PerfTracker is an online tool for performance analysis and diagnostics of large-scale model training. It performs high-precision, online monitoring of full-stack software and hardware. If a job experiences performance issues, PerfTracker collects the execution records for all CUDA kernel functions and Python functions from each worker, along with hardware monitoring records. It then generates an analysis report to automatically diagnose the causes of performance loss. This includes locating slow nodes, identifying bottleneck functions or functions with abnormally long execution times, and detecting hang issues. This topic describes how to use PerfTracker.
Limitation
Currently, PerfTracker supports only PyTorch framework jobs.
Function introduction
Key features
Collects job execution records online. When a job has performance issues, PerfTracker collects the execution records of all functions for each worker, including CUDA kernel functions and Python functions. It also collects high-precision monitoring data for hardware, such as GPUs, NVLink, PCIe, and DRAM, at 100-microsecond granularity.
Performs function-level performance analysis. PerfTracker processes high-precision hardware and software monitoring data to generate performance reports for each function. It automatically diagnoses the causes of performance loss, such as slow nodes and bottleneck functions or functions with abnormally long execution times. This provides a basis for in-depth manual analysis and guides performance optimization efforts.
Solutions
Collects fine-grained function execution records for online training jobs. This online, high-granularity data collection improves the real-time performance and accuracy of diagnostics compared to offline reproduction and profiling.
Uses efficient performance analysis algorithms based on function execution records from multiple nodes. PerfTracker automates tasks that typically require manual performance analysis expertise, which enables efficient performance analysis and problem identification.
How it works
PerfTracker consists of a Collector and PerfDisplay. The Collector runs inside the user's job container and is independent of the training job process. PerfDisplay provides a visualization page that you can open on your local machine. The following figure shows the architecture of PerfTracker.
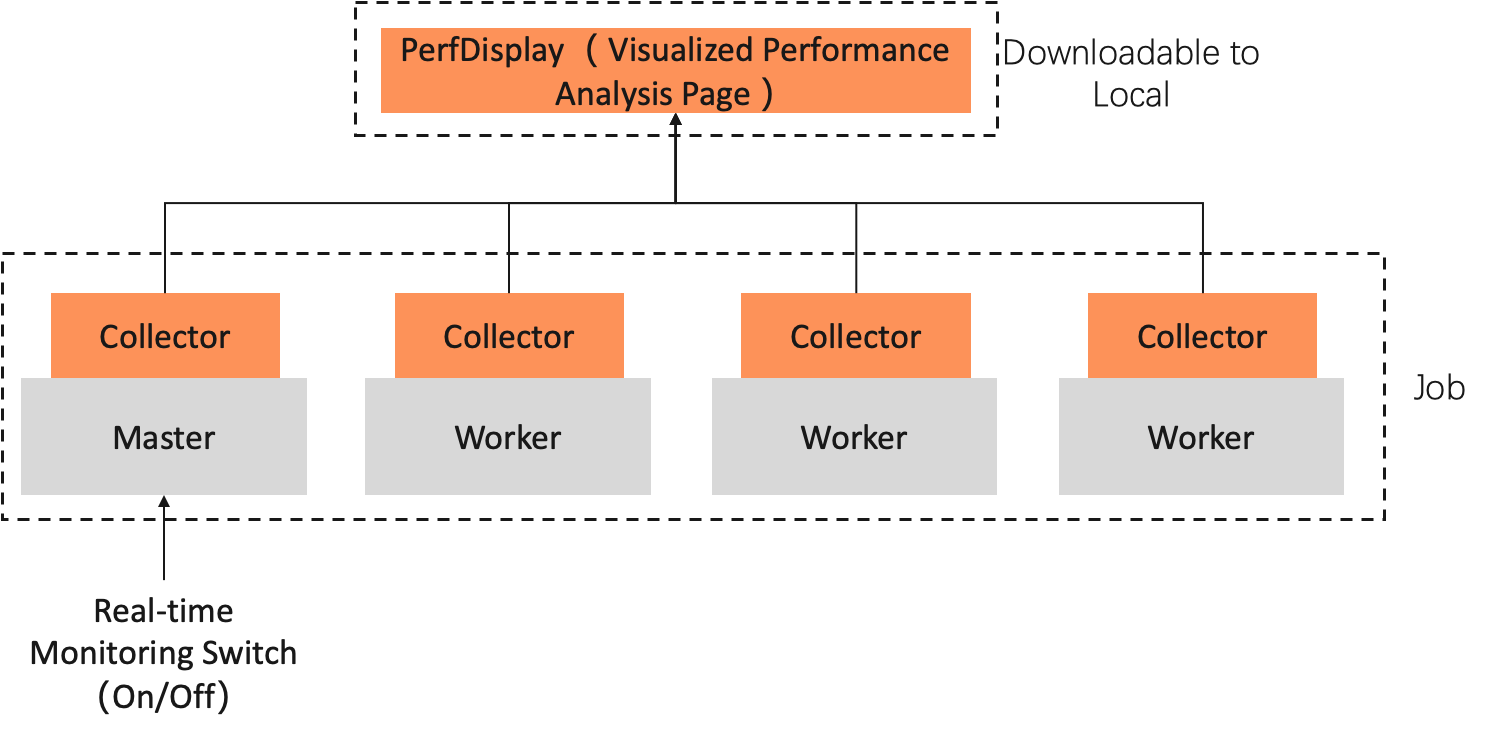
PerfTracker Collector: Performs high-precision online monitoring of full-stack information. It uses the Torch profiler API and nsys to collect raw monitoring data. A PerfTracker Collector can collect the following types of data:
Execution records of all functions during job runtime. This includes CUDA kernel functions such as compute and communication kernels, functions that launch kernels to the GPU, GPU memory operations, and Python functions. This data is used for code-level performance analysis and provides a complete record of program behavior.
