PolarDB for MySQL includes native full-text search built on the In-Memory Column Index (IMCI). Add full-text indexes directly to existing tables and run millisecond-level fuzzy queries using the MATCH function or an optimized LIKE operator — without deploying a separate search cluster. Because index updates are committed in the same transaction as data writes, search results always reflect the latest state of your data.
How it differs from external search solutions
| Dimension | PolarDB IMCI full-text search | Database + Elasticsearch |
|---|---|---|
| Data consistency | Strong consistency. Index updates and data writes complete in the same transaction (ACID). No synchronization latency or inconsistency. | Eventual consistency. Data must sync from the database to Elasticsearch, which introduces latency. Real-time accuracy and transactional atomicity are not guaranteed. |
| Architecture | Simple. Built into the database — no extra components needed. | Complex. Requires a separate Elasticsearch cluster and data synchronization pipeline. |
| Query method | Unified SQL for all data, structured and unstructured. | Fragmented. Requires both SQL and the Elasticsearch DSL. Often requires two-stage queries: first Elasticsearch, then the database. |
| O&M costs | Low. Reuses PolarDB's existing O&M and high availability systems. | High. Requires separate server resources, professional Elasticsearch expertise, and dual storage costs. |
Key concepts
Full-text search converts unstructured text into a structured index. Here is a concrete example:
Given three rows:
| Row | Content |
|---|---|
| 1 | "The database stores user data." |
| 2 | "User data is processed daily." |
| 3 | "Daily reports summarize the data." |
After tokenization, an inverted index maps each term to the rows containing it:
data → [1, 2, 3]
daily → [2, 3]
reports → [3]
user → [1, 2]A query for data instantly retrieves rows 1, 2, and 3 by looking up the term in the index — no row-by-row scan needed.
The following table defines the core terms used throughout this document:
| Concept | Description |
|---|---|
| Document | A unit of indexable raw data. In PolarDB IMCI, a document is a row in the column store. |
| Term | The smallest language unit for indexing and querying, extracted from a document by a tokenizer. |
| Tokenizer | A component that splits raw text into a sequence of terms. PolarDB IMCI provides the token, ngram, jieba, ik, and json tokenizers. |
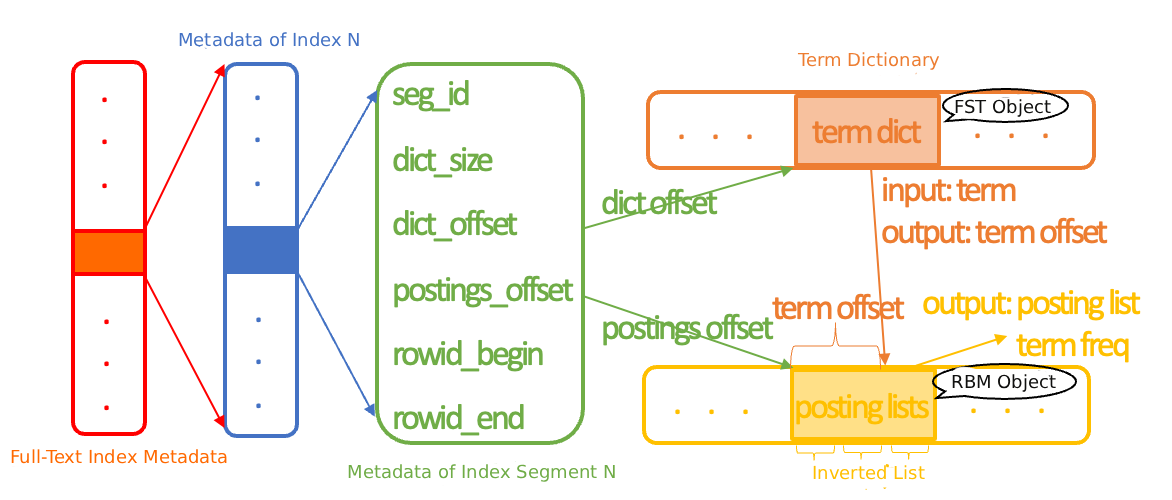
| Inverted index | The core data structure for full-text search. Maps each term to the list of documents that contain it, using a term dictionary and a posting list. |
| Term dictionary | A collection of all indexed terms, built with the Finite State Transducer (FST) algorithm. Query time complexity is O(L), where L is the term length. |
| Posting list | The list of document IDs (64-bit row numbers) that contain a specific term, compressed using the Roaring Bitmap (RBM) algorithm. |
How it works
The full-text search pipeline has two stages: write and query.
