Use large multimodal models to label and index image datasets, then search and filter data using metadata for model training.
Overview
Multimodal data management handles image data using large multimodal models and embedding models to preprocess data through intelligent labeling and semantic indexing, generating rich metadata. Search and filter multimodal data using this metadata to quickly identify data subsets for specific scenarios, then use them for data labeling and model training. PAI datasets provide a full set of OpenAPIs for easy integration into custom platforms. The service architecture:
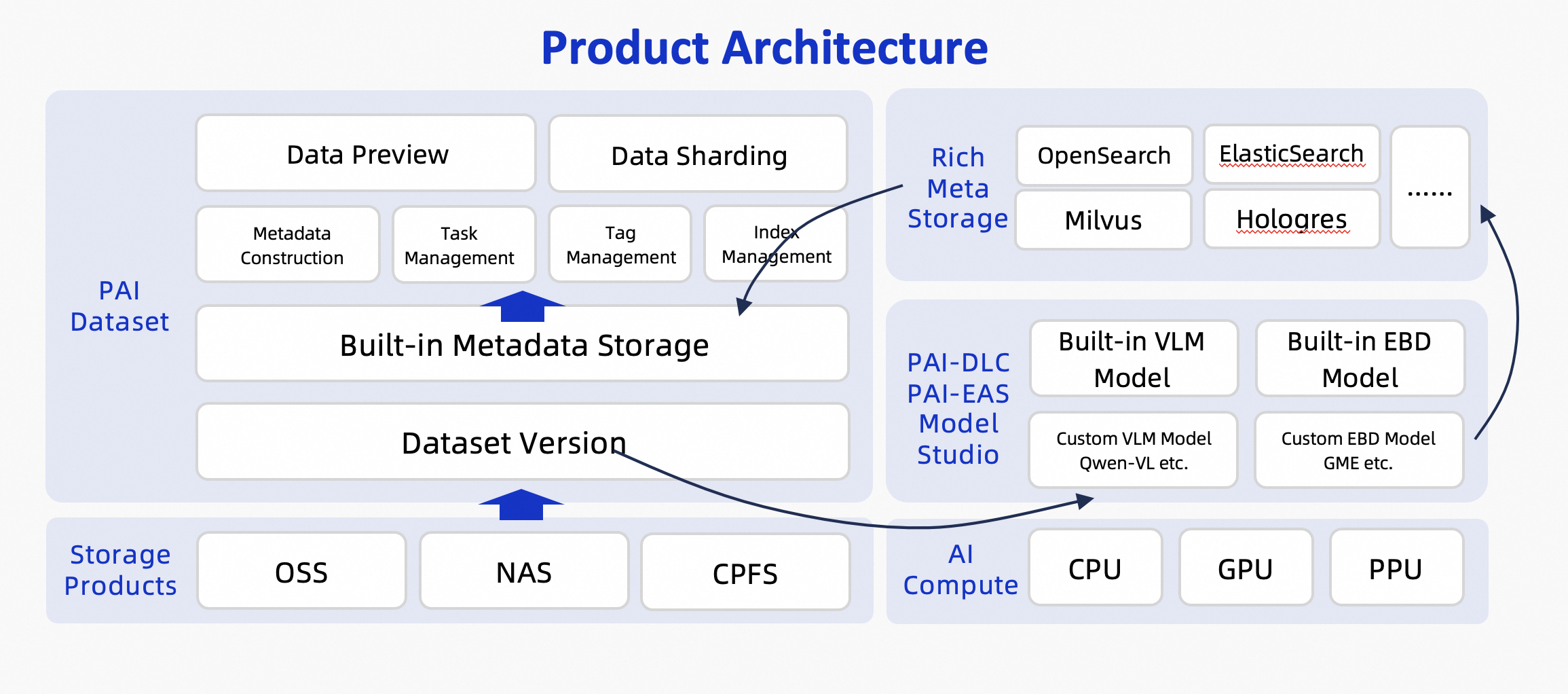
Limitations
PAI multimodal data management has the following limitations:
-
Supported regions: Hangzhou, Shanghai, Shenzhen, Ulanqab, Beijing, Guangzhou, Singapore, Germany, US (Virginia), China (Hong Kong), Tokyo, Jakarta, US (Silicon Valley), Kuala Lumpur, and Seoul.
-
Storage type: Only Object Storage Service (OSS) is supported.
-
File types: Only image files are supported. Supported formats include JPG, JPEG, PNG, GIF, BMP, TIFF, and WEBP.
-
Number of files: A single dataset version supports up to 1,000,000 files. Contact your PAI PDSA for higher limits.
-
Models:
-
Labeling model: Qwen-VL-Max or Qwen-VL-Plus on Alibaba Cloud Model Studio.
-
Indexing model: Multimodal embedding models from Alibaba Cloud Model Studio (such as tongyi-embedding-vision-plus) or GME models from PAI Model Gallery. Deploy these models on PAI-EAS.
-
-
Metadata storage:
-
Metadata: Stored securely in PAI’s built-in metadatabase.
-
Embedding vectors: Stored in one of the following custom vector databases:
-
Elasticsearch (Vector Enhanced Edition, version 8.17.0 or later)
-
OpenSearch (Vector Search Edition)
-
Milvus (version 2.4 or later)
-
Hologres (version 4.0.9 or later)
-
Lindorm (Vector Engine Edition)
-
-
-
Dataset processing mode: Intelligent labeling and semantic indexing tasks support both full and incremental modes.
Workflow
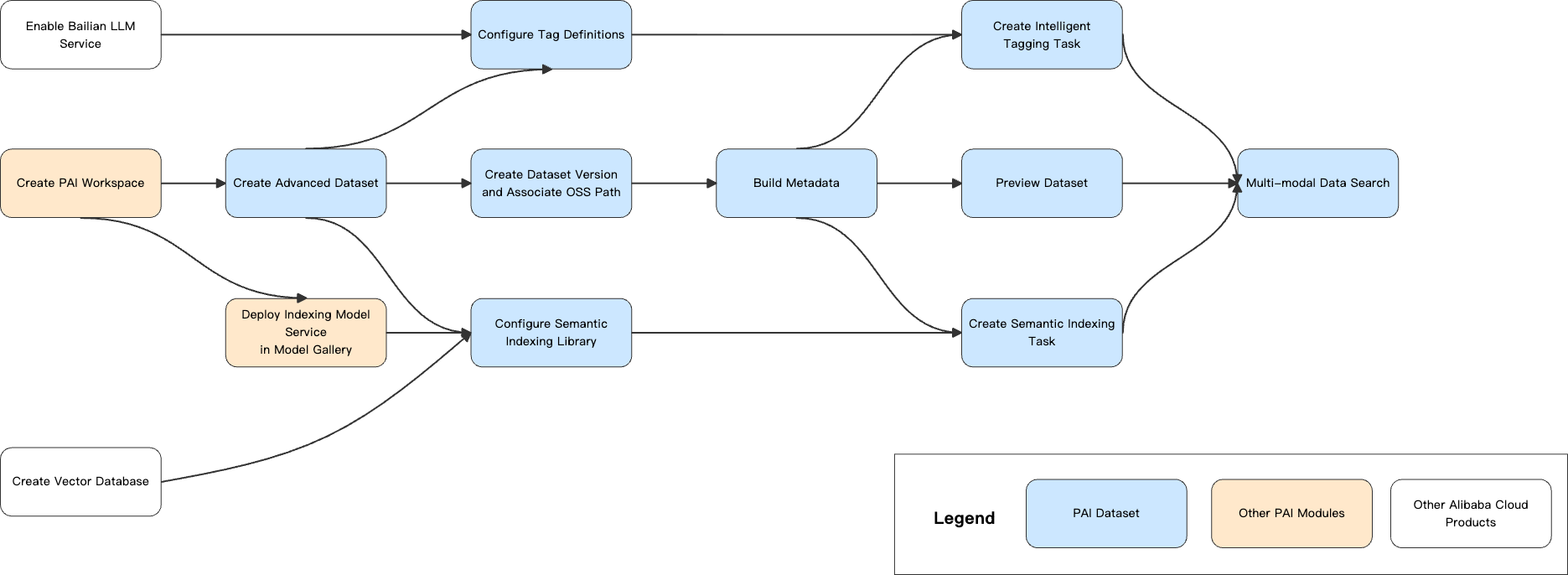
Prerequisites
Enable PAI and configure workspace
-
Use your root account to enable PAI and create a workspace. Go to the PAI console. In the upper-left corner, select your region. Then click one-click authorization to enable the service.
-
Grant permissions to your operation account. Skip this step if using your root account. For RAM users, assign the workspace administrator role. For details, see Manage Workspaces > Member Role Configuration.
Activate Model Studio and create API key
Enable Alibaba Cloud Model Studio and create an API key. For instructions, see Get an API Key.
Create vector database
Create vector database instance
Multimodal dataset management supports the following Alibaba Cloud vector databases:
-
Elasticsearch (Vector Enhanced Edition, version 8.17.0 or later)
-
OpenSearch (Vector Search Edition)
-
Milvus (version 2.4 or later)
-
Hologres (version 4.0.9 or later)
-
Lindorm (Vector Engine Edition)
For instructions on creating vector database instances, see corresponding product documentation.
Network and whitelist configuration
-
Public network access
If your vector database instance has a public endpoint, add the IP addresses below to the public access whitelist. Multimodal data management can then access the instance over the Internet. For Elasticsearch, see Configure Public or Private Network Access Whitelist.
Region
IP list
Hangzhou
47.110.230.142, 47.98.189.92
Shanghai
47.117.86.159, 106.14.192.90
Shenzhen
47.106.88.217, 39.108.12.110
Ulanqab
8.130.24.177, 8.130.82.15
Beijing
39.107.234.20, 182.92.58.94
-
Private network access
Submit a ticket to request access.
Create vector index table (optional)
The system can automatically create an index table. Skip this step if custom index table is not needed.
In some vector databases, an index table is called a collection or index.
Index table structure definition (Follow this structure):
This topic uses Elasticsearch as an example. The following Python code shows how to create a semantic index table. For other vector databases, see their documentation.
Create dataset
-
In your PAI workspace, click AI Asset Management > Datasets > Create Dataset to open the dataset configuration page.
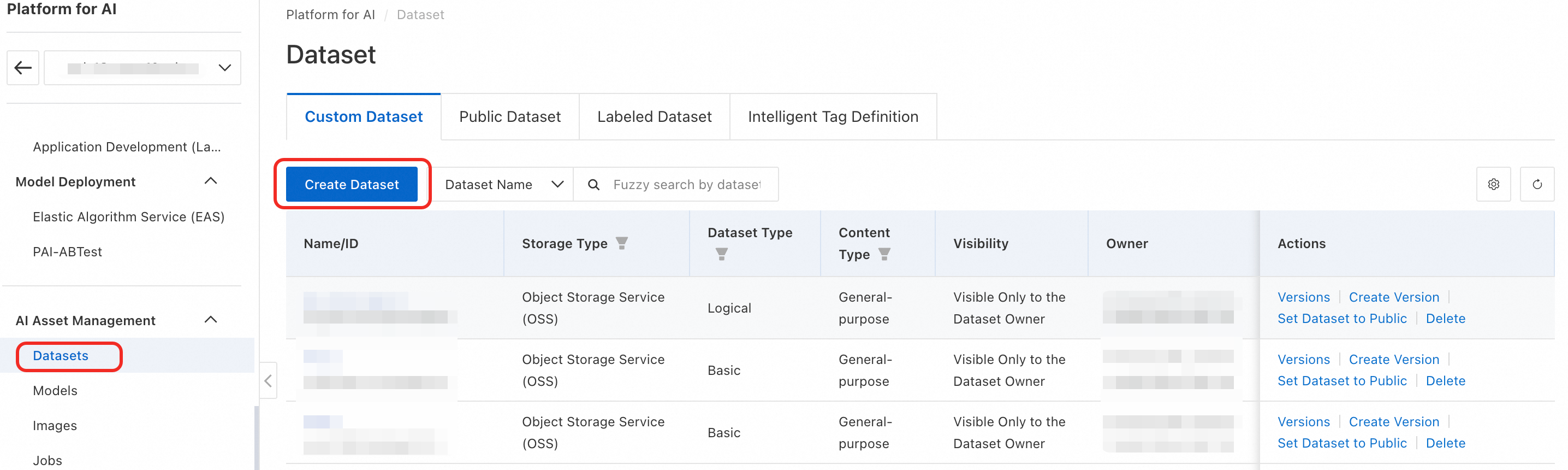
-
Configure dataset parameters. Key parameters are listed below. Use defaults for others.