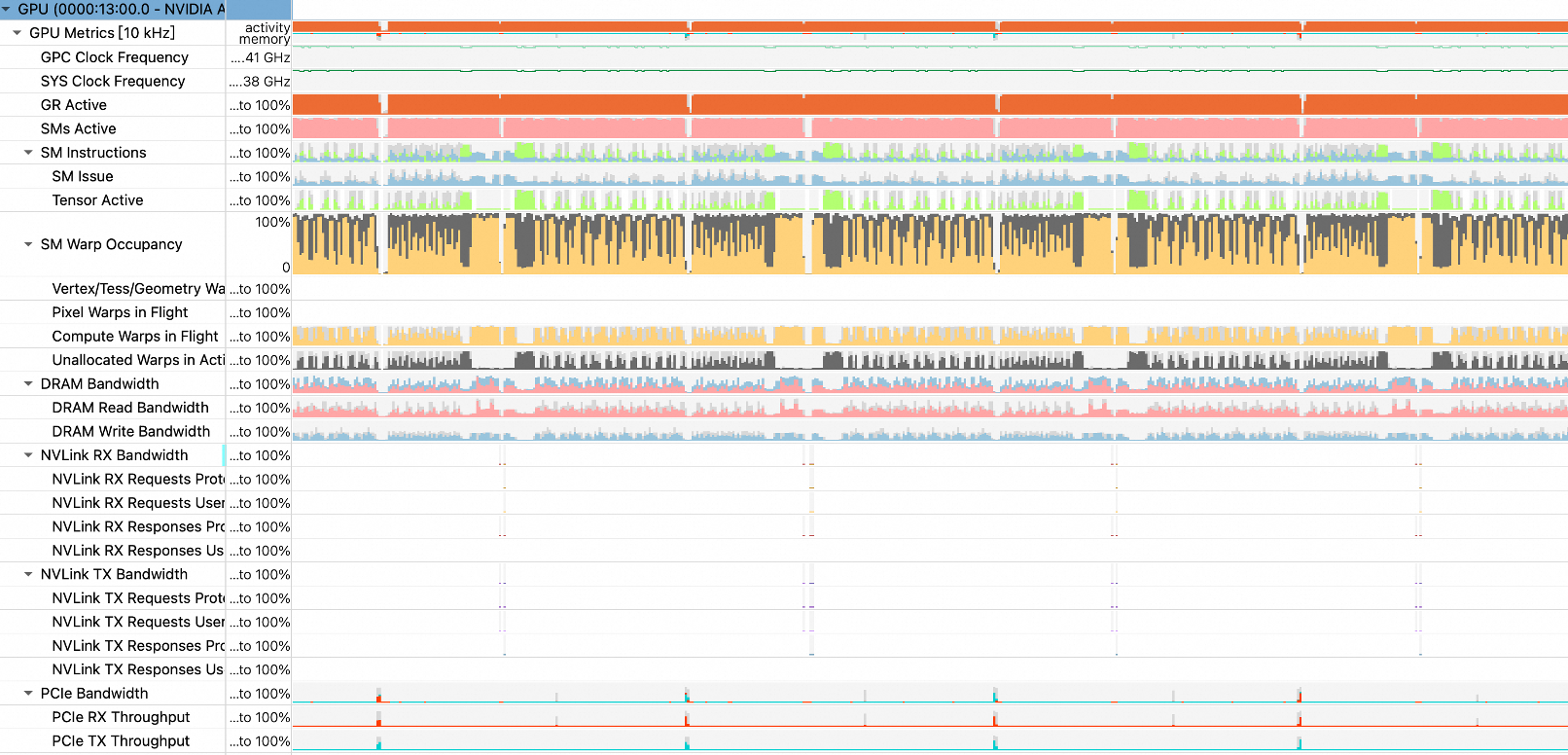
Monitoring data for various hardware metrics, such as GPUs, NVLink, PCIe, and DRAM, at 100-microsecond precision.
