PolarDB for MySQL uses Compute Express Link (CXL) 2.0 to decouple compute, memory, and storage into three independent layers. The CXL memory extension, called PolarCXLMem, connects a shared memory pool directly to compute nodes using native Load/Store instructions — the same way the CPU accesses local DRAM. This eliminates the network protocol overhead of Remote Direct Memory Access (RDMA)-based solutions and expands the maximum memory of a single node to 8 TB at 30–50% lower cost per gigabyte than local DRAM. In the sysbench I/O-bound model, this architecture improves performance by more than 100%.
The underlying research, "Unlocking the Potential of CXL for Disaggregated Memory in Cloud-Native Databases," received the Best Paper Award at SIGMOD 2025.
The CXL memory extension is in canary release. To use this feature, submit a ticket.
Applicable scope
MySQL 8.0.2 (minor engine version 8.0.2.2.31.1 or later).
How it works
PolarCXLMem uses the CXL.mem protocol to map CXL memory devices into the host's physical address space. From the database engine's perspective, DRAM and CXL memory form a single, non-hierarchical Buffer Pool — the CPU reads and writes both using native Load/Store instructions with no data copying or page swapping between memory tiers.
PolarCXLMem is distinct from the PolarDB three-layer decoupling (RDMA) architecture. In the RDMA variant, remote memory is accessed over a network stack, which involves data copying between memory levels. PolarCXLMem maps CXL memory directly into the host's physical address space, so the CPU treats it as local memory with no network overhead.
The following diagram shows the PolarCXLMem architecture:
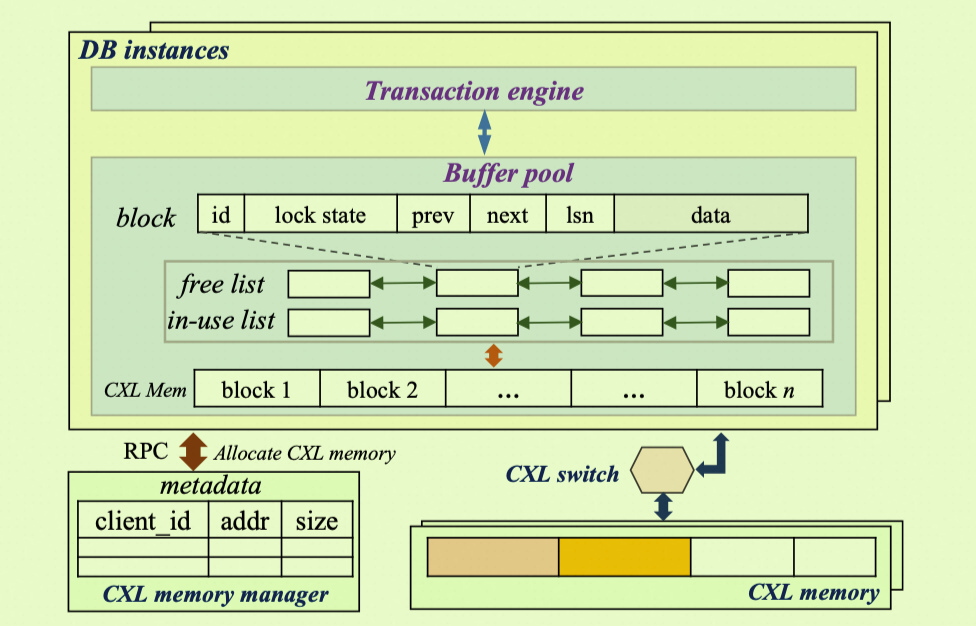
The architecture has three key properties:
A. Unified, non-hierarchical Buffer Pool. DRAM and CXL memory share a single address space. Unlike RDMA-based disaggregated memory, which copies pages across a network, PolarCXLMem maps CXL memory directly into the host's physical address space. This eliminates write amplification and the overhead of moving pages between memory levels.
B. Hardware-level cache coherency. The CXL.cache protocol keeps CPU cache and CXL memory consistent at the hardware level. The database software requires no additional cache management, which simplifies the architecture.
C. Crash recovery in seconds (PolarRecv). PolarRecv leverages the persistence feature of CXL memory. After a crash, the Buffer Pool data on CXL persistent memory is still intact — no redo log replay is needed. The database loads directly from CXL memory and resumes in seconds, reducing the recovery time objective (RTO) by more than 40 times compared to conventional recovery.
In short, PolarCXLMem treats CXL memory as a unified extension of local DRAM, Load/Store as the only access primitive, and CXL persistence as the crash recovery foundation.