-
Storage: Object Storage Service (OSS).
-
Type: Premium.
-
Content Type: Image.
-
OSS Path: Select the OSS path where your dataset is stored. If no dataset exists, download the sample dataset retrieval_demo_data, upload it to OSS, and try multimodal data management.
NoteImporting files or folders only records the path in the system. It does not copy the data.
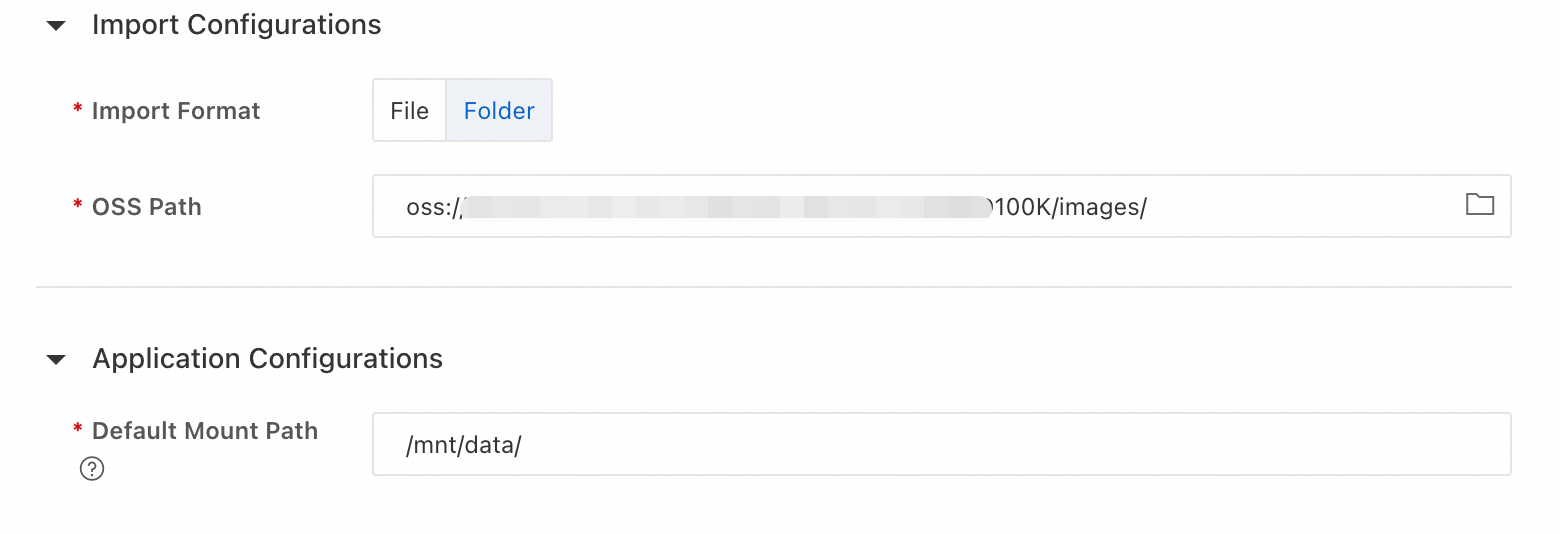
Then click OK to create the dataset.
-
Create connections
Create connection for intelligent labeling
-
In your PAI workspace, click AI Asset Management > Connection > Model Service > Create Connection to open the connection creation page.
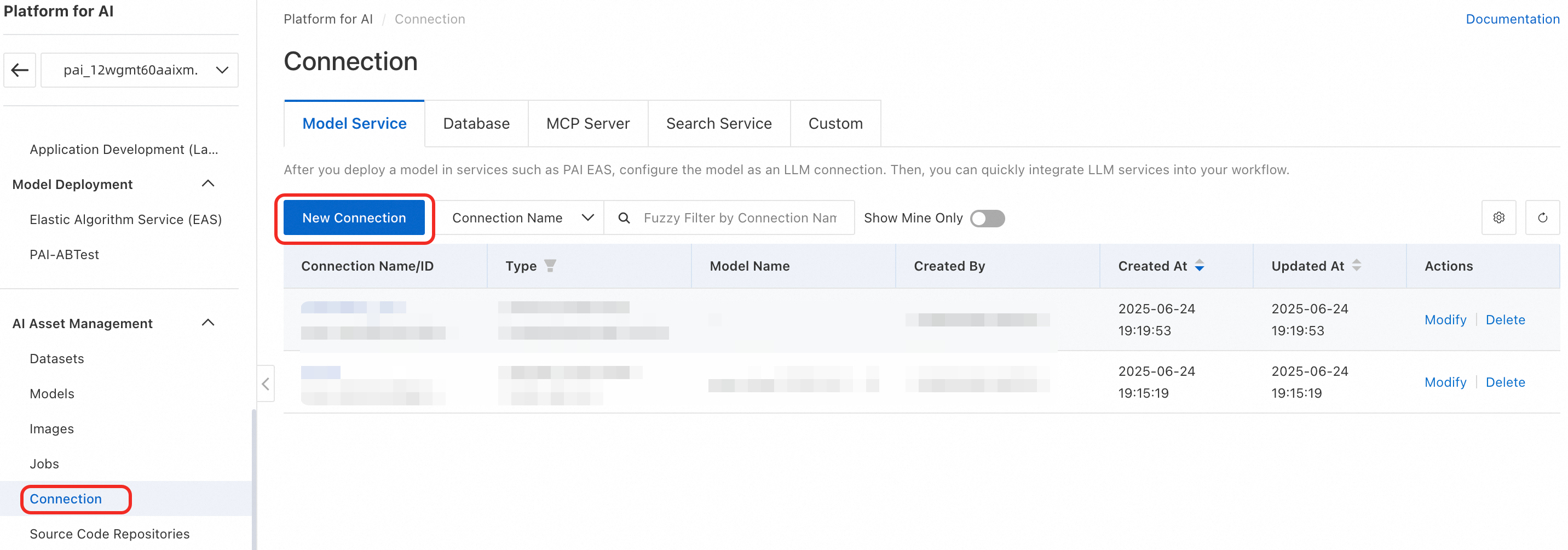
-
Select Alibaba Cloud Model Studio Service and configure the API key.
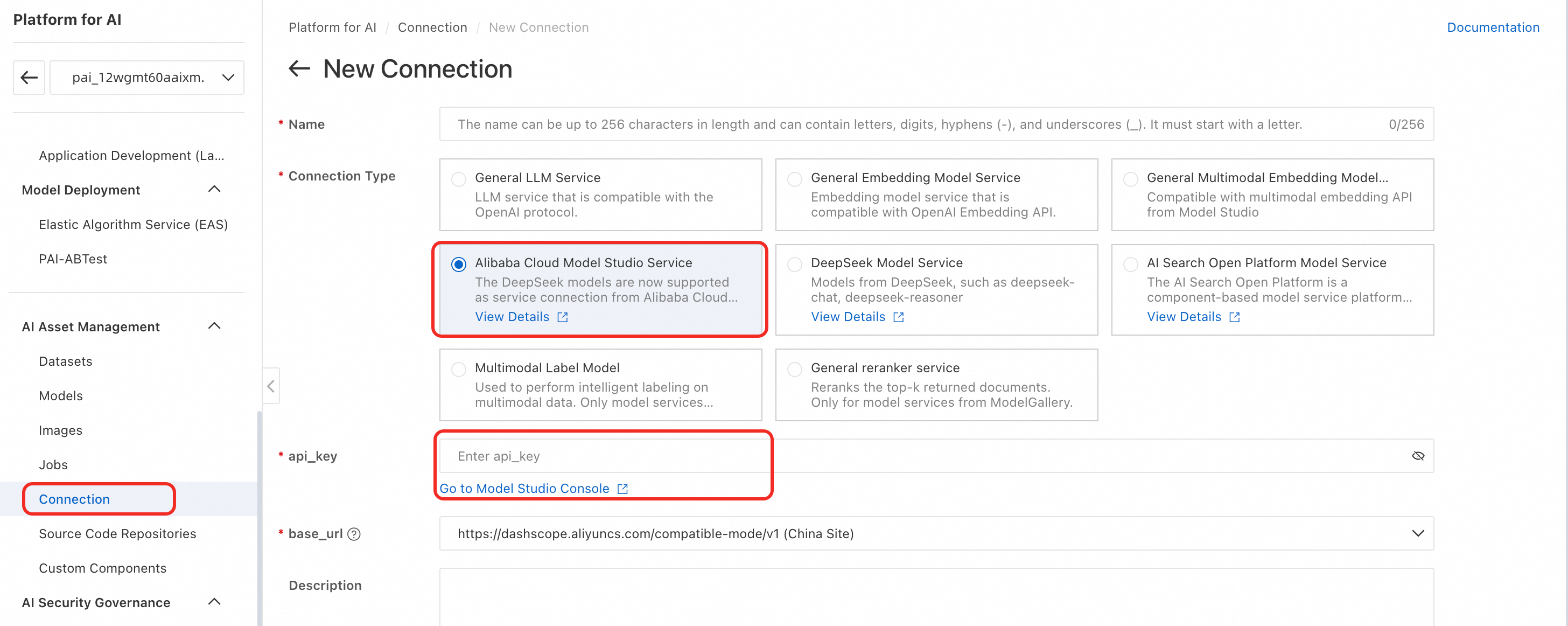
-
After successful creation, find your new connection in the list.
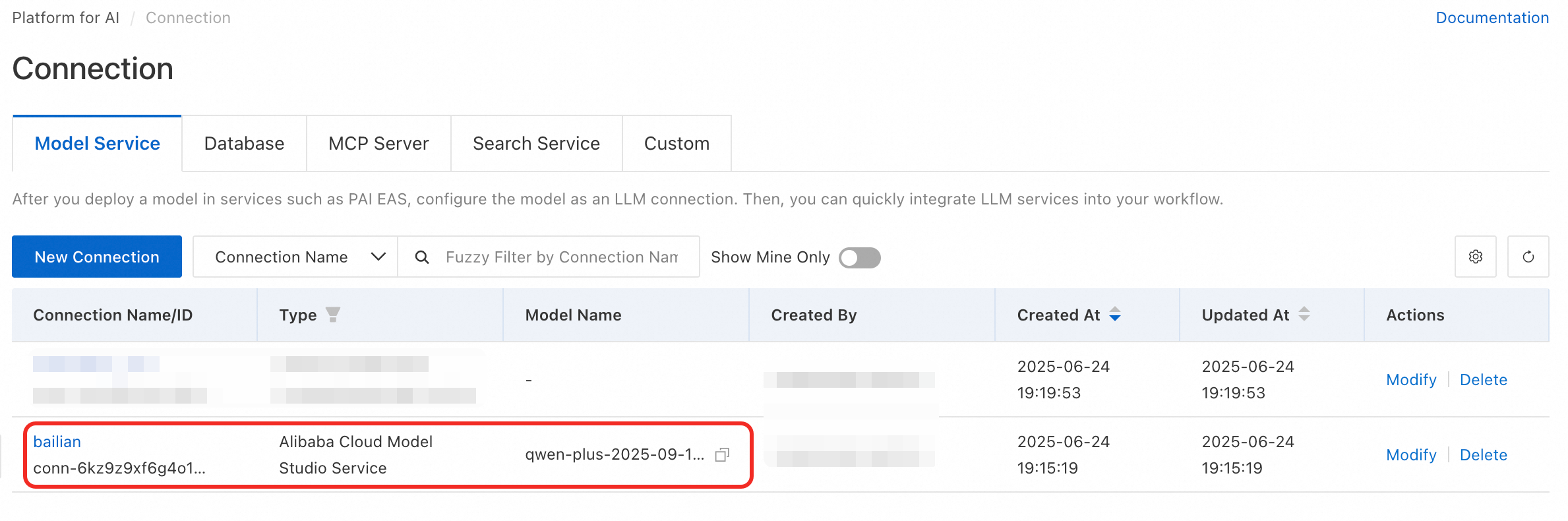
Create connection for semantic indexing
-
Skip this step if using Alibaba Cloud Model Studio’s semantic indexing service. In the left menu, click Model Gallery. Find and deploy the GME multimodal retrieval model. This creates an EAS service. Deployment takes about five minutes. When the status shows Running, deployment is complete.