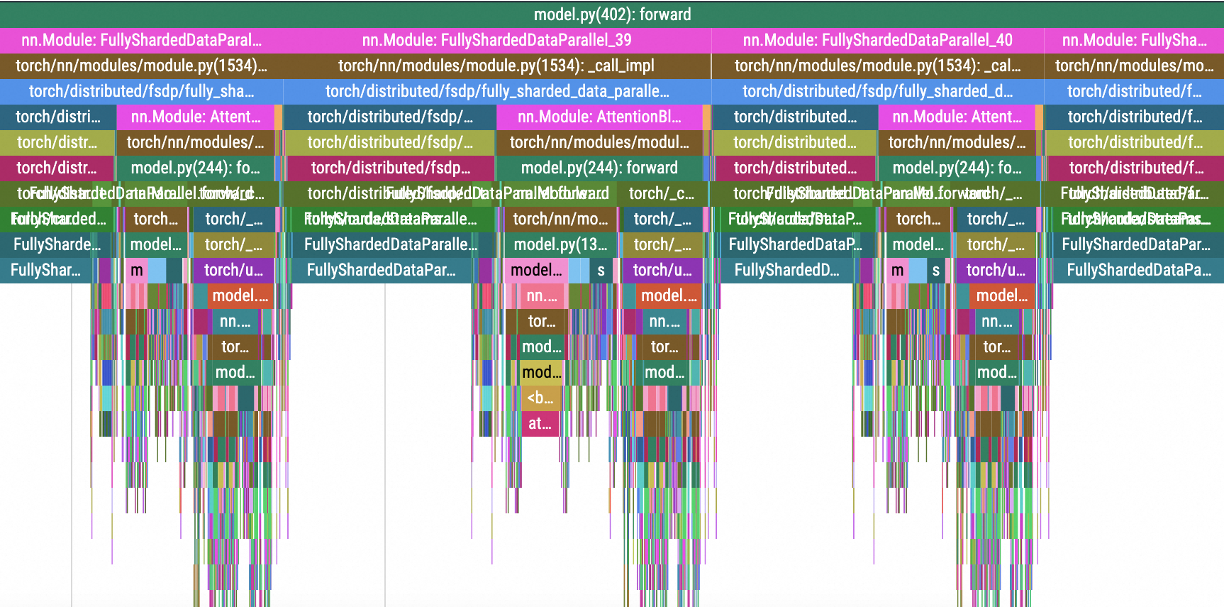
The following figure shows examples of the collected data.
CUDA kernel functions and GPU memory operations

Python functions and GPU kernel launch operations
Hardware monitoring data
PerfDisplay: Summarizes and analyzes the collected data to generate performance analysis reports and visual outputs.
How to use
Preparations
Prepare the training code. Import the PerfTracker module and mark the steps.
Import the PerfTracker module at the beginning of the training code. The following is sample code:
try: from c4d_perftracker_collector.PerfTracker import PerfTracker my_tracer = PerfTracker() except: my_tracer = NoneMark the steps in the training code.
To use PerfTracker, you must mark steps in the training code. Each time tracer.step() is executed, PerfTracker records it. This allows the background process to control the number of iterations for which to collect data.
