Elastic Algorithm Service (EAS) pushes two types of events to CloudMonitor in real time: Service events (service-level) and ServiceInstance events (pod instance-level). Use these events to monitor your inference services, trigger alert notifications when a pod crashes or a spot instance is preempted, audit configuration changes, and automate operational responses — for example, by routing critical events to a notification service or invoking a function to restart a failed pod.
View EAS events
Use the console
-
Log on to the CloudMonitor console.
-
In the left navigation pane, choose Event Center > System Event.
-
On the Event Monitoring tab, select PAI from the product drop-down list, and click Search.

-
In the Actions column of the target event, click Details to view the event details. Example:
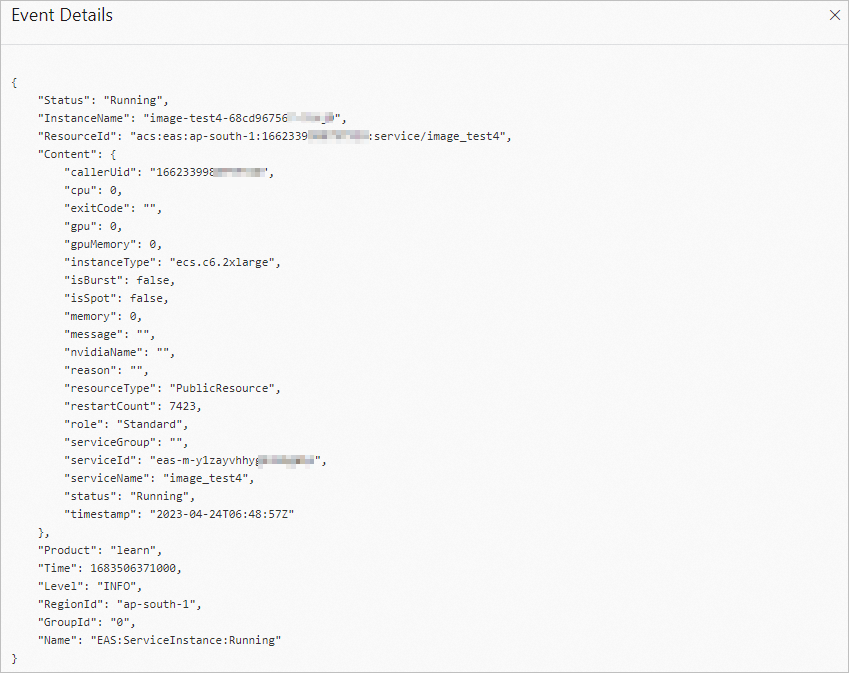
Event parameters
| Parameter | Description |
|---|---|
| Product | The service code. For Platform for AI (PAI), the code is learn. |
| Name | The event name. See the Name column in Supported EAS events. |
| Level | The event level: INFO, WARN, or CRITICAL. |
| Status | The event status. See the Status column in Supported EAS events. |
| RegionId | The region ID of the service, for example, cn-shanghai for China (Shanghai). |
| ResourceId | The resource ID. See Policy description. |
| InstanceName | The service name or service instance name. |
| Time | The time the event occurred, expressed as a UNIX millisecond timestamp. |
| GroupId | The CloudMonitor application group that the EAS service belongs to. Empty by default. |
| Content | The core content of the event. For Service events, this is a plain string. For ServiceInstance events, this is a JSON object — see Fields of the Content parameter. |
Fields of the Content parameter
The Content field for ServiceInstance events is a JSON object. Example:
{
"serviceName": "my-inference-service",
"serviceId": "eas-cn-shanghai-1234567",
"serviceGroup": "default",
"resourceType": "DedicatedResource",
"instanceType": "ecs.gn6i-c4g1.xlarge",
"cpu": 4,
"memory": 16384,
"gpu": 1,
"gpuMemory": 16,
"nvidiaName": "Tesla T4",
"role": "Standard",
"isBurst": false,
"isSpot": false,
"callerUid": "123456789012345678",
"timestamp": 1711929600000,
"restartCount": 2,
"exitCode": "1",
"status": "CrashLoopBackOff",
"reason": "OOMKilled",
"message": "Container killed due to out-of-memory condition"
}Field descriptions:
| Field | Description |
|---|---|
| serviceName | The service name of the instance. |
| serviceId | The service ID of the instance. |
| serviceGroup | The service group the instance belongs to. |
| resourceType | The resource group type: PublicResource (public resource group) or DedicatedResource (dedicated resource group). |
| instanceType | The instance type. |
| cpu | The number of CPUs used by the instance. |
| memory | The memory used by the instance, in MB. |
| gpu | The number of GPUs used by the instance. |
| gpuMemory | The GPU memory used by the instance, in GB. |
| nvidiaName | The name of the GPU used by the instance. |
| role | The service role: Queue (queue service), DataLoader (offline service), or Standard (standard service). |
| isBurst | Whether auto scaling is enabled for the instance's resource group: true or false. |
| isSpot | Whether the instance is a preemptible instance: true or false. |
| callerUid | The UID of the Alibaba Cloud account used to deploy the EAS service. |
| timestamp | The last startup time of the container. |
| restartCount | The number of times the instance has been restarted. |
| exitCode | The exit status code of the instance. Empty by default. |
| status | The status of the instance. See the Status column in Supported EAS events. |
| reason | The reason the event occurred. |
| message | The event message. |
Use the API
Call DescribeSystemEventAttribute to retrieve EAS events programmatically.