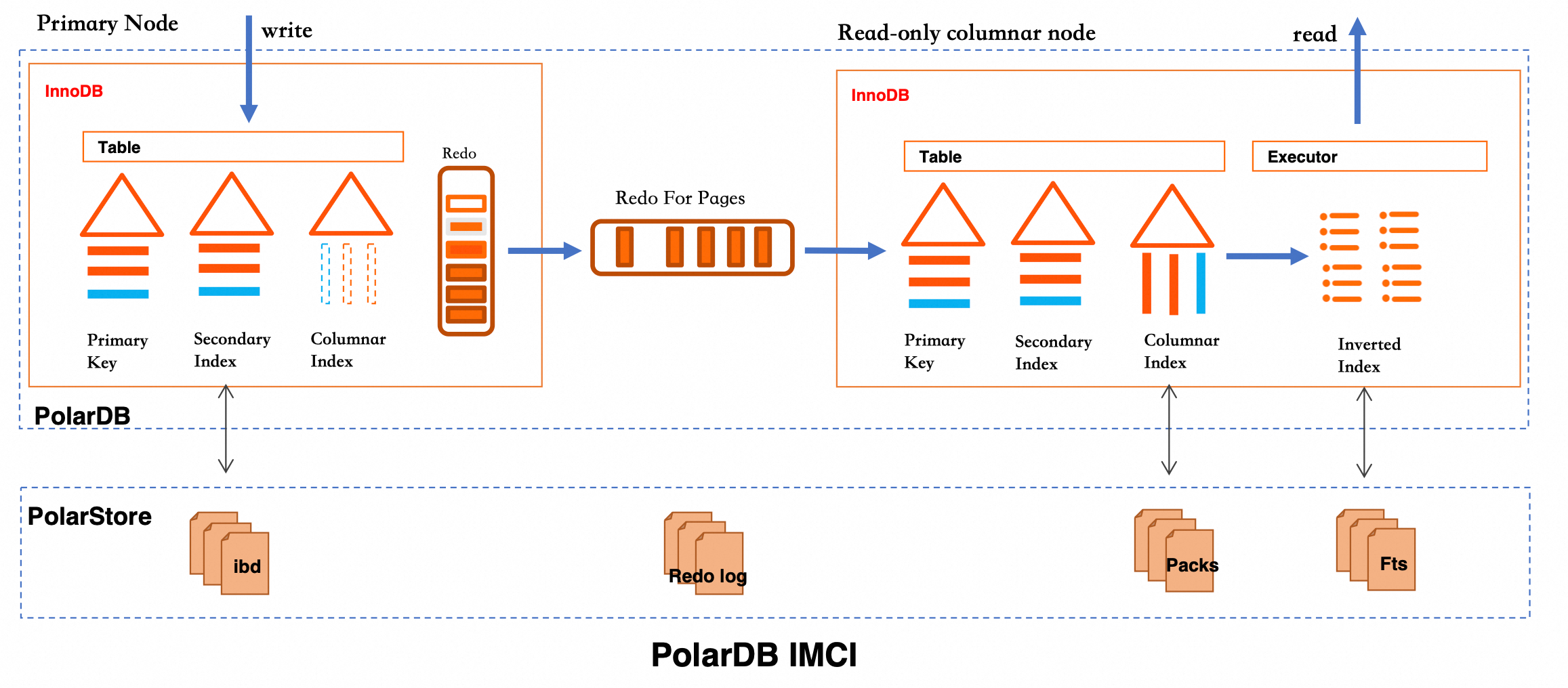
Write stage: When data is written to an InnoDB table, IMCI synchronizes it to Pack files in PolarStore through the columnstore index. The inverted index is built asynchronously over the columnstore data and persisted as Fts files.
Query stage: The executor looks up the inverted index to find matching row numbers, then fetches the corresponding rows. Two retrieval operators are available:
`FtsTableScan`: Traverses the inverted index directly. Best for high-selectivity queries where the index filters most rows.