ImportantStop and delete the service when no longer needed to avoid charges.
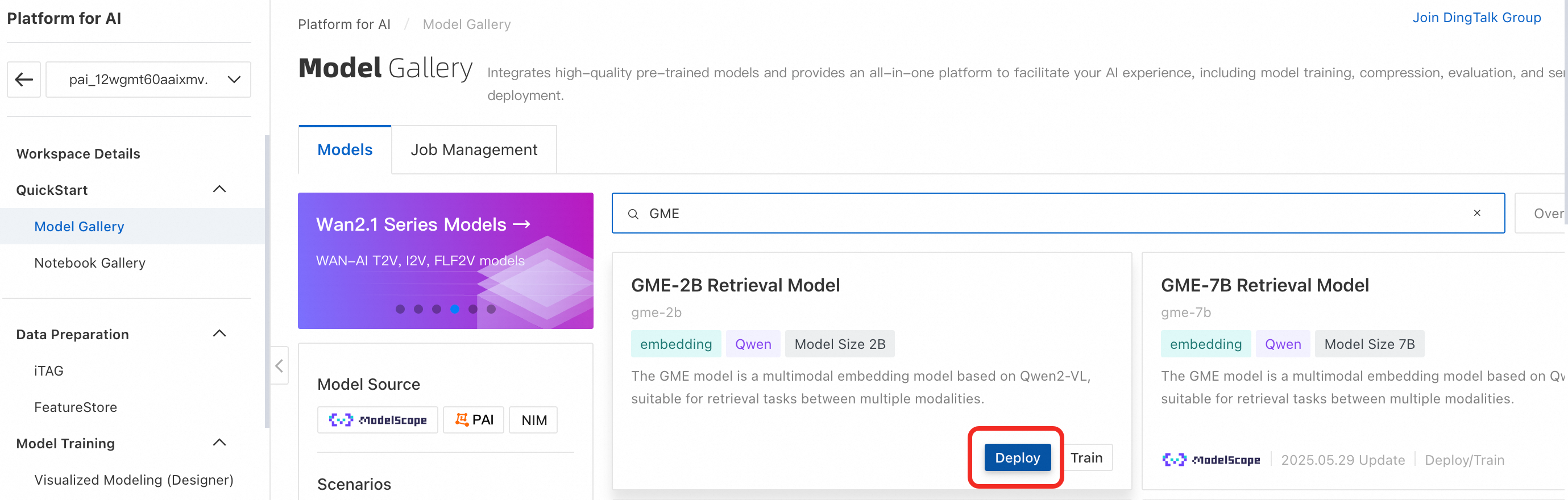
-
In your PAI workspace, click AI Asset Management > Connection > Model Service > Create Connection to open the connection creation page.
-
Configure the model connection based on whether you use Alibaba Cloud Model Studio’s semantic indexing model or your own EAS-deployed model.
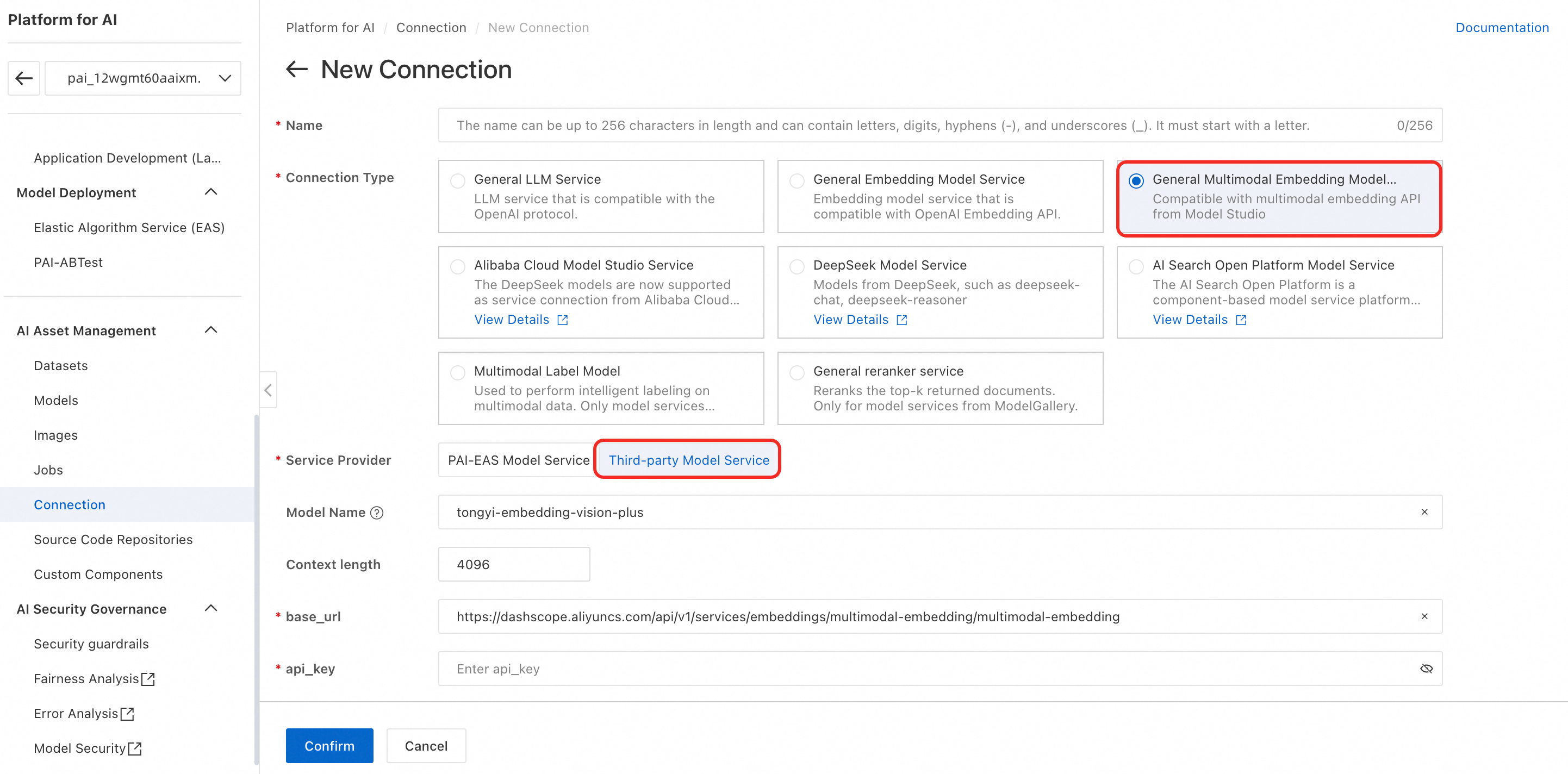
Use Alibaba Cloud Model Studio’s semantic indexing model
-
Connection Type: Select General Multimodal Embedding Model Service.
-
Service Provider: Select Third-party service model.
-
Model Name: tongyi-embedding-vision-plus.
-
base_url:
https://dashscope.aliyuncs.com/api/v1/services/embeddings/multimodal-embedding/multimodal-embedding -
api_key: Get your API key from Get an API Key and enter it here.
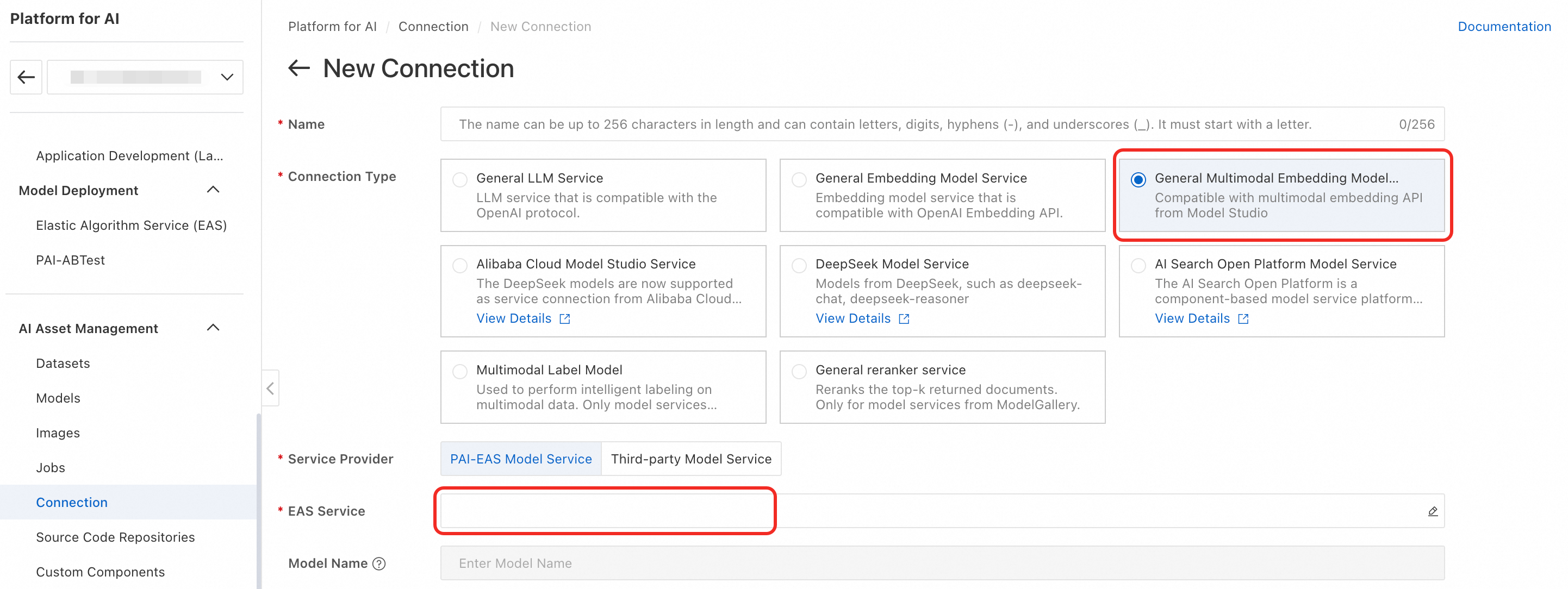
Use your own EAS-deployed semantic indexing model
-
Connection Type: Select General Multimodal Embedding Model Service.
-
Service Provider: Select PAI-EAS Model Service.
-
EAS Service: Select the GME multimodal retrieval model you just deployed. If the service is not under your current account, choose a third-party model service.