Benefits
| Dimension | Detail |
|---|---|
| Cost | CXL memory costs 30–50% less per gigabyte than local DRAM. Compute and memory scale elastically and independently on a pay-as-you-go basis. |
| Capacity | CXL breaks the physical memory slot limits of a single server, expanding the maximum memory of a single compute node to 8 TB. |
| Throughput | Across OLTP workloads — point queries, mixed reads, and mixed reads and writes — adding CXL memory improves cluster throughput by 20–112%. |
| Recovery | PolarRecv cuts crash recovery RTO by more than 40 times, reducing it to seconds. |
Use cases
Memory-intensive OLTP. Social media, gaming, and e-commerce applications require low-latency access to user relationships, product catalogs, and real-time orders. Use CXL memory to cache larger working sets in memory and reduce I/O overhead at lower cost than scaling local DRAM.
Large-scale analytical processing (AP). Complex queries on massive datasets benefit from the expanded capacity of CXL memory, which can hold more data in the Buffer Pool and reduce disk reads caused by memory pressure.
Development and test environments. CXL memory lets you simulate large-memory production configurations at a lower cost, without provisioning full DRAM capacity.
AI training and inference. CXL-based memory pooling is also suitable for AI training and inference scenarios.
Performance test report
The following data is from a specific test environment and is for reference only. Actual performance depends on cluster specifications, workload characteristics, data patterns, and parameter settings.
Test environment
| Plan A (baseline) | Plan B (CXL extension) | |
|---|---|---|
| Cluster | 8 cores, 32 GB DRAM | 8 cores, 32 GB DRAM + 64 GB CXL |
| Total available memory | 32 GB | 96 GB |
| Edition | Enterprise Edition, Dedicated | Enterprise Edition, Dedicated |
| Engine version | MySQL 8.0.2 | MySQL 8.0.2 |
Test data: 40 tables, 10,000,000 rows per table.
This test measures the throughput gain from expanding memory capacity with CXL. It does not compare CXL memory against an equivalent amount of DRAM. The primary variable is total Buffer Pool size, which determines how much data fits in memory and how often the database must read from disk.
Test results
After adding 64 GB of CXL memory, overall cluster queries per second (QPS) increased by up to 112%, because a larger Buffer Pool reduces disk I/O.
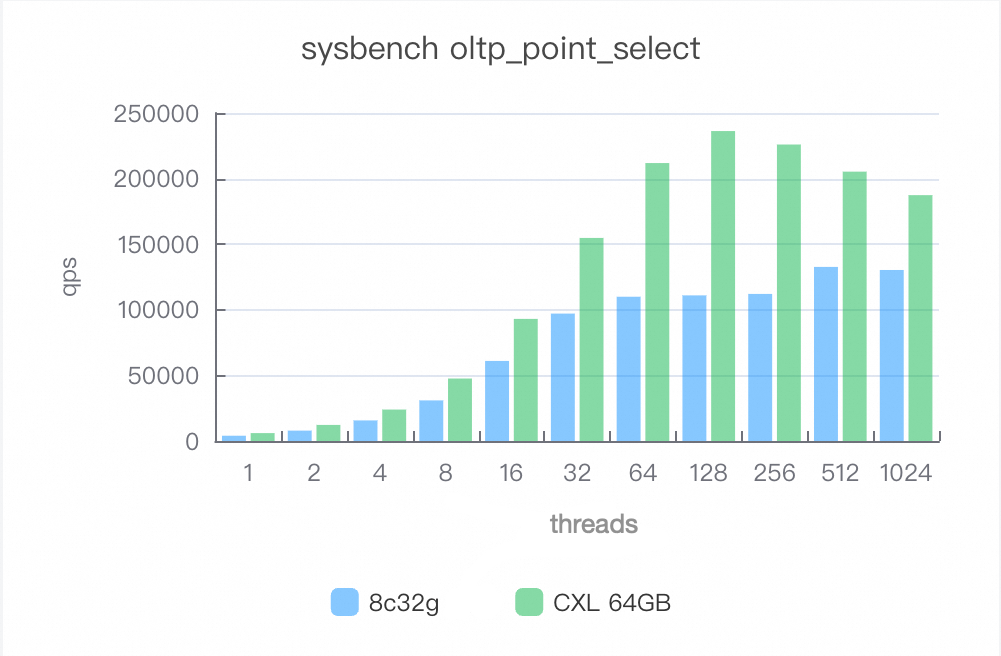
Point queries (oltp_point_select)
After enabling CXL memory, performance improves by 50–112%.