`MATCH` expression: Looks up row numbers against the index. Best when preceding filter conditions have already reduced the candidate set significantly.
The column store optimizer chooses between these two based on statistics.
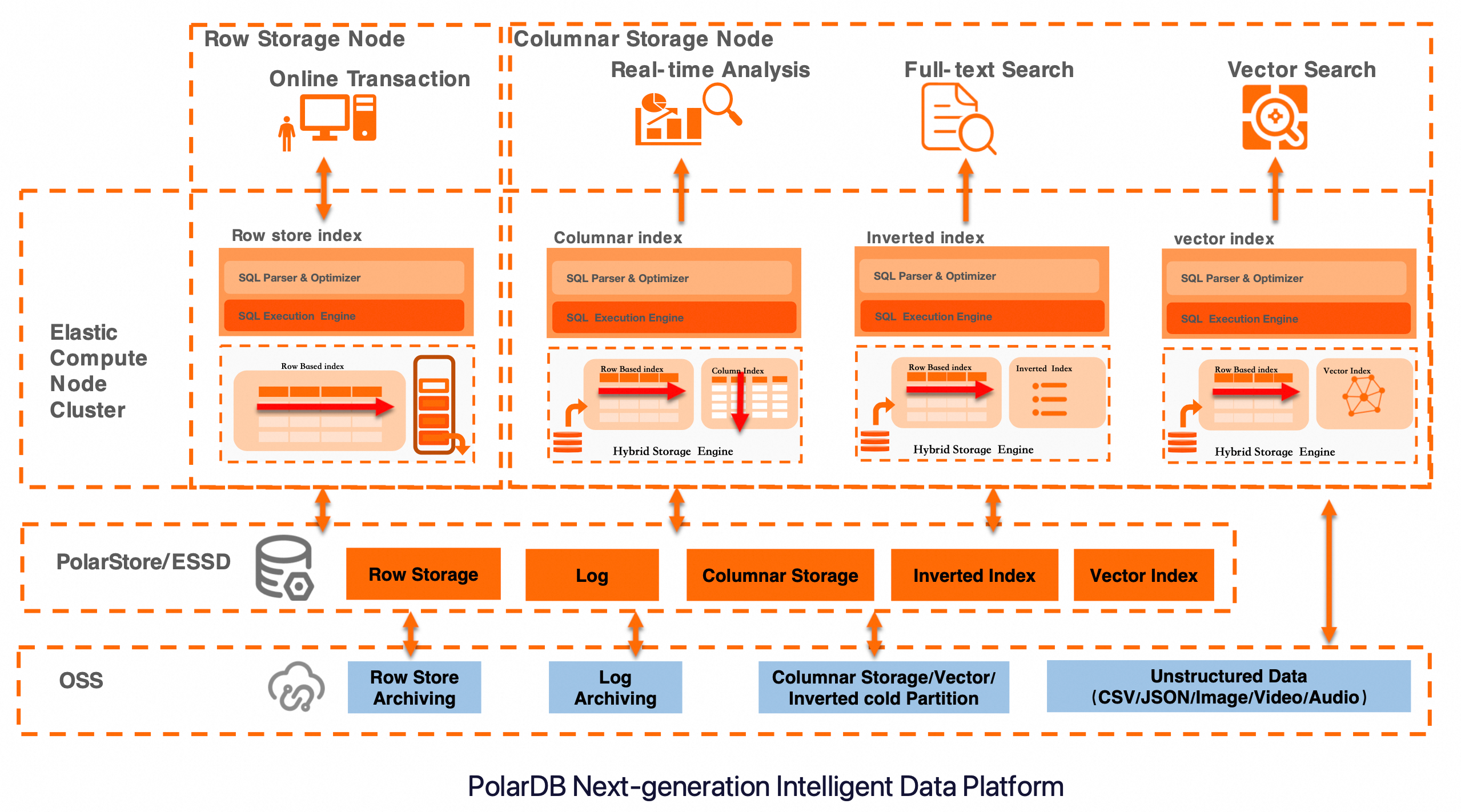
PolarDB IMCI uses a unified hybrid storage architecture that combines elastic compute nodes with tiered storage. Full-text search relies on the Hybrid Storage Engine to build and maintain inverted indexes. The architecture also integrates a vector index, enabling combined text and vector retrieval within a single database. This makes it suitable for OLTP (online transactional processing), real-time analytics, full-text search, and vector search — all in one platform.
