Swing is an item recall algorithm. Use the Swing Train component to measure item similarity based on user-item-user principles.
Limits
Supported compute engines: MaxCompute and Realtime Compute for Apache Flink.
Configure the component
Configure the component by using one of the following methods:
Method 1: Configure the component in Machine Learning Designer
Configure the following parameters on the pipeline configuration tab.
| Tab | Parameter | Description |
| Field Setting | itemCol | Name of the item column. |
| userCol | Name of the user column. | |
| Parameter Setting | alpha | Smoothing factor. Default value: 1.0. |
| maxItemNumber | Maximum number of users per item for calculation. Default value: 1000. Note If an item exceeds this count, the algorithm randomly samples this number of users. |
|
| maxUserItems | Maximum number of items per user for calculation. Default value: 1000. Note Users exceeding this item count are excluded from calculation. |
|
| minUserItems | Minimum number of items per user for calculation. Default value: 10. Note Users below this item count are excluded from calculation. |
|
| resultNormalize | Whether to normalize results. | |
| userAlpha | Alpha parameter for users. Default value: 5.0. | |
| userBeta | Beta parameter for users. Default value: -0.35. | |
| Execution Tuning | Number of Workers | Number of worker nodes. Must be used with Memory per worker, unit MB. Valid values: 1 to 9999. |
| Memory per worker, unit MB | Memory per worker node, in MB. Valid values: 1024 to 65536. |
Method 2: Use Python code
Configure component parameters with Python code. Run the code with the Python Script V2 component. For more information, see Python Script.
Sample code:
| Parameter | Required | Description | Default value |
| itemCol | Yes | Name of the item column. | None |
| userCol | Yes | Name of the user column. | None |
| alpha | No | Alpha smoothing factor. | 1.0 |
| userAlpha | No | Alpha parameter for users. Note Used to calculate user weight: weight = 1.0/(userAlpha + userClickCount)^userBeta. |
5.0 |
| userBeta | No | Beta parameter for users. Note Used to calculate user weight: weight = 1.0/(userAlpha + userClickCount)^userBeta. |
-0.35 |
| resultNormalize | No | Whether to normalize results. | false |
| maxItemNumber | No | Maximum number of users per item for calculation. Note If an item exceeds this count, the algorithm randomly samples this number of users. |
1000 |
| minUserItems | No | Minimum number of items per user for calculation. Note Users below this item count are excluded from calculation. |
10 |
| maxUserItems | No | Maximum number of items per user for calculation. Note Users exceeding this item count are excluded from calculation. |
1000 |
df_data = pd.DataFrame([
["a1", "11L", 2.2],
["a1", "12L", 2.0],
["a2", "11L", 2.0],
["a2", "12L", 2.0],
["a3", "12L", 2.0],
["a3", "13L", 2.0],
["a4", "13L", 2.0],
["a4", "14L", 2.0],
["a5", "14L", 2.0],
["a5", "15L", 2.0],
["a6", "15L", 2.0],
["a6", "16L", 2.0],
])
data = BatchOperator.fromDataframe(df_data, schemaStr='user string, item string, rating double')
model = SwingTrainBatchOp()\
.setUserCol("user")\
.setItemCol("item")\
.setMinUserItems(1)\
.linkFrom(data)
model.print()
predictor = SwingRecommBatchOp()\
.setItemCol("item")\
.setRecommCol("prediction_result")
predictor.linkFrom(model, data).print()Example
The following figure shows a sample Swing Train pipeline. 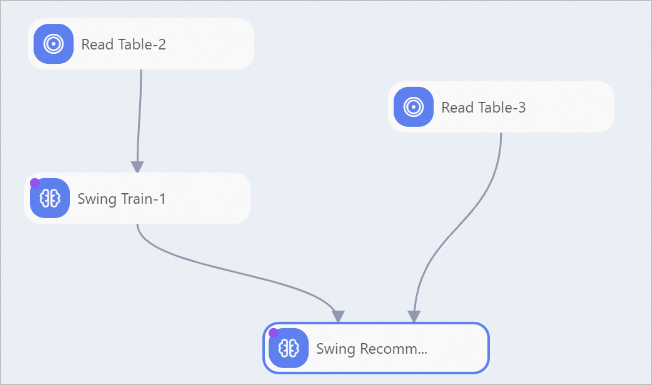 Configure the components as follows:
Configure the components as follows:
Configure the components as follows:- Prepare a training dataset and a test dataset.
- Create two MaxCompute tables: Table 1 with userid and itemid fields, and Table 2 with the itemid field. All fields are STRING type. Upload the training dataset to Table 1 and the test dataset to Table 2 by using the tunnel command. Set Read Table-1 to Table 1 and Read Table-2 to Table 2. For more information about how to install and configure the MaxCompute client, see Connect using the local client (odpscmd). For more information about Tunnel commands, see Tunnel commands.
- Import the training dataset to the Swing Train component and configure the parameters as described in Method 1: Configure the component in Machine Learning Designer.
- Import the test dataset and the model to the Swing prediction component for prediction.