while iteration < args.train_iters: ... # Training code if my_tracer is not None: my_tracer.step() # Mark a step
The following is a simple training.py code example that includes the import and step marking:
import torch import time import torch.distributed as dist import argparse try: from c4d_perftracker_collector.PerfTracker import PerfTracker my_tracer = PerfTracker() except: my_tracer = None dist.init_process_group("nccl") torch.cuda.set_device(dist.get_rank()) # Check if CUDA is available. if torch.cuda.is_available(): print("CUDA is available!") device = torch.device('cuda') # Use the default CUDA device. else: print("CUDA is not available.") device = torch.device('cpu') # If CUDA is not available, use the CPU. def matmul(): matrix_a = torch.randn(1000, 1000) matrix_b = torch.randn(1000, 1000) # Move the matrices to the CUDA device. matrix_a = matrix_a.to(device) matrix_b = matrix_b.to(device) # Perform matrix multiplication. result = torch.matmul(matrix_a, matrix_b) result_cpu = result.to('cpu') print(result_cpu) del matrix_a, matrix_b, result torch.cuda.empty_cache() for i in range(1000): matmul() time.sleep(dist.get_rank()) print("Epoch:", i) if my_tracer is not None: my_tracer.step() dist.barrier()Upload the prepared training code file (training.py) to your storage directory. This example uses an Object Storage Service (OSS) bucket.
Create a training job
When you create a training job, add a startup command to download and install PerfTracker. The other configurations are the same as for a regular job. After you complete the configuration, click OK to create the job. The following is an example:
Parameter
Description
Environment Information
Image config
Select PyTorch 2.0 or later. This example uses
easyanimate:1.1.5-pytorch2.2.0-gpu-py310-cu118-ubuntu22.04.Mount storage
Click OSS. Select the OSS directory where the training code file is stored. Set Mount Path to
/mnt/data/.Startup Command
# Download the PerfTracker installation package. wget -t 5 -w 2 -P /mnt/data https://network-research-lingjun-open-oss.oss-cn-hangzhou.aliyuncs.com/files/c4d_perftracker_collector-1.4.0-py3-none-any.whl # Install PerfTracker. pip3 install /mnt/data/c4d_perftracker_collector-1.4.0-py3-none-any.whl # Run the training code. For example, training.py. CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 torchrun --nproc_per_node=4 /mnt/data/training.py/mnt/data/is the dataset mount path. Replace it with your directory.NoteFor large-scale tasks, downloading the installation package at startup may be slow because of high concurrency. Download the PerfTracker installation package to your storage directory from the command line before you start the task.
Resource Information