Tokenizers
Tokenization splits raw text into terms. The tokenizer choice directly affects which queries hit the index and what results they return.
| Tokenizer | Best for | How it splits text |
|---|---|---|
token | English and other languages that use spaces as separators | Splits on non-alphanumeric characters (spaces, punctuation) |
ngram | Fuzzy substring matching; replacing LIKE '%keyword%' | Splits into continuous fixed-length character sequences of length n |
jieba | Chinese text with semantic accuracy | Based on the jieba library; supports precise, full, and search engine modes |
ik | Chinese text; familiar to Elasticsearch users | Based on IK Analyzer, commonly used in Chinese search engines |
json | Structured JSON fields | Extracts specific key-values or array elements using JSONPath expressions |
Verify tokenization results before creating an index. Use dbms_imci.fts_tokenize to preview how each tokenizer processes your data. Different tokenizers produce different index contents. A mismatch between your tokenizer settings and your query terms causes unexpected results.
Posting lists
A posting list stores the set of row numbers from the columnstore index that contain a specific term, along with optional term frequency and document frequency. Each term has exactly one posting list.
IMCI uses the Roaring Bitmap (RBM) algorithm (based on the CRoaring library) to compress and compute posting lists. Storage is selected dynamically based on data density:
Fewer document IDs than a preset threshold: stored as
std::arrayAbove the threshold: stored as
roaring::Roaring64Map, handling both sparse and dense data at a high compression ratio
Performance characteristics:
O(logN) lookup complexity during index building
SIMD (single instruction multiple data) instructions for fast set intersection and union
Space reorganization on disk write to reduce fragmentation
minimum/maximumvalues for fast filtering and iterator optimization during queries
Term dictionary
The term dictionary maps terms to their posting list offsets. IMCI uses the Finite State Transducer (FST) algorithm, which balances space and time efficiency:
Space: Shares common prefixes and suffixes across terms, minimizing storage.
Time: O(L) query complexity, where L is the length of the term being looked up. FST prefix calculation is byte-based, so it handles UTF-8 encoding correctly.
For example, given the terms China (offset 5), Chinese (offset 10), and love (offset 15):
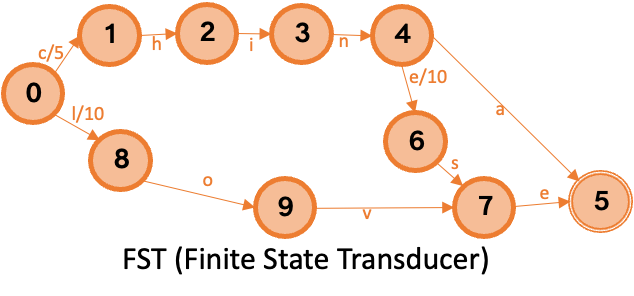
The FST shares the Chin prefix between China and Chinese, and stores each transition's associated value so that a query accumulates the correct offset as it traverses the graph.
Index building
IMCI builds inverted indexes using Single-pass in-memory indexing (SPIMI): it scans columnstore data once, tokenizes each row, and accumulates terms in a hash table. When memory usage reaches the segment size threshold, the hash table is sorted, posting lists are serialized to disk, and the FST dictionary is built and written. Memory is then reset for the next batch.
This local-index approach avoids external sorting. Multiple local indexes are merged asynchronously in the background during idle periods.
Write operations follow these patterns:
| Operation | Behavior |
|---|---|
| INSERT | Appended to the columnstore in insertion order; tracked by array InsertMask for visibility |
| DELETE | Marked for deletion using lsm DeleteMask; physical removal happens during background Compaction |
| UPDATE | Converted to DELETE + INSERT |
Because deletes are only marked rather than applied immediately, large batch inserts never trigger a global rebuild. The asynchronous Compaction task periodically merges inverted segments, removes deleted rows, and produces more compact indexes — improving both space usage and query performance without affecting write throughput.
Increasing the memory threshold for index building allows more instances of the same term to fall into a single inverted segment. This reduces the total number of segments, saves space, and improves query performance.