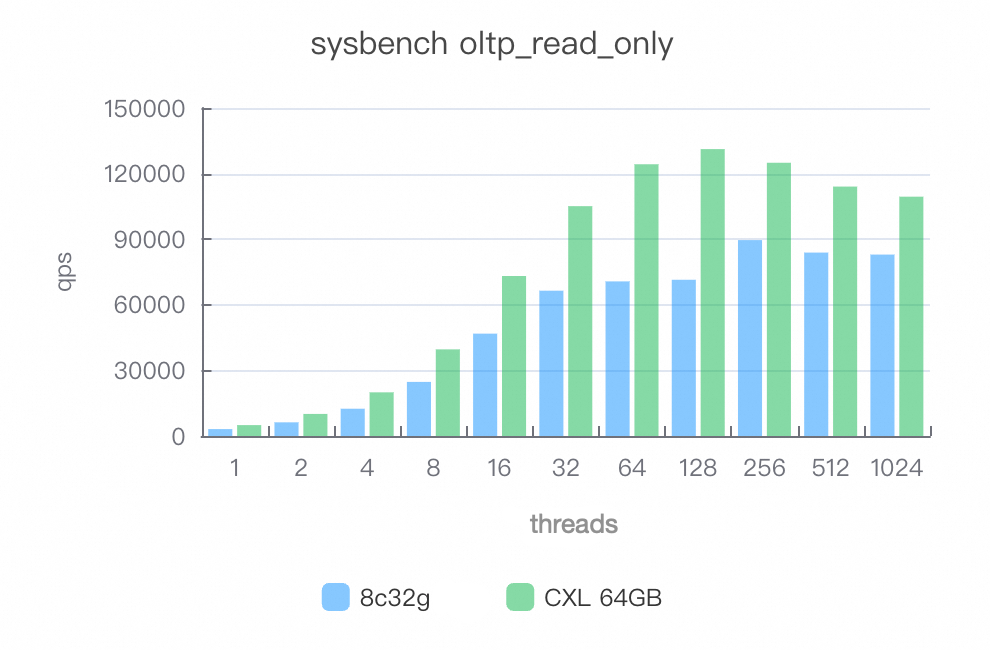
Mixed reads (oltp_read_only)
After enabling CXL memory, performance improves by 30–80%.
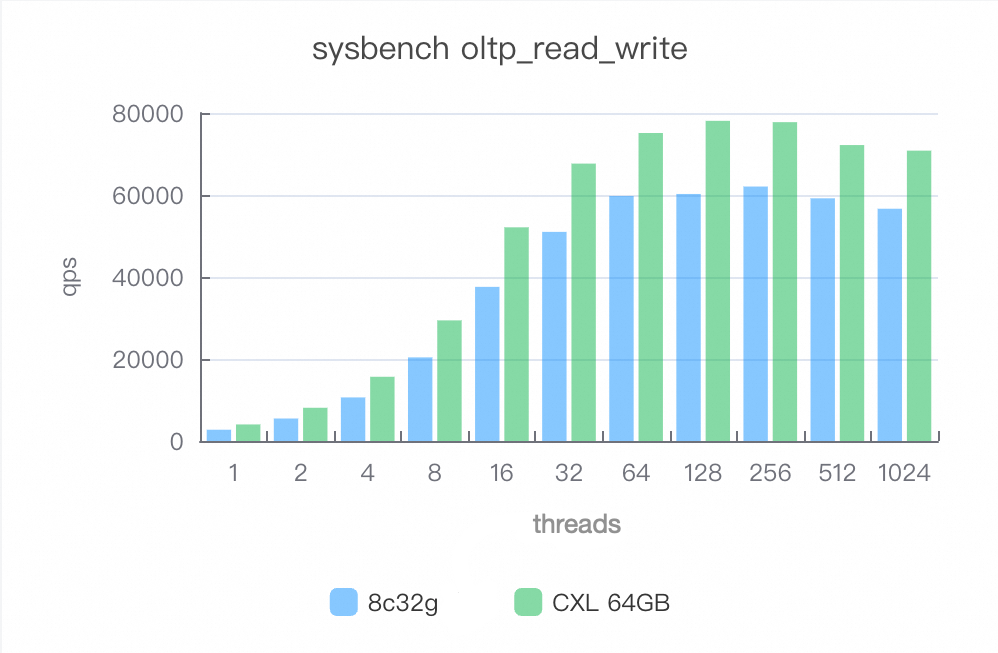
Mixed reads and writes (oltp_read_write)
After enabling CXL memory, performance improves by 20–50%.