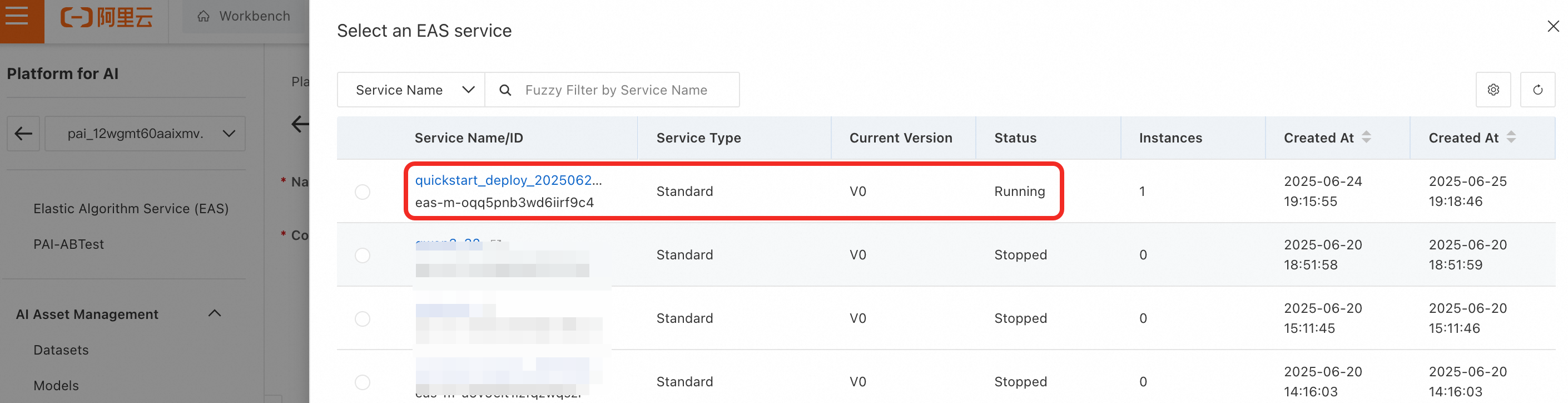
-
-
After successful creation, find your new connection in the list.
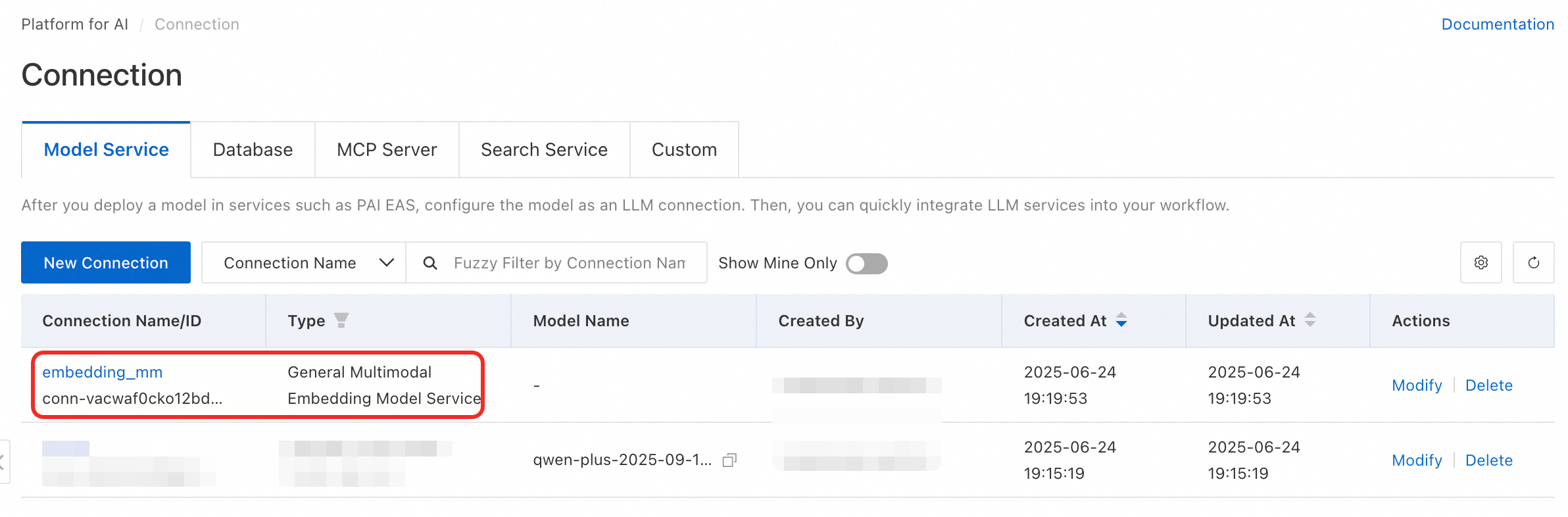
Create vector database connection
-
In the left menu, click AI Asset Management > Connection > Database > Create Connection to open the connection creation page.
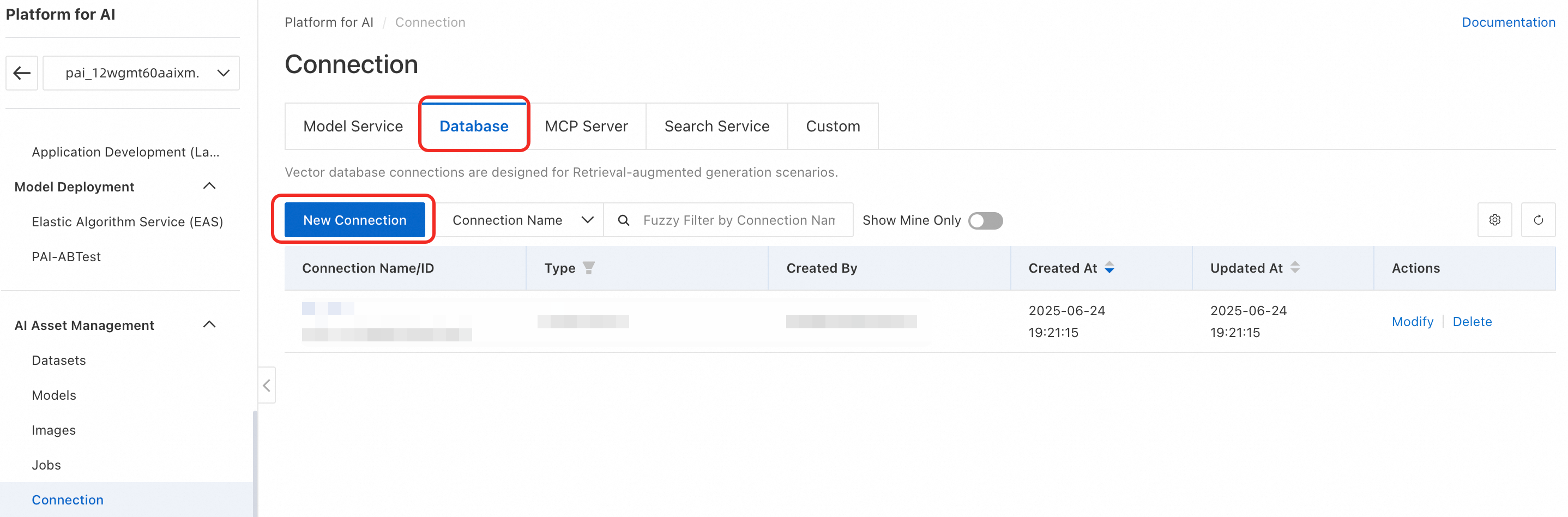
-
Multimodal search supports Milvus, Lindorm, OpenSearch, Elasticsearch, and Hologres. This example uses Elasticsearch. Select Elasticsearch and configure uri, username, and password. For details, see Create a Database Connection.
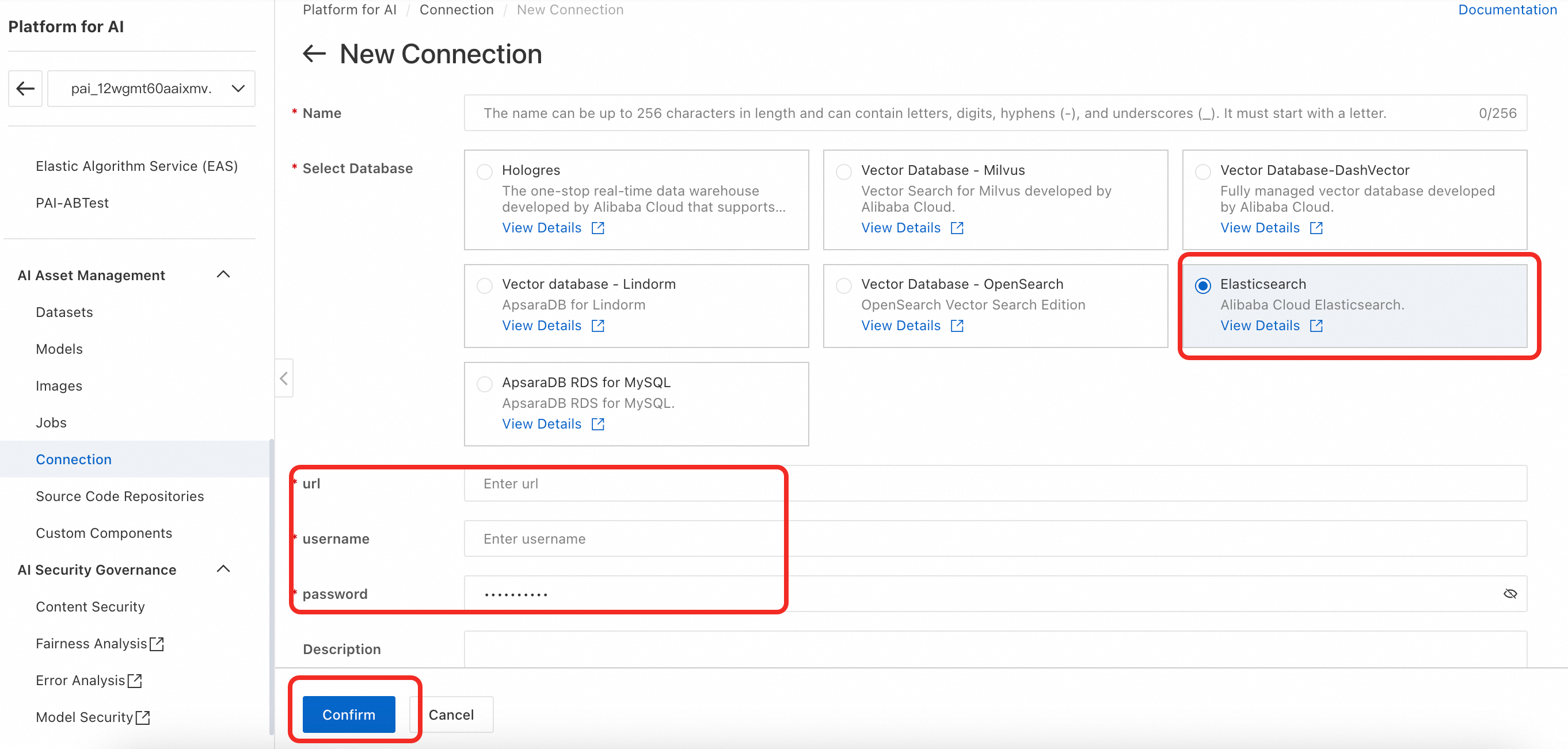
Connection format examples for each vector database:
Milvus
uri: http://xxx.milvus.aliyuncs.com:19530 database: {your_data_base} token: root:{password}OpenSearch
uri: http://xxxx.ha.aliyuncs.com username: {username} password: {password}Hologres
host: xxxx.hologres.aliyuncs.com database: {your_data_base} port: {port} access_key_id={password}Elasticsearch
uri: http://xxxx.elasticsearch.aliyuncs.com:9200 username: {username} password: {password}Lindorm
uri: xxxx.lindorm.aliyuncs.com:{port} username: {username} password: root:{password} -
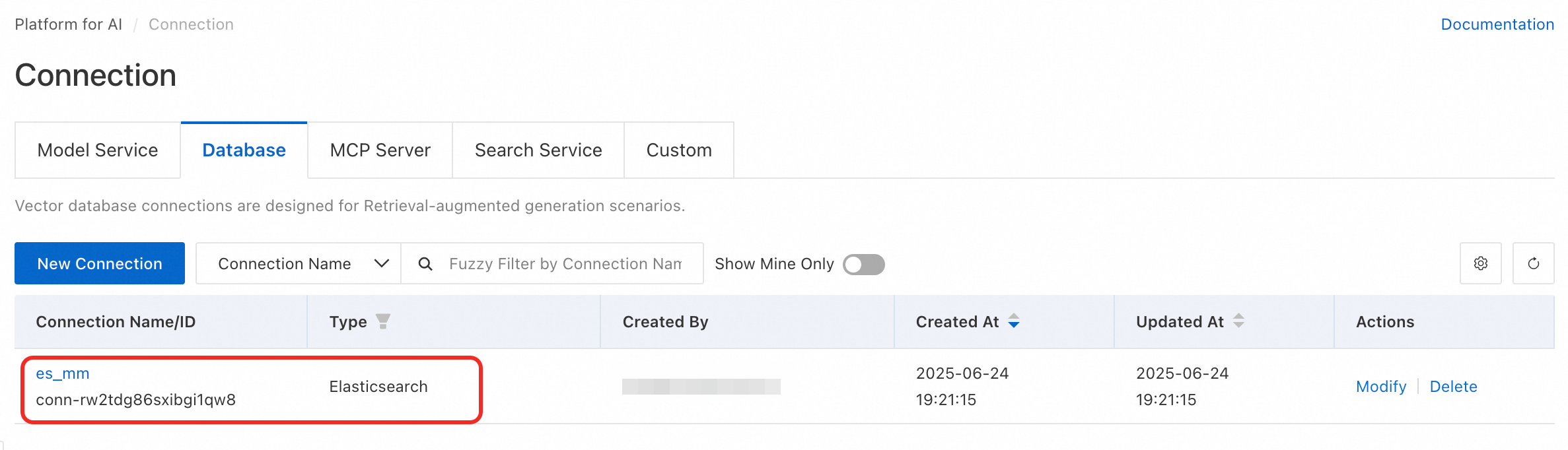
After successful creation, find your new connection in the list.