Index retrieval
`MATCH` function
All MATCH queries are routed to the column store node, regardless of whether a row store full-text index exists. If a row store index exists, routing is decided by cost evaluation. To prevent row store full-text index overhead (auxiliary table synchronization, cache loading) from affecting column store performance, PolarDB skips those operations early in the routing stage.
The full-text index is built asynchronously, which introduces a short delay before new data is indexed. By default, IMCI supplements query results with a full table scan over unindexed rows to ensure completeness. A parameter is available to disable this supplemental scan when higher performance is needed and a brief indexing lag is acceptable.
`LIKE` acceleration
Under specific conditions, IMCI rewrites LIKE predicates as inverted index lookups to eliminate full table scan overhead:
The columnstore full-text index must use the
ngramtokenizer.The ngram token length must be less than or equal to the length of the
LIKEpattern string.
When these conditions are met, a predicate such as LIKE '%abc%' is rewritten as an FtsTableScan + Filter operator. The original LIKE expression is retained as a post-filter to handle cases where ngram tokenization produces false positives. For example, "abbc" tokenizes to ab, bb, bc — which overlaps with terms from "abc" and would otherwise produce incorrect matches.
Index structure and query modes
The inverted index consists of multiple inverted segments. Each segment contains:
Metadata (stored in memory by default): start addresses of the dictionary and posting lists
A term dictionary (FST)
A series of posting lists (one per term)
Retrieval operates per segment in one of two modes:
Operator query: Traverses all segment metadata, loads each dictionary, finds the target term, and reads the corresponding posting list.
Expression query: Identifies the relevant segments by row number using row range metadata, then performs the same dictionary lookup and posting list read.
IMCI maintains an LRU (Least Recently Used) cache for term dictionaries. Posting list caching is disabled by default — individual posting lists are small (typically a single 4 KB read), so caching them yields limited benefit and would waste memory.
Performance benchmark
ESRally is the official Elasticsearch benchmarking tool from Elastic. This section uses its built-in http_logs dataset (247 million rows, ~32 GB uncompressed) to evaluate IMCI full-text search performance.
For a demonstration in a real e-commerce scenario, see Accelerate complex e-commerce queries with the IMCI feature of PolarDB for MySQL.
Prepare the dataset
Download the dataset:
git clone https://github.com/elastic/rally-tracks.git cd rally-tracks ./download.sh http_logsThis produces a compressed package (
rally-track-data-http_logs.tar, ~1.7 GB). After decompression, the dataset is ~32 GB with 247 million rows. For dataset details, see Elasticsearch Rally Hub.Create a table: A few rows in the dataset contain JSON that is incompatible with the MySQL JSON type. Use
varchar(4096)instead.CREATE TABLE http_logs( logs varchar(4096) );Import the data:
LOAD DATA INFILE '/home/xxx/http_logs/documents-181998.json' INTO TABLE http_logs COLUMNS TERMINATED BY '\n'; -- Repeat for each file in the datasetAdd a virtual column for the
requestfield:ALTER TABLE http_logs ADD COLUMN request varchar(1024) AS ( CASE WHEN json_valid(logs) THEN (json_unquote(json_extract(logs, '$.request'))) ELSE NULL END );Create a columnstore index: The columnstore inverted index requires a columnstore index as a prerequisite.
ALTER TABLE http_logs comment 'columnar=1';Create the inverted index: Modify the column comment using DDL. The DDL statement completes in seconds; the inverted index is built asynchronously in the background.
ALTER TABLE http_logs MODIFY COLUMN request varchar(1024) AS ( CASE WHEN json_valid(logs) THEN (json_unquote(json_extract(logs, '$.request'))) ELSE NULL END ) comment 'imci_fts(type=2 mode=1)';Verify the index is built:
SHOW imci indexes; SHOW imci indexes fulltext;Check
NUM_PACKS(total columnstore data blocks) andNEXT_PACK_ID(the block up to which the index has been built). When the two values are close, the inverted index is fully built.
Run the benchmark
After the index is built, test retrieval performance across term frequencies using MATCH. The queries below compare LIKE, MATCH (IMCI proprietary FTS library), and Doris MATCH_ANY (CLucene library) on the same dataset.