Framework
Select PyTorch.
Job Resource
Select a resource specification. This example uses
ecs.gn6e-c12g1.12xlarge.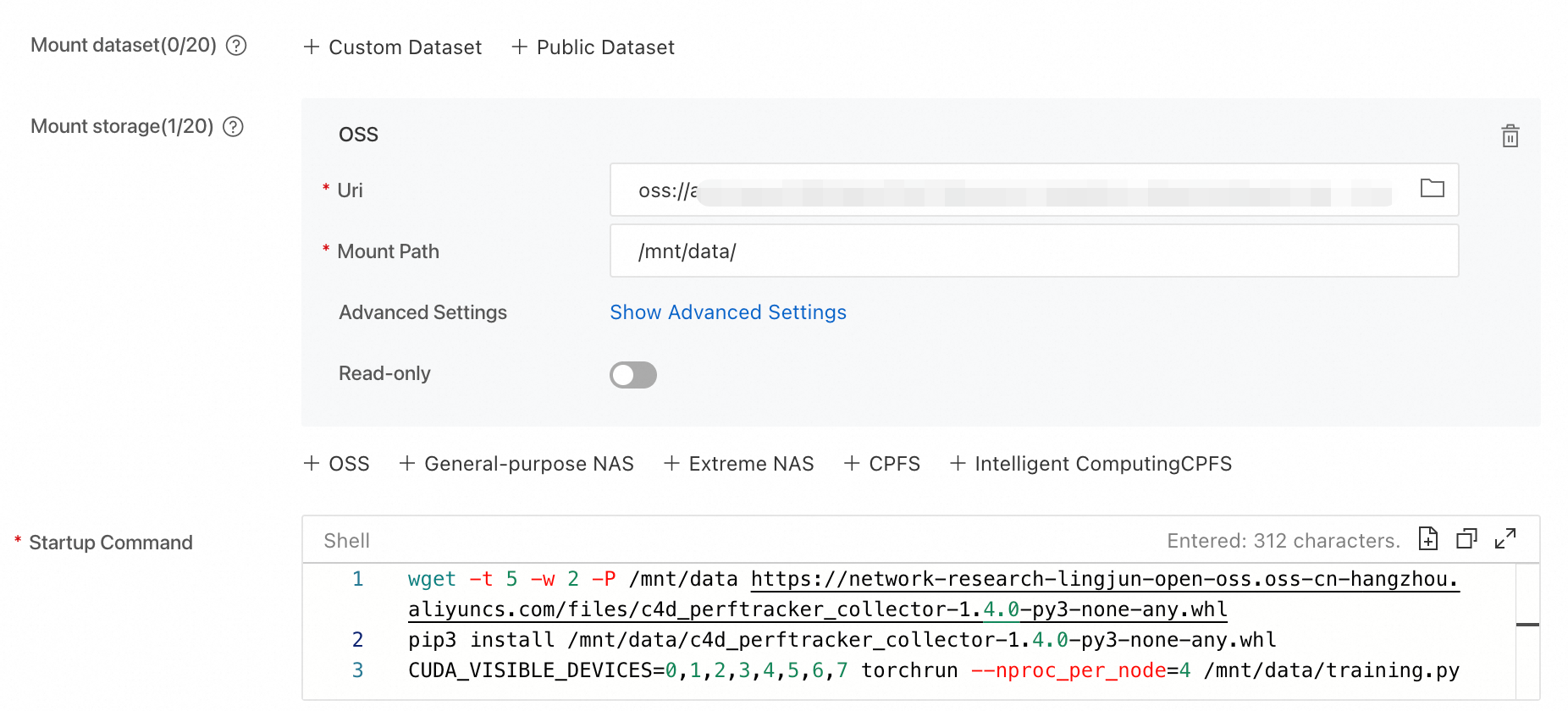
While the job is running, click the name of the target job. On the Overview tab, go to the Instance section and click Access Container in the Actions column for the master instance.

Run the following command to save the analysis results. You can use these results to diagnose the cause of any performance issues.
Method 1: Save only the analysis results. Do not save the raw trace.
c4d_perftracker --trigger-on --auto-analyze --output-dir /mnt/data/Method 2: If you have enough storage space, such as on CPFS or OSS, you can use the following command. This command saves both the analysis results and the raw trace, which allows for manual confirmation after the issue is diagnosed. Note that a worker's trace file is typically several hundred megabytes. You can delete it manually after diagnosis.
c4d_perftracker --trigger-on --auto-analyze --output-dir /mnt/data/ --save-raw-trace allThe
/mnt/data/parameter specifies the directory where the raw trace is saved. You can set this to your dataset mount directory. The raw trace is then saved to the dataset.
After the analysis results are saved, you can view the analysis report in PerfDisplay. For more information, see the next section. PerfTracker also provides a wide range of parameters to help locate the root cause of performance issues. For more information, see the appendix.
View analysis results
Generate and save the analysis results as described in the Analysis mode step. After the command runs successfully, the system generates a
<timestamp>/PerfDisplayfolder in the current directory.
Copy the PerfDisplay folder to the data source's mount directory,
/mnt/data. Then, download thePerfDisplaydirectory to your local machine. For instructions, see ossutil command-line interface 2.0. You can compress the folder before you download it.tar -cvf trace.tar PerfDisplay/ mv trace.tar /mnt/dataIn a local terminal, go to the
PerfDisplayfolder and run thesudo python3 app.pycommand (the sudo command may not be required on Linux). Then, open http://127.0.0.1:5000/ in a browser to view the task performance report on the visualization page.
PerfTracker displays performance reports for all functions that affect job performance and indicates whether performance anomalies exist. Functions are displayed by category. The web page also provides a series of options with detailed prompts and examples. The following sections describe the contents of the report.