Create and enable alert rules
Set up alert rules to receive notifications when specific EAS events occur — for example, when a pod enters CrashLoopBackOff or a spot instance is about to be released.
Use CRITICAL event levels for events that require immediate action (such as CrashLoopBackOff or Unavailable) and WARN for events that warrant investigation (such as ErrImagePull or Evicted).
Use the console
-
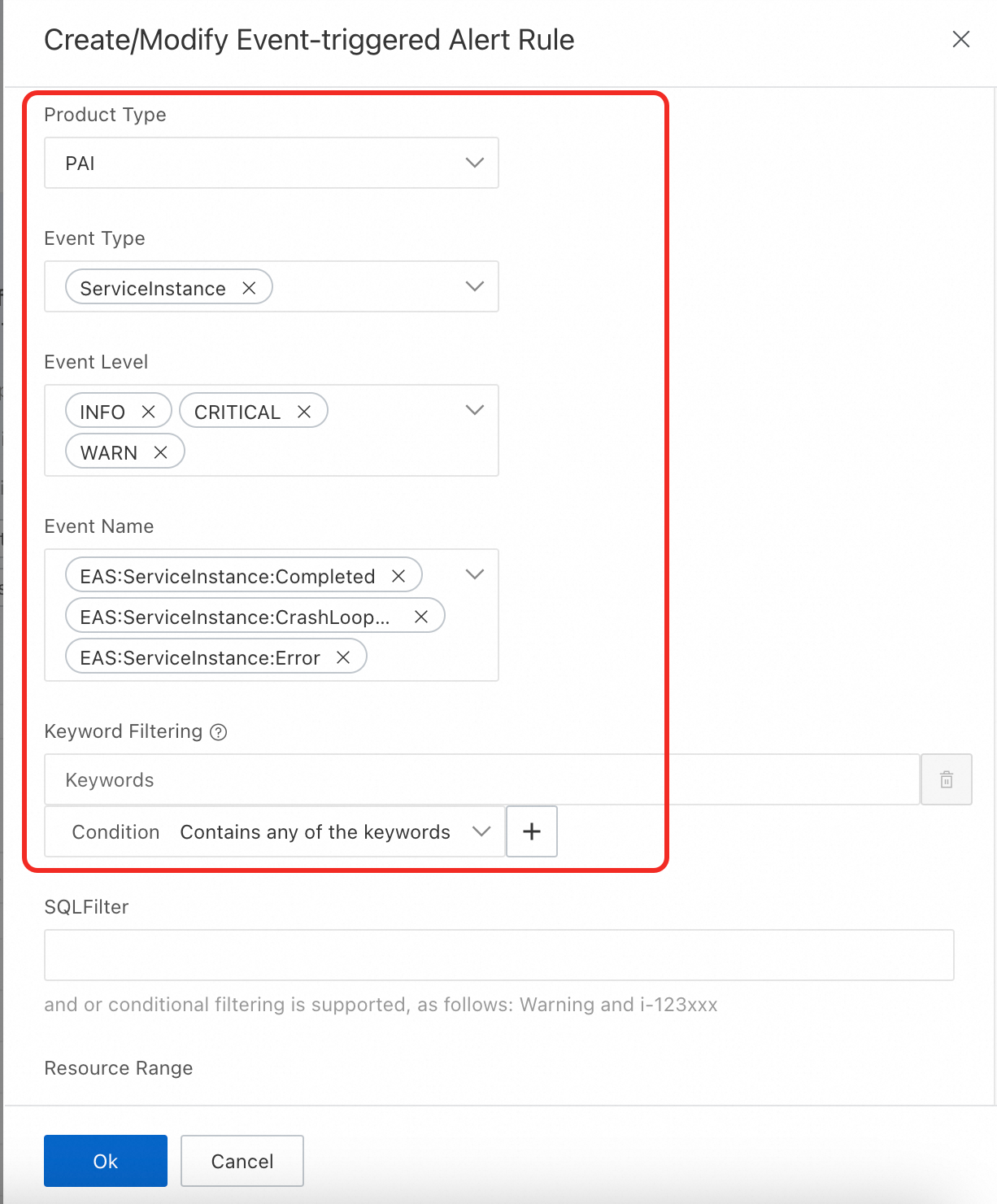
Create a system event-triggered alert rule. Configure the following parameters:
-
Product type: Select PAI.
-
Event type: Select ServiceInstance or Service.
-
Event level: Select one or more event levels.
-
Event name: Select one or more event names from the Name column in Supported EAS events.
-
Keyword filtering: Enter keywords to match against event content and filter which events trigger the alert.
-
-
(Optional) Use alert callbacks for system events (legacy) to send event data to an external endpoint, such as a webhook or notification service.
Use the API
FAQ
Does a service instance refer to an inference service or a pod?
A service instance refers to a pod instance, not the inference service itself. The Service event type covers service-level changes (such as replica count changes or service unavailability), while the ServiceInstance event type covers pod-level events (such as pod restarts, image pull failures, or preemption).
Appendix: Supported EAS events
EAS defines service-level and service instance-level events as follows.
| Type | Name | Event level | Status | Description |
|---|---|---|---|---|
| ServiceInstance | EAS:ServiceInstance:Running | INFO | Running | The pod is running normally. |
| EAS:ServiceInstance:Pending | INFO | Pending | The pod is waiting to be scheduled or started. | |