Single-threaded results with hot data:
| Query | High-frequency (~247M rows) | Relatively high-frequency (~15M rows) | Relatively low-frequency (~80K rows) | Low-frequency (~100 rows) |
|---|---|---|---|---|
LIKE | 1 min 21.96 sec | 1 min 18.44 sec | 1 min 24.59 sec | 1 min 31.19 sec |
SIMD LIKE | 25.46 sec | 22.80 sec | 21.98 sec | 21.60 sec |
MATCH (IMCI proprietary FTS) | 2.43 sec | 0.25 sec | 0.01 sec | 0.00 sec |
Doris MATCH_ANY (CLucene) | 3.49 sec | 0.24 sec | 0.03 sec | 0.03 sec |
MATCH is significantly faster than LIKE at all selectivity levels and is not sensitive to whether data is hot or cold.
Use cases
E-commerce product search
Keyword search on product titles, descriptions, and attributes is a core requirement on any e-commerce platform. LIKE '%keyword%' is too slow under concurrent load, and Elasticsearch introduces synchronization lag — search results may include products that have been delisted or repriced since the last sync.
With PolarDB IMCI, full-text indexes sit directly on the product table. Queries run against the current committed state of the data, so price and inventory are always accurate. No separate search cluster or sync pipeline is needed.
Log analysis and observability
Finding error stacks or tracing request chains across hundreds of millions of log rows is slow without a dedicated index. The ELK stack (Elasticsearch, Logstash, and Kibana) is powerful but adds significant operational overhead and introduces a delay between data ingestion and searchability.
Create a full-text index on the message or content column of a log table and query with standard SQL. Millisecond-level retrieval is available without a separate log platform.
Document and knowledge base retrieval
For knowledge bases, product manuals, and help centers, content must be searchable immediately after an update. Dual-write pipelines to an external search engine create synchronization gaps.
Create a full-text index on the document body. Use the jieba or ik tokenizer to improve accuracy for Chinese content. After any write, the content is searchable within the same database transaction that committed it.
User profiling and behavior analysis
Analyzing user comments, tags, and posts for interests and preferences typically requires exporting data to a warehouse. With IMCI, use the json tokenizer on JSON fields or jieba on long text fields. Combine structured filters (age, region) with text predicates in a single SQL query for real-time segmentation and recommendation — no data migration needed.
Limitations
| Limitation | Details |
|---|---|
| Index synchronization latency | The inverted index is built asynchronously. New rows are not immediately searchable after a write. By default, IMCI compensates with a supplemental full table scan, which has a performance cost. You can disable the supplemental scan via a parameter if a brief indexing lag is acceptable. |
LIKE acceleration conditions | LIKE rewriting to an inverted index lookup applies only when the columnstore full-text index uses the ngram tokenizer and the ngram token length is less than or equal to the length of the LIKE pattern string. |
| Columnstore index prerequisite | A columnstore inverted index requires a columnstore index on the same table. You must enable the columnstore index (columnar=1) before creating a full-text index. |
FAQ
What are the advantages of IMCI full-text search compared to the native InnoDB full-text index?
Performance, feature coverage, and write impact are the main differences:
Performance: The columnar storage and vectorized execution engine, combined with FST and Roaring Bitmap algorithms, deliver faster query performance at scale compared to row store indexes.
Chinese tokenization: Built-in
jiebaandiktokenizers handle Chinese text semantically. InnoDB's native full-text index does not support these.Write impact: The mark-for-deletion design and asynchronous index building have a much smaller impact on INSERT and UPDATE throughput than InnoDB's synchronous full-text index maintenance.
Scalability: PolarDB's decoupled storage-compute architecture allows the column store to scale horizontally without impacting the row store.
How do I choose a tokenizer?
Match the tokenizer to your data type:
Chinese text: Use
jiebaorik. Both perform semantic tokenization, which improves search accuracy for Chinese queries.English or symbol-delimited text: Use
token. It splits on spaces and punctuation.Fuzzy substring matching (replacing `LIKE '%keyword%'`): Use
ngram. It splits text into fixed-length n-grams such as bigrams or trigrams.JSON fields: Use
json. It creates inverted indexes on JSON array values or object key values.
If you are unsure which tokenizer fits your data, run dbms_imci.fts_tokenize against sample text from your dataset before creating the index. This shows the exact terms that will be indexed and lets you verify that your queries will match as expected.