GPU compute functions
GPU Compute:
[2025-03-04 06:04:00,046 PerfTracker] (compute_functions.py 131) INFO: {
"min/median/max GPU utilization (in [0,1])": [
0.27586059769318555,
0.28605496203987174,
0.2945494558115959
],
"workers with abnormal GPU utilization": {},
"major_kernel_executions": {
"void multi_tensor_apply_kernel<TensorListMetadata<4>, AdamFunctor<float, float, int>, float, float, float, float, float, float, adamMode_t, float>(long, int volatile*, TensorListMetadata<4>, AdamFunctor<float, float, int>, float, float, float, float, float, float, adamMode_t, float)320_1_1|512_1_1": {
"median cost per execution (ms)": 403.7,
"bottleneck ratio (in [0,1])": 0.01608086667957405
},
"sm80_xmma_gemm_f16f16_f16f32_f32_nn_n_tilesize160x128x32_stage4_warpsize2x2x1_tensor16x8x16_kernel7_16_1|128_1_1": {
"median cost per execution (ms)": 130.0,
"bottleneck ratio (in [0,1])": 0.015779752711771233
},
"ampere_fp16_s16816gemm_fp16_128x128_ldg8_f2f_stages_32x5_nt16_32_1|128_1_1": {
"median cost per execution (ms)": 132.60000000000002,
"bottleneck ratio (in [0,1])": 0.013880912782219888
},
"void (anonymous namespace)::indexing_backward_kernel<c10::Half, 4>(long const*, long const*, c10::Half const*, c10::Half*, long, long, long, long, bool)256_16_1|32_4_1": {
"median cost per execution (ms)": 1202.25,
"bottleneck ratio (in [0,1])": 0.012148757934008617
},
"ampere_fp16_s16816gemm_fp16_128x128_ldg8_f2f_stages_32x5_nt16_24_1|128_1_1": {
"median cost per execution (ms)": 105.6,
"bottleneck ratio (in [0,1])": 0.005656117080836238
}
},
"workers with potential GPU issues": [],
"detailed report": {}
}Report details:
"min/median/max GPU utilization (in [0,1])": For this job, the GPU utilization across all workers has a maximum of 29.4%, a minimum of 27.5%, and a median of 28.6%."workers with abnormal GPU utilization": This field is empty, which means no workers have GPU utilization values that are significant outliers. If this field were not empty, it would list the outlier worker IDs and their GPU utilization."major_kernel_executions": Lists the execution details of the GPU kernels with the longest total running times. This includes the median cost per execution and the bottleneck ratio, which is the percentage of the total end-to-end running time."workers with potential GPU issues": Lists the IDs of workers where GPU kernel functions run slowly. If this field is empty, all workers are performing normally."detailed report": Appears when"workers with potential GPU issues"is not empty. It lists which specific worker ran which kernel function slower than normal workers and by how much.
GPU memory operation functions
GPU memory operations:
[2025-03-04 06:04:00,048 PerfTracker] (gpu_mem.py 37) INFO: {
"Memcpy DtoD (Device -> Device)": {
"avg bottleneck ratio (in [0,1])": 0.010486858246092,
"abnormal_workers": {
"job_x08j11173.cloud.sqa.na131_2_122482.json": 0.010614755325049817,
"job_x08j11173.cloud.sqa.na131_8_122483.json": 0.0105935370201344,
"job_x08j11173.cloud.sqa.na131_1_122484.json": 0.010571838319204434,
"job_x08j11173.cloud.sqa.na131_0_122485.json": 0.010551186610995748,
"job_x08j11173.cloud.sqa.na131_2_122487.json": 0.010408514784026183,
"job_x08j11173.cloud.sqa.na131_5_122489.json": 0.010394903160689894,
"job_x08j11173.cloud.sqa.na131_8_122486.json": 0.010387693451926115,
"job_x08j11173.cloud.sqa.na131_9_122488.json": 0.010372437296709398
}
}
}Report details:
"avg bottleneck ratio (in [0,1])": During the monitoring period, the average bottleneck ratio for Memcpy DtoD operations in this job was 1.048%."abnormal_workers": The Memcpy DtoD function had an abnormally long execution time on eight workers. For GPU memory operation functions, a bottleneck ratio greater than 0.01 (1%) is considered abnormal. The bottleneck ratio is the running time, excluding the time that overlaps with computation.
Collective communication
Communication:
{
"nvlink ring send": {
"ncclDevKernel_AllReduce_Sum_f16_RING_LL(ncclDevComm*, unsigned long, ncclWork*)": {
"example_of_normal_worker": {
"worker": "job_x08j11173.cloud.sqa.na131_0_66930.json",
"different from other workers": 0,
"features": {
"bottleneck ratio (in [0,1])": 0.2743985289797289,