Create intelligent labeling job
Create intelligent label definition
In the left menu, click AI Asset Management > Datasets > Intelligent Tag Definition > Create Intelligent Tag Definition to open the label configuration page. Example configuration:
-
Guide Prompt: As an experienced driver with many years on highways and city roads, you know how to handle common driving scenarios.
-
Tag Definition:
Create offline intelligent labeling job
-
Click Custom Dataset. Click the dataset name to open its details page. Then click Dataset jobs.
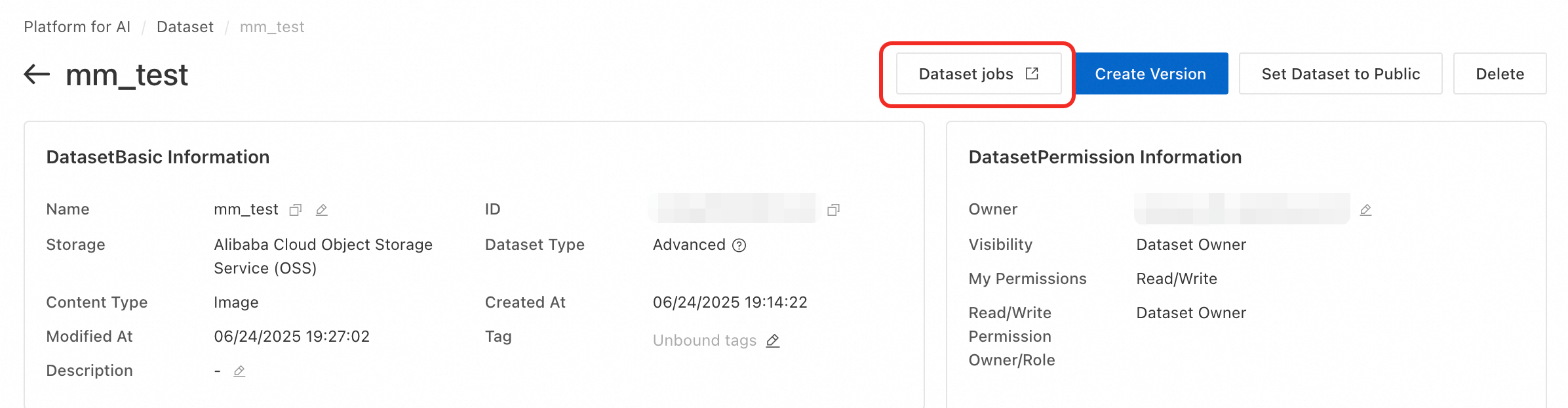
-
On the jobs page, click Create job > Smart tag and configure job parameters.
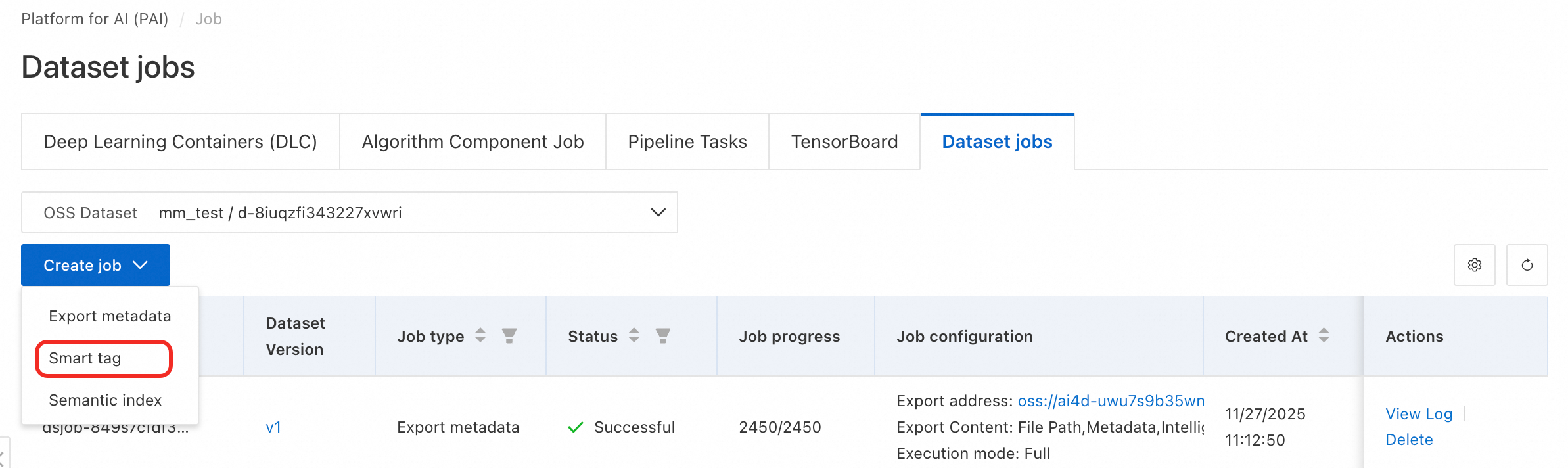
-
Dataset Version: Select the version to label, such as v1.
-
Labeling Model Connection: Select your Alibaba Cloud Model Studio model connection.
-
Smart Labeling Model: Supports Qwen-VL-Max and Qwen-VL-Plus.
-
Max Concurrency: Set based on your EAS model service specs. Suggested maximum per GPU: 5.
-
Intelligent Tag Definition: Select the definition you just created.
-
Labeling Mode: Choose Increment or Full.
-
-
After successful creation, find your labeling job in the list. To monitor or stop it, click the link on the right side of the list.
NoteThe first run builds metadata. Wait patiently—it may take time.
3.5 Create a semantic indexing job
-
Click the dataset name to open its details page. In the Index Configuration section, click Edit.
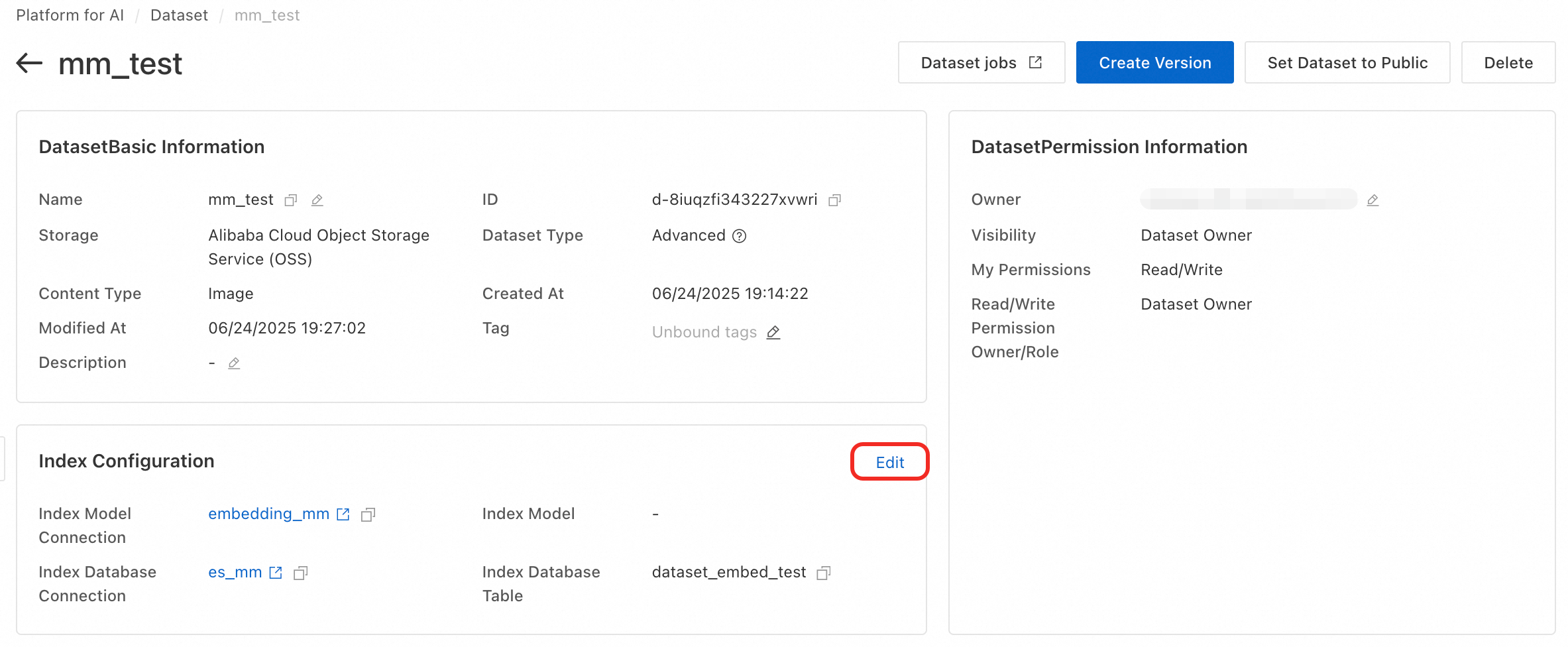
-
Configure the index library.
-
Index Model Connection: Select the index model connection created in 3.3.2.
-
Index Database Connection: Select the index database connection created in 3.3.3.
-
Index Database Table: Enter the index table name created in Create Vector Index Table (Optional): dataset_embed_test.
Click Save > Refresh Now. This starts a semantic indexing job for the selected dataset version. It updates semantic indexes for all files in that version. To view job details, click Semantic Indexing Task in the top-right corner of the dataset details page.
NoteThe first run builds metadata. Wait patiently—it may take time.
If you cancel instead of clicking Refresh Now, create the job manually:
On the dataset details page, click Dataset jobs to go to the jobs page.
