This topic describes how to manage buffers.
Background information
- Future pages
Future pages are pages that have replayed more write-ahead logging (WAL) records than the read-only nodes. For example, when the read-only nodes have replayed WAL records up to the record with a log sequence number (LSN) of 200, future pages may have already replayed WAL records up to LSN 300.
- Outdated pages
Outdated pages are pages that have replayed fewer WAL records than the read-only nodes. For example, when the read-only nodes have replayed WAL records up to the record with an LSN of 200, outdated pages only replayed WAL records that have an LSN of less than 200.
Under normal circumstances, read-only nodes should read only pages that have replayed WAL records up to the same LSN as the nodes. However, if you notice that your read-only nodes read future or outdated pages from the shared storage, you can perform the following operations:- In the case of outdated pages, read-only nodes need to replay WAL records to the LSNs of the nodes when they read the pages. If different read-only nodes have different LSNs, the number of WAL records replayed on the pages will be different. This operation is performed by the replay function of the read-only nodes.
- In the case of future pages, read-only nodes are unable to perform any actions to rectify the data inconsistencies. This can be solved only by taking into account the replay speed of the read-only nodes and configuring the write speed of the primary node to shared storage. If the write speed of the primary node is slower than the replay speed of the read-only nodes, then future pages can be prevented. This can be achieved through buffer management.
Terms
| Term | Description |
|---|---|
| Buffer pool | A buffer pool is an amount of memory that is used to store frequently accessed data. In most cases, data is cached in the buffer pool as pages. In a PolarDB cluster, each node has its own buffer pool. |
| LSN | An LSN is the unique identifier of a WAL record. LSNs increase monotonically with each new record across the system. |
| Apply LSN | The apply LSN of a page on a read-only node indicates the most recent WAL record that is replayed on the read-only node for the page. |
| Oldest apply LSN | The oldest apply LSN of a page is the earliest LSN among the current apply LSNs of the page on all the read-only nodes. |
Flushing control
PolarDB provides the flushing control feature to prevent the read-only nodes from reading future pages from the shared storage. Before the primary node writes a page to the shared storage, the primary node checks whether all the read-only nodes have replayed the most recent WAL record of the page.
- Latest LSN: The latest LSN of a page on a read-only node marks the most recent WAL record that is replayed on the read-only node for the page.
- Oldest apply LSN: The oldest apply LSN of a page is the earliest LSN among the current apply LSNs of the page on all the read-only nodes.
if buffer latest lsn <= oldest apply lsn
flush buffer
else
do not flush bufferConsistency LSNs
To replay the WAL records of a page up to a specified LSN, each read-only node manages the mapping between the page and the LSNs of all WAL records that are generated for the page. This mapping is stored in a LogIndex. A LogIndex is a persistent hash table. When a read-only node requests a page, the read-only node scans the LogIndex of the page to obtain the LSNs of all WAL records that need to be replayed. Then, the read-only node replays the WAL records in sequence to generate the most recent version of the page. The more changes that are made to a page, the larger the difference in LSNs, which means that more WAL records need to be replayed. To minimize the number of WAL records that need to be replayed for each page, PolarDB provides consistency LSNs.
After all changes that are made up to the consistency LSN of a page are written to the shared storage, the page is flushed to persistent storage. The primary node sends the write LSN and consistency LSN of the page to each read-only node, and each read-only node sends the apply LSN of the page to the primary node. The read-only nodes do not need to replay the WAL records that are generated before the consistency LSN of the page. Therefore, all LSNs that are smaller than the consistency LSN can be removed from the LogIndex of the page. This reduces the number of WAL records that the read-only nodes need to replay and reduces the storage space that is occupied by LogIndex records.
- Flush list
PolarDB holds a specific state for each buffer in the memory. The state of a buffer in the memory is represented by the LSN that marks the first change to the buffer. This LSN is called the oldest LSN. The consistency LSN of a page is the smallest oldest LSN among the oldest LSNs of all buffers for the page.