"avg throughput (%)": 73.75921390374332,
"throughput std (%)": 11.384679144385027
}
},
"abnormal_workers": []
}
},
"nvlink ring recv": {
"ncclDevKernel_AllReduce_Sum_f16_RING_LL(ncclDevComm*, unsigned long, ncclWork*)": {
"example_of_normal_worker": {
"worker": "job_x08j11173.cloud.sqa.na131_3_66933.json",
"different from other workers": 2,
"features": {
"bottleneck ratio (in [0,1])": 0.27346865947352955,
"avg throughput (%)": 72.70337362637363,
"throughput std (%)": 12.658093406593407
}
},
"abnormal_workers": []
}
},
"pcie sendrecv send": {
"ncclDevKernel_SendRecv(ncclDevComm*, unsigned long, ncclWork*)": {
"example_of_normal_worker": {
"worker": "job_x08j11173.cloud.sqa.na131_0_66930.json",
"different from other workers": 3,
"features": {
"bottleneck ratio (in [0,1])": 0.07248997985478658,
"avg throughput (%)": 46.667,
"throughput std (%)": 14.636000000000001
}
},
"abnormal_workers": []
}
},
"pcie sendrecv recv": {
"ncclDevKernel_SendRecv(ncclDevComm*, unsigned long, ncclWork*)": {
"example_of_normal_worker": {
"worker": "job_x08j11173.cloud.sqa.na131_7_66936.json",
"different from other workers": 1,
"features": {
"bottleneck ratio (in [0,1])": 0.0643436909425455,
"avg throughput (%)": 54.833333333333336,
"throughput std (%)": 14.166666666666666
}
},
"abnormal_workers": []
}
},
"pcie ring send": {
"ncclDevKernel_AllReduce_Sum_f16_RING_LL(ncclDevComm*, unsigned long, ncclWork*)": {
"example_of_normal_worker": {
"worker": "job_x08j11173.cloud.sqa.na131_0_66930.json",
"different from other workers": 0,
"features": {
"bottleneck ratio (in [0,1])": 0.2743985289797289,
"avg throughput (%)": 41.36698734177215,
"throughput std (%)": 14.653768987341774
}
},
"abnormal_workers": []
}
},
"pcie ring recv": {
"ncclDevKernel_AllReduce_Sum_f16_RING_LL(ncclDevComm*, unsigned long, ncclWork*)": {
"example_of_normal_worker": {
"worker": "job_x08j11173.cloud.sqa.na131_0_66930.json",
"different from other workers": 0,
"features": {
"bottleneck ratio (in [0,1])": 0.2743985289797289,
"avg throughput (%)": 41.5311475409836,
"throughput std (%)": 15.282721311475411
}
},
"abnormal_workers": []
}
}
}This report categorizes collective communication functions by communication type and provides a performance analysis for each type.
"example_of_normal_worker": Lists the normal performance parameters for the function's execution. This includes the bottleneck ratio (the percentage of end-to-end time, excluding time that overlaps with computation), average throughput, and throughput standard deviation."abnormal_workers": If not empty, this field lists all workers with abnormal communication function performance and their corresponding performance metrics.
CUDA runtime
CUDA Runtime:
[2025-03-04 06:04:00,047 PerfTracker] (cuda_runtimes.py 43) INFO: {
"cudaLaunchKernel": {
"avg bottleneck ratio (in [0,1])": 0.039727736621541394,
"avg execution time / monitoring duration (in [0,1])": 0.06956947111288565,
"abnormal_workers": {
"job_x08j11173.cloud.sqa.na131_5_122489.json": 0.05342638907019616,
"job_x08j11173.cloud.sqa.na131_8_122483.json": 0.05125160206973098,
"job_x08j11173.cloud.sqa.na131_2_122487.json": 0.04770049253555521,
"job_x08j11173.cloud.sqa.na131_8_122486.json": 0.04358845044879828,
"job_x08j11173.cloud.sqa.na131_0_122485.json": 0.042635952262081556,
"job_x08j11173.cloud.sqa.na131_9_122488.json": 0.0354174573296689,
"job_x08j11173.cloud.sqa.na131_1_122484.json": 0.023585242093250733,
"job_x08j11173.cloud.sqa.na131_2_122482.json": 0.02021630716304934
}
}
}Report details:
"avg bottleneck ratio (in [0,1])": The average bottleneck ratio for cudaLaunchKernel in this job during the monitoring period was 3.97%. This value excludes time that overlaps with computation."avg execution time / monitoring duration (in [0,1])": The average execution time of cudaLaunchKernel was 6.95% of the total monitoring duration. This value includes time that overlaps with computation."abnormal_workers": The cudaLaunchKernel function had an abnormally long execution time on eight workers. For CUDA runtime functions, a bottleneck ratio greater than 0.01 (1%) is considered abnormal. The bottleneck ratio is the running time, excluding the time that overlaps with computation.