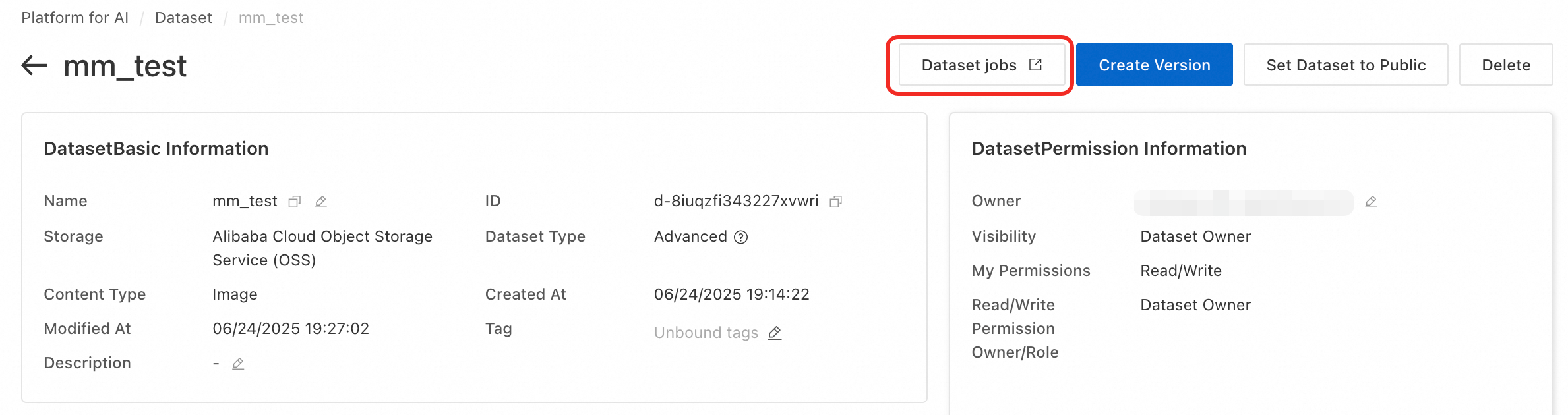
Click Create job > Semantic Indexing. Configure the dataset version. Set the maximum number of concurrent jobs based on your EAS model service specifications, with a recommended maximum of 5 per GPU. Then click OK to create the job.
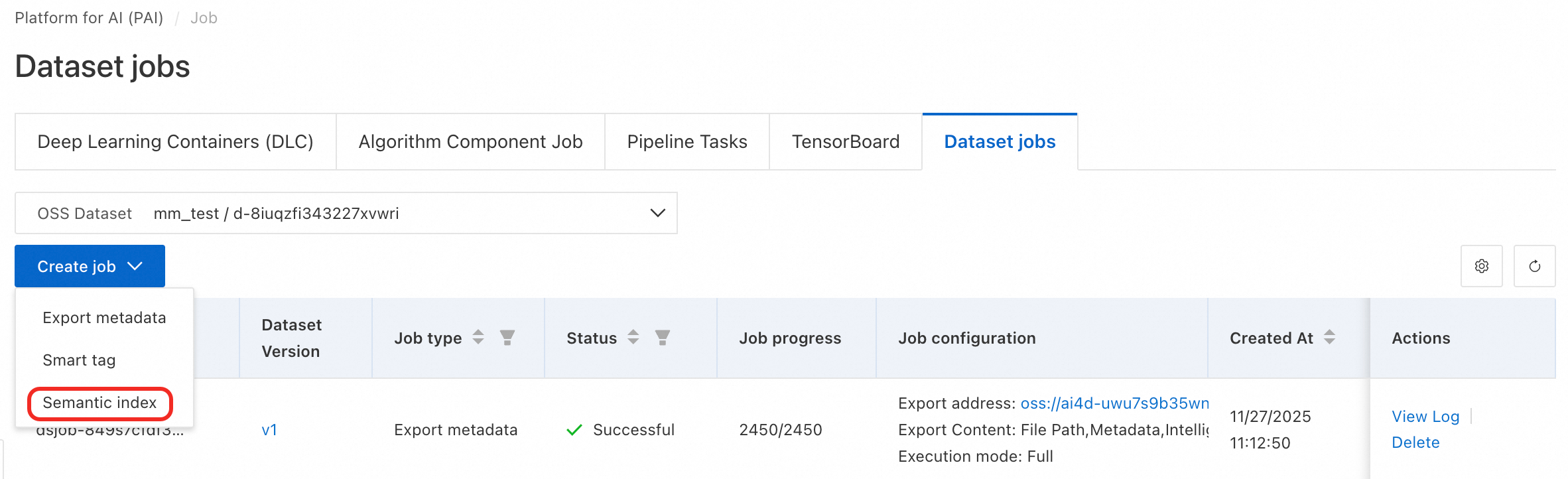
-
Preview data
-
After intelligent labeling and semantic indexing jobs finish, click View Data on the dataset details page to preview images in that version.
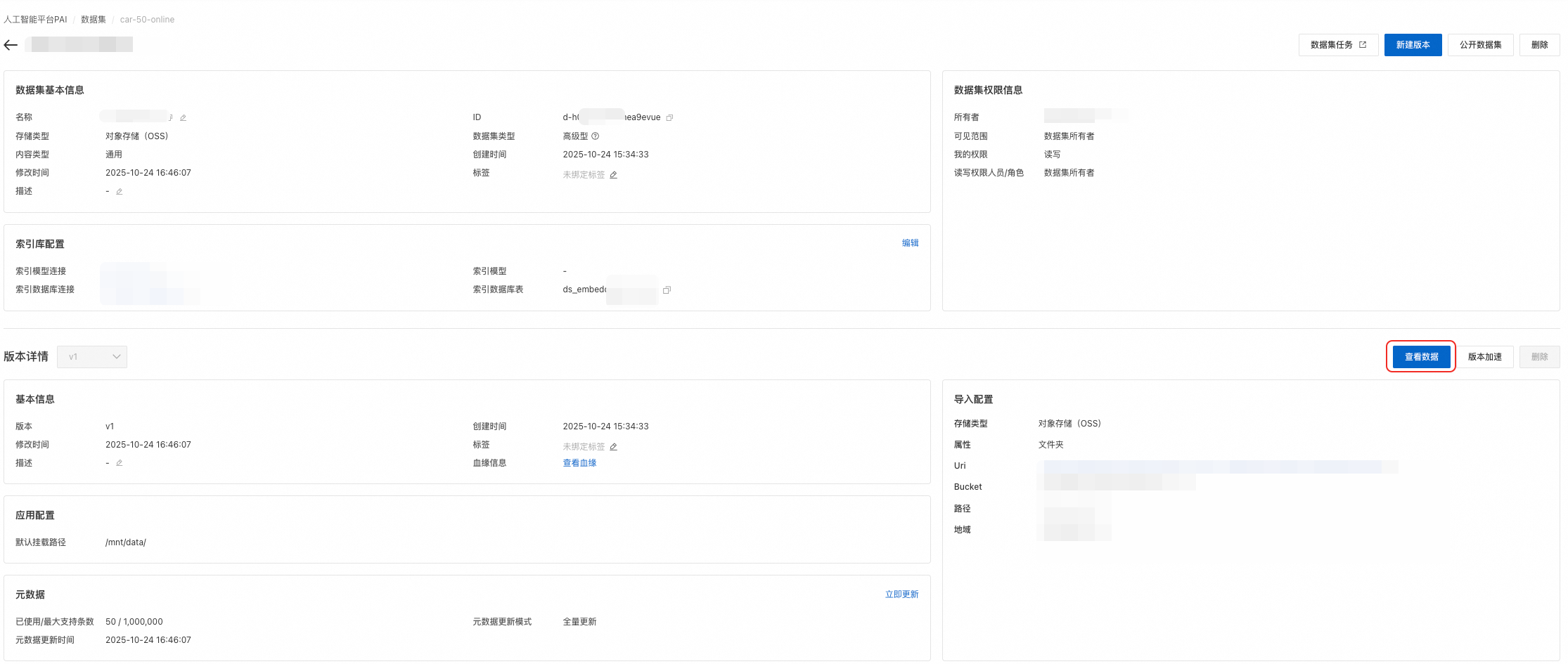
-
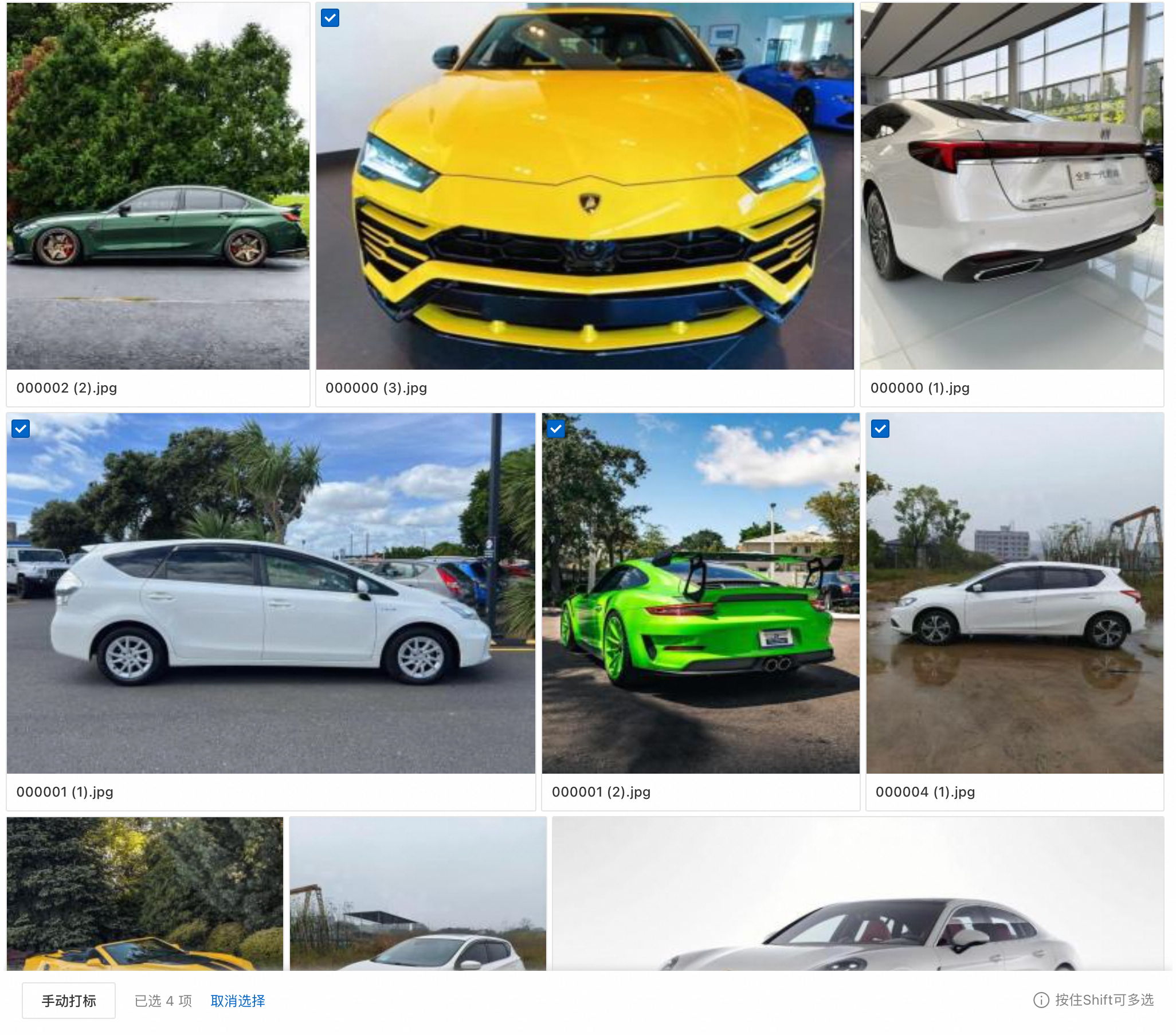
In the View Data page, preview images. Switch between Gallery View and List View.
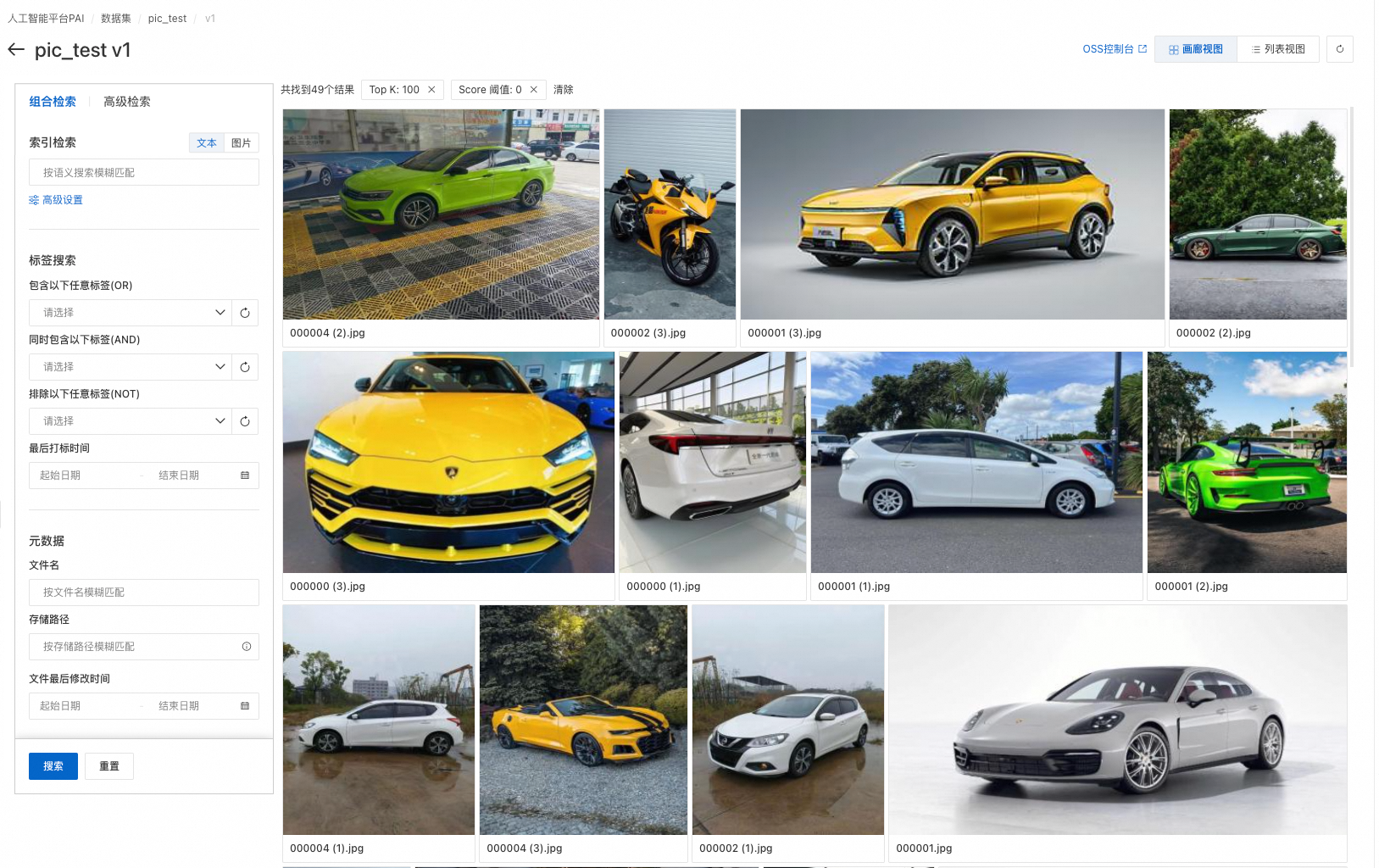
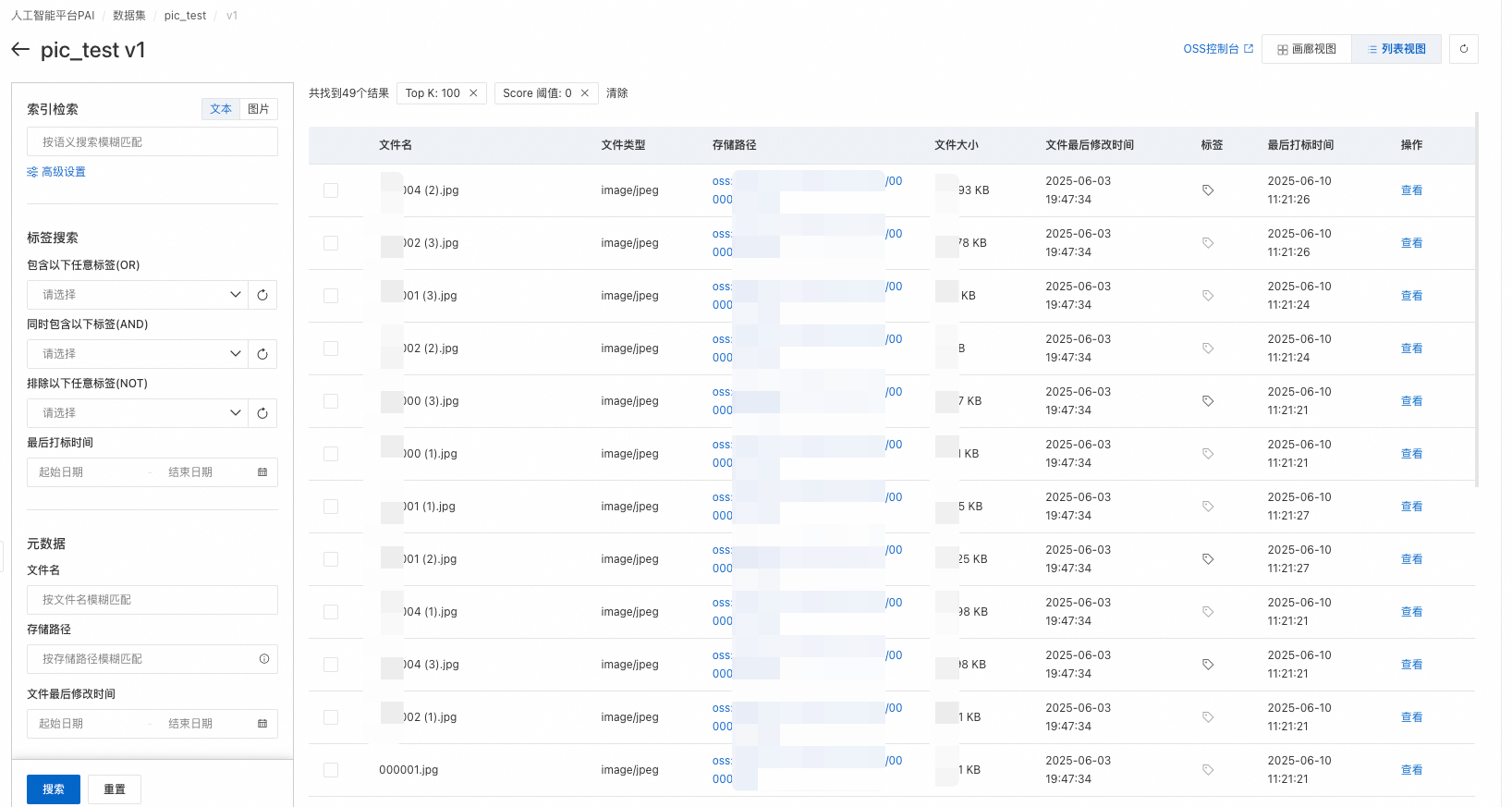
-
Click an image to view it full-size and see its labels.
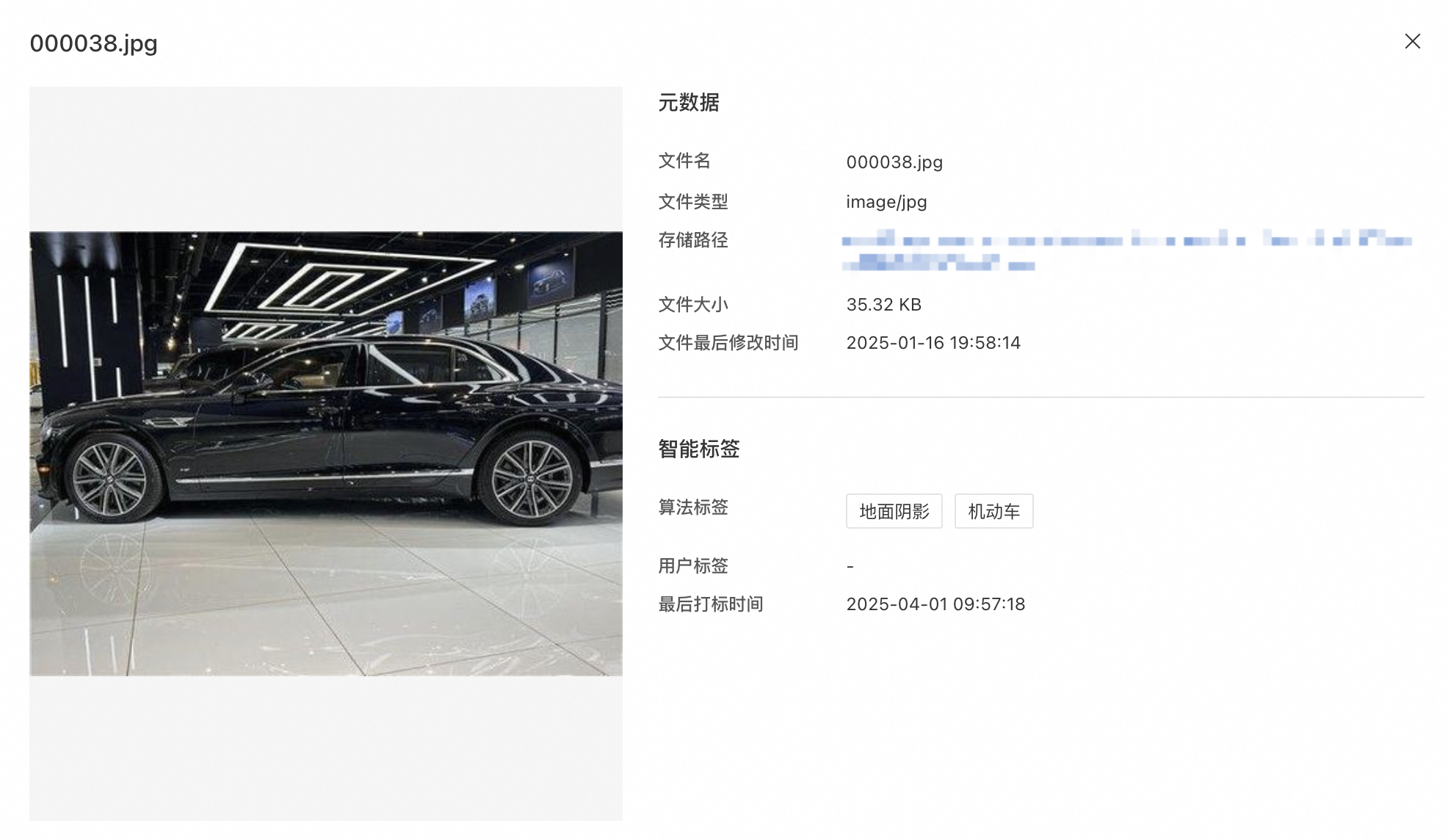
-
Click the checkbox in the top-left corner of a thumbnail to select it. Hold Shift and click checkboxes to select multiple rows.
Search data (combined search)
-
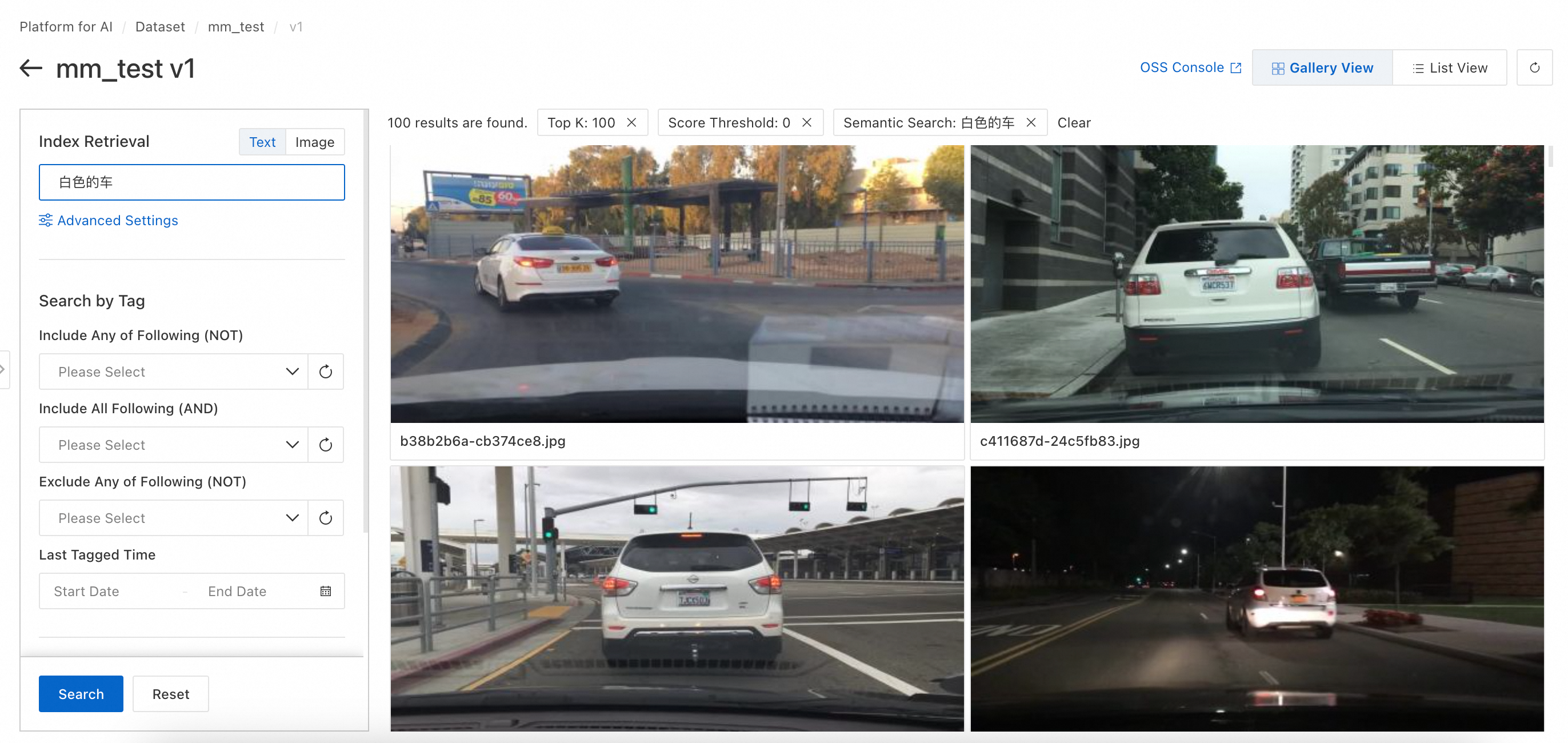
In the left toolbar of the View Data page, use Index Retrieval and Search by Tag. Press Enter or click Search.
-
Index Retrieval: Text keyword search. Matches keywords against image index vectors. In Advanced Settings, set top-k and score threshold.
-
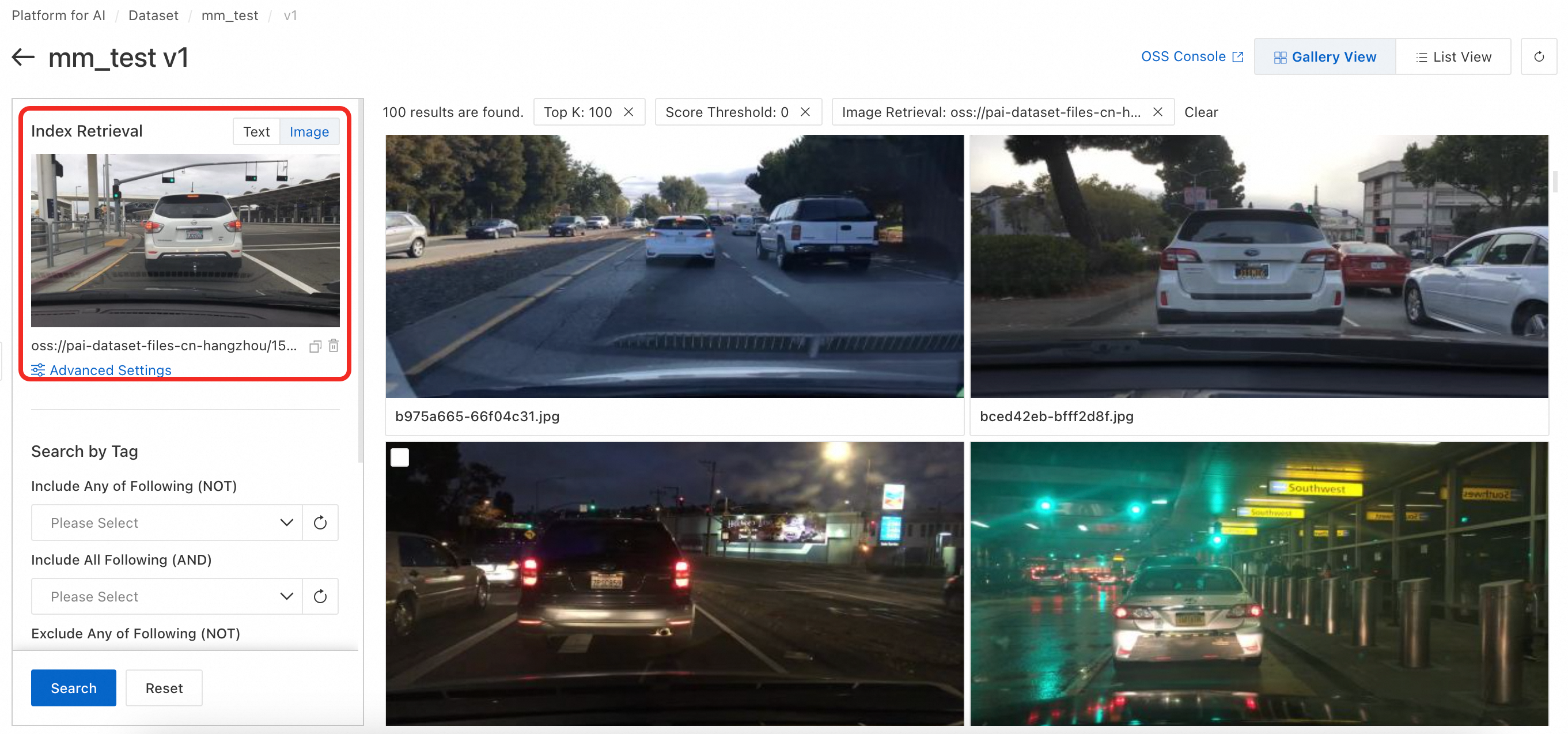
Index Retrieval: Search by image. Upload a local image or select one from OSS. Matches against image index vectors. In Advanced Settings, set top-k and score threshold.
-
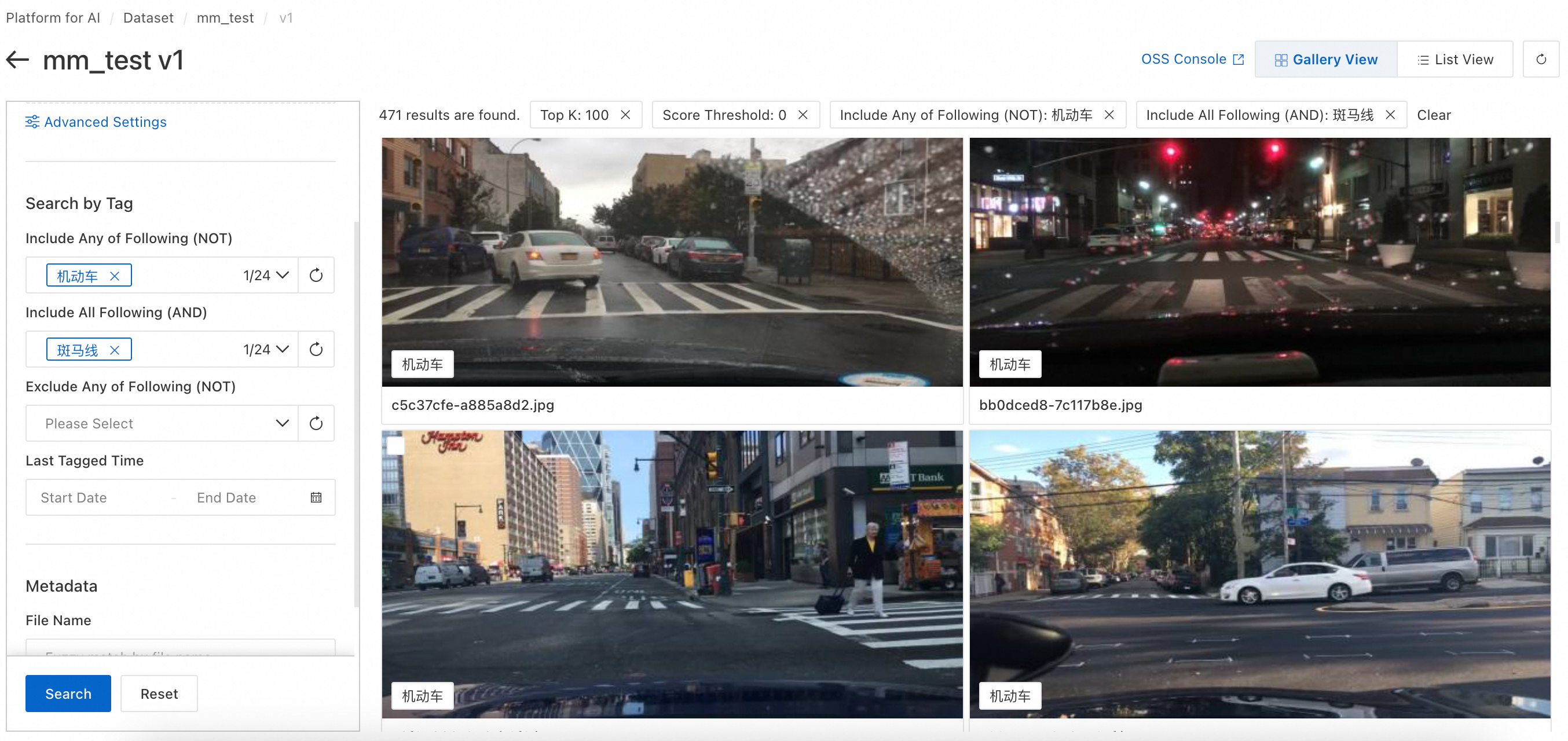
Search by Tag: Matches keywords against image labels. Use logic: Include Any of Following (NOT), Include All Following (AND), or Exclude Any of Following (NOT).
-
Metadata: Search by filename, storage path, or last modified time.