The conventional method of obtaining the consistency LSN of a page requires the primary node to scan the LSNs of all buffers for the page in the buffer pool. This method causes significant CPU overhead and requires a large amount of time. To address these issues, PolarDB uses a flush list, in which all dirty pages in the buffer pool are sorted in ascending order based on their oldest LSNs. The flush list helps reduce the time required to obtain consistency LSNs to O(1).
When a buffer is updated for the first time, the buffer is labeled as dirty. PolarDB inserts the buffer into the flush list and generates an oldest LSN for the buffer. When the buffer is flushed to the shared storage, the label is removed.
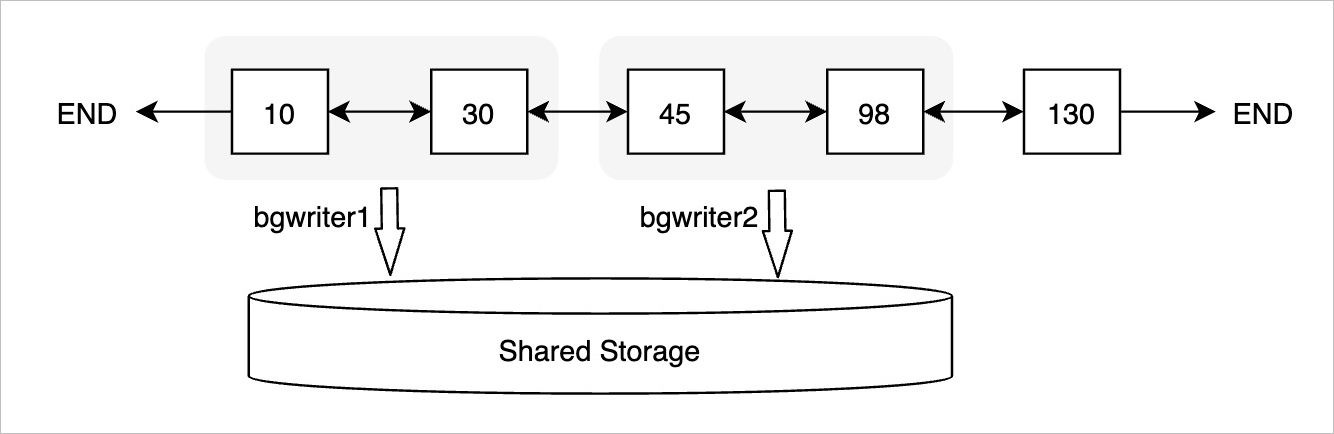
To efficiently move the consistency LSN of each page towards the head of the flush list, PolarDB runs a BGWRITER process to scan all buffers in the flush list in chronological order and flush early buffers to the shared storage one by one. After a buffer is flushed to the shared storage, the consistency LSN is moved one position forward towards the head of the flush list. As shown in the preceding figure, if the buffer with an oldest LSN of 10 is flushed to the shared storage, the buffer with an oldest LSN of 30 is moved one position forward towards the head of the flush list. LSN 30 becomes the consistency LSN.
- Parallel flushingTo further improve the efficiency of moving the consistency LSN of each page to the head of the flush list, PolarDB runs multiple BGWRITER processes to flush buffers in parallel. Each BGWRITER process reads a number of buffers from the flush list and flushes the buffers to the shared storage at a time.
Hot buffers
After the flushing control mechanism is introduced, PolarDB flushes only the buffers that meet specific flush conditions to the shared storage. If a buffer is frequently updated, its latest LSN may be larger than its oldest apply LSN. As a result, the buffer can never meet the flush conditions. This type of buffers are called hot buffers. If a page has hot buffers, the consistency LSN of the page cannot be moved towards the head of the flush list. To resolve this issue, PolarDB provides a copy buffering mechanism.
