator is introduced to resolve the first type of long-tail request issue based on row-column fusion components. The HybridIndexSearch operator obtains complete rows from the primary index of InnoDB by using the primary key, calculates the rows by using relevant expressions, and then generates the rows. In addition to the capabilities provided by the basic components, the HybridIndexSearch operator requires that its child operators in execution plans generate primary key data. You can set the property of the primary key when the optimizer searches for the execution plans.
Performance test
This test uses the OnTime dataset provided by ClickHouse to verify the performance of the row-column fusion architecture and the HybridIndexSearch operator. For more information about the OnTime dataset, see OnTime.
The table in the OnTime dataset is a typical wide table that contains 110 columns. You can execute the following statement to simulate the first scenario that involves long-tail requests:
SELECT * FROM ontime ORDER BY ArrTime LIMIT 1000;All execution plans in the row-column fusion execution, column-oriented execution, and row-oriented execution scenarios are on cold start. The following table describes the execution time in each scenario. The execution time is measured in seconds.
Row-column fusion execution | Column-oriented execution | Row-oriented execution |
0.33 | 2.56 | 232.48 |
The test results indicate that you can maximize the performance of long-tail requests in the OLTP and OLAP workloads by using the row-column fusion architecture and the HybridIndexSearch operator. The execution time in the row-column fusion scenario is more exponentially reduced than the execution time in the column- and row-oriented scenarios.