| EAS:ServiceInstance:Completed | INFO | Completed | The pod has completed execution. | |
| EAS:ServiceInstance:Terminating | INFO | Terminating | The pod is in the process of being terminated. | |
| EAS:ServiceInstance:Terminated | INFO | Terminated | The pod has been terminated. | |
| EAS:ServiceInstance:Unknown | WARN | Unknown | The pod state cannot be determined, typically due to a communication error with the node. | |
| EAS:ServiceInstance:Evicted | WARN | Evicted | The pod was evicted due to resource pressure on the node. | |
| EAS:ServiceInstance:ErrImagePull | WARN | ErrImagePull | The container image could not be pulled, often due to an invalid image reference or missing credentials. | |
| EAS:ServiceInstance:ImagePullBackOff | WARN | ImagePullBackOff | Image pull is being retried after repeated failures. | |
| EAS:ServiceInstance:CrashLoopBackOff | CRITICAL | CrashLoopBackOff | The container is repeatedly crashing. Check the exitCode and reason fields for the root cause. |
|
| EAS:ServiceInstance:Error | CRITICAL | Error | The pod encountered a runtime error. | |
| EAS:ServiceInstance:Failed | CRITICAL | Failed | The pod failed to start or complete successfully. | |
| EAS:ServiceInstance:SpotToBeReleased | WARN | SpotToBeReleased | The preemptible instance is about to be released. Prepare for service disruption or failover. | |
| Service | EAS:Service:ReplicasChanged | INFO | ReplicasChanged | The number of replicas for the service has changed, for example, due to auto scaling. |
| EAS:Service:StatusChanged | INFO | StatusChanged | The service status has changed. | |
| EAS:Service:Unavailable | CRITICAL | Unavailable | The service is unavailable and cannot process requests. | |
| EAS:Service:UpdateFailed | CRITICAL | UpdateFailed | A service update failed to apply. |