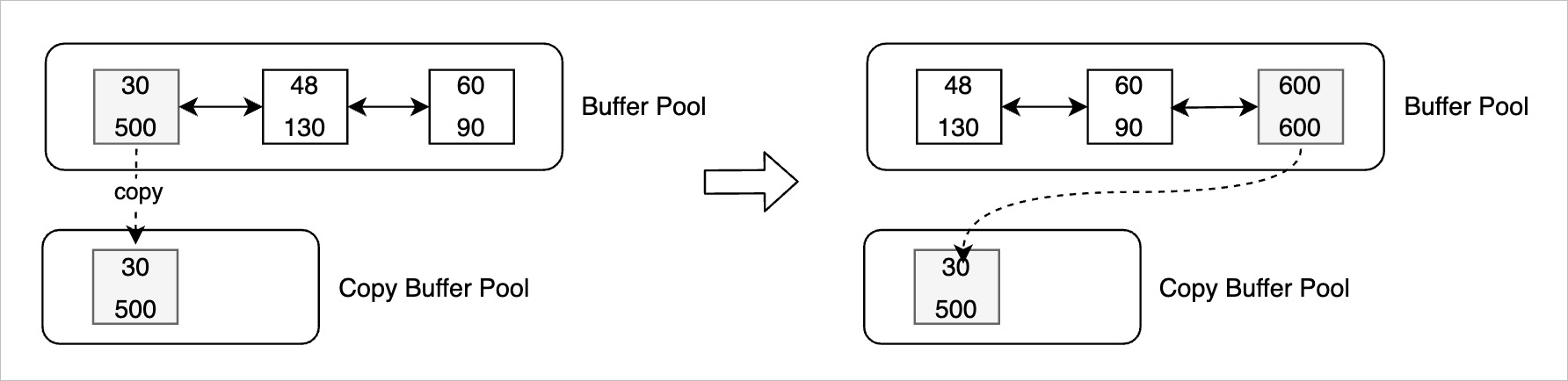
The copy buffering mechanism allows PolarDB to copy buffers that do not meet the flush conditions to a copy buffer pool. Buffers in the copy buffer pool and their latest LSNs are no longer updated. As the oldest apply LSN moves towards the head of the flush list, these buffers begin to meet the flush conditions. When these buffers meet the flush conditions, PolarDB can flush them from the copy buffer pool to the shared storage.
- If a buffer does not meet the flush conditions, PolarDB checks the number of recent changes to the buffer and the time difference between the most recent change and the latest LSN. If the number and the time difference exceed their predefined thresholds, PolarDB copies the buffer to the copy buffer pool.
- When a buffer is updated again, PolarDB checks whether the buffer meets the flush conditions. If the buffer meets the flush conditions, PolarDB flushes the buffer to the shared storage and deletes the copy of the buffer from the copy buffer pool.
- If a buffer does not meet the flush conditions, PolarDB checks whether a copy of the buffer can be found in the copy buffer pool. If a copy of the buffer can be found in the copy buffer pool and the copy meets the flush conditions, PolarDB flushes the copy to the shared storage.
- After a buffer that is copied to the copy buffer pool is updated, PolarDB regenerates an oldest LSN for the buffer and moves the buffer to the tail of the flush list.
Lazy checkpoints
PolarDB supports consistency LSNs, which are similar to checkpoints. All changes that are made to a page before the checkpoint LSN of the page are flushed to the shared storage. If a recovery operation is run, PolarDB starts to recover the page from the checkpoint LSN. This improves recovery efficiency. If regular checkpoint LSNs are used, PolarDB flushes all dirty pages in the buffer pool and other in-memory pages to the shared storage. This process may require a long period of time and high I/O throughput. As a result, normal queries may be affected.
Consistency LSNs enable PolarDB to implement lazy checkpointing. If the lazy checkpointing mechanism is used, PolarDB does not flush all dirty pages in the buffer pool to the shared storage. Instead, PolarDB uses consistency LSNs as checkpoint LSNs. This significantly increases checkpointing efficiency.