Python functions
Python functions:
[2025-03-04 06:04:00,048 PerfTracker] (python_functions.py 43) INFO: {
"pretrain_gpt.py: <module>|megatron/training.py: pretrain|megatron/training.py: train|megatron/training.py: train_step|megatron/core/pipeline_parallel/schedules.py: forward_backward_pipelining_without_interleaving|megatron/core/pipeline_parallel/schedules.py: backward_step|megatron/core/pipeline_parallel/schedules.py: custom_backward|<built-in method run_backward of torch._C._EngineBase object at 0x>": {
"job_x08j11173.cloud.sqa.na131_2_122487.json": 0.16970858578301054,
"job_x08j11173.cloud.sqa.na131_5_122489.json": 0.16821543761561655,
"job_x08j11173.cloud.sqa.na131_0_122485.json": 0.16787961852913025,
"job_x08j11173.cloud.sqa.na131_8_122483.json": 0.16769273336153187,
"job_x08j11173.cloud.sqa.na131_8_122486.json": 0.14482595694389258,
"job_x08j11173.cloud.sqa.na131_9_122488.json": 0.10359829140378449,
"job_x08j11173.cloud.sqa.na131_1_122484.json": 0.06543764774209325,
"job_x08j11173.cloud.sqa.na131_2_122482.json": 0.06217541348063737
},
"pretrain_gpt.py: <module>|megatron/training.py: pretrain|megatron/training.py: train|megatron/training.py: train_step|megatron/core/pipeline_parallel/schedules.py: forward_backward_pipelining_without_interleaving|megatron/core/pipeline_parallel/schedules.py: forward_step|pretrain_gpt.py: forward_step|nn.Module: DistributedDataParallel_0|torch/nn/modules/module.py: _call_impl|megatron/core/distributed/distributed_data_parallel.py: forward|nn.Module: Float16Module_0|torch/nn/modules/module.py: _call_impl|megatron/model/module.py: forward|nn.Module: GPTModel_0|torch/nn/modules/module.py: _call_impl|megatron/model/gpt_model.py: forward|nn.Module: TransformerLanguageModel_0|torch/nn/modules/module.py: _call_impl|megatron/model/language_model.py: forward|nn.Module: ParallelTransformer_0|torch/nn/modules/module.py: _call_impl|megatron/model/transformer.py: forward": {
"job_x08j11173.cloud.sqa.na131_9_122488.json": 0.02471835416438489,
"job_x08j11173.cloud.sqa.na131_0_122485.json": 0.02022024568555683,
"job_x08j11173.cloud.sqa.na131_2_122482.json": 0.015394834126935101,
"job_x08j11173.cloud.sqa.na131_2_122487.json": 0.011625367332189284
},
"pretrain_gpt.py: <module>|megatron/training.py: pretrain|megatron/training.py: train|megatron/training.py: train_step": {
"job_x08j11173.cloud.sqa.na131_0_122485.json": 0.012272193902698852
},
"autograd::engine::evaluate_function: LinearWithGradAccumulationAndAsyncCommunicationBackward|LinearWithGradAccumulationAndAsyncCommunicationBackward|torch/autograd/function.py: apply|torch/cuda/amp/autocast_mode.py: decorate_bwd|megatron/core/tensor_parallel/layers.py: backward|<built-in method matmul of Tensor object at 0x>|aten::matmul|aten::mm": {
"job_x08j11173.cloud.sqa.na131_2_122487.json": 0.014066713574814782,
"job_x08j11173.cloud.sqa.na131_0_122485.json": 0.013168949365116213,
"job_x08j11173.cloud.sqa.na131_8_122483.json": 0.013000378454189552,
"job_x08j11173.cloud.sqa.na131_5_122489.json": 0.012500119397472594,
"job_x08j11173.cloud.sqa.na131_8_122486.json": 0.012470581043494208
},
"autograd::engine::evaluate_function: FastLayerNormFNBackward|FastLayerNormFNBackward|torch/autograd/function.py: apply|apex/contrib/layer_norm/layer_norm.py: backward|<built-in method ln_bwd of PyCapsule object at 0x>": {
"job_x08j11173.cloud.sqa.na131_0_122485.json": 0.010127612754279463
},
"pretrain_gpt.py: <module>|megatron/training.py: pretrain|megatron/training.py: train|megatron/training.py: train_step|megatron/core/pipeline_parallel/schedules.py: forward_backward_pipelining_without_interleaving": {
"job_x08j11173.cloud.sqa.na131_2_122487.json": 0.01041679269251709
},
"autograd::engine::evaluate_function: torch::autograd::AccumulateGrad": {
"job_x08j11173.cloud.sqa.na131_8_122486.json": 0.013633967050768714
}
}This report lists all Python functions whose execution time accounts for more than 1% of the total time, excluding time that overlaps with GPU computation, communication, or other operations. The functions are grouped by name. For each function, the report lists all workers where the execution time percentage is greater than 1%, along with the corresponding percentage on those workers.
Appendix
More PerfTracker parameters
Related references
For more information about the principles of PerfTracker, see PerfTracker: Online Performance Troubleshooting for Large-scale Model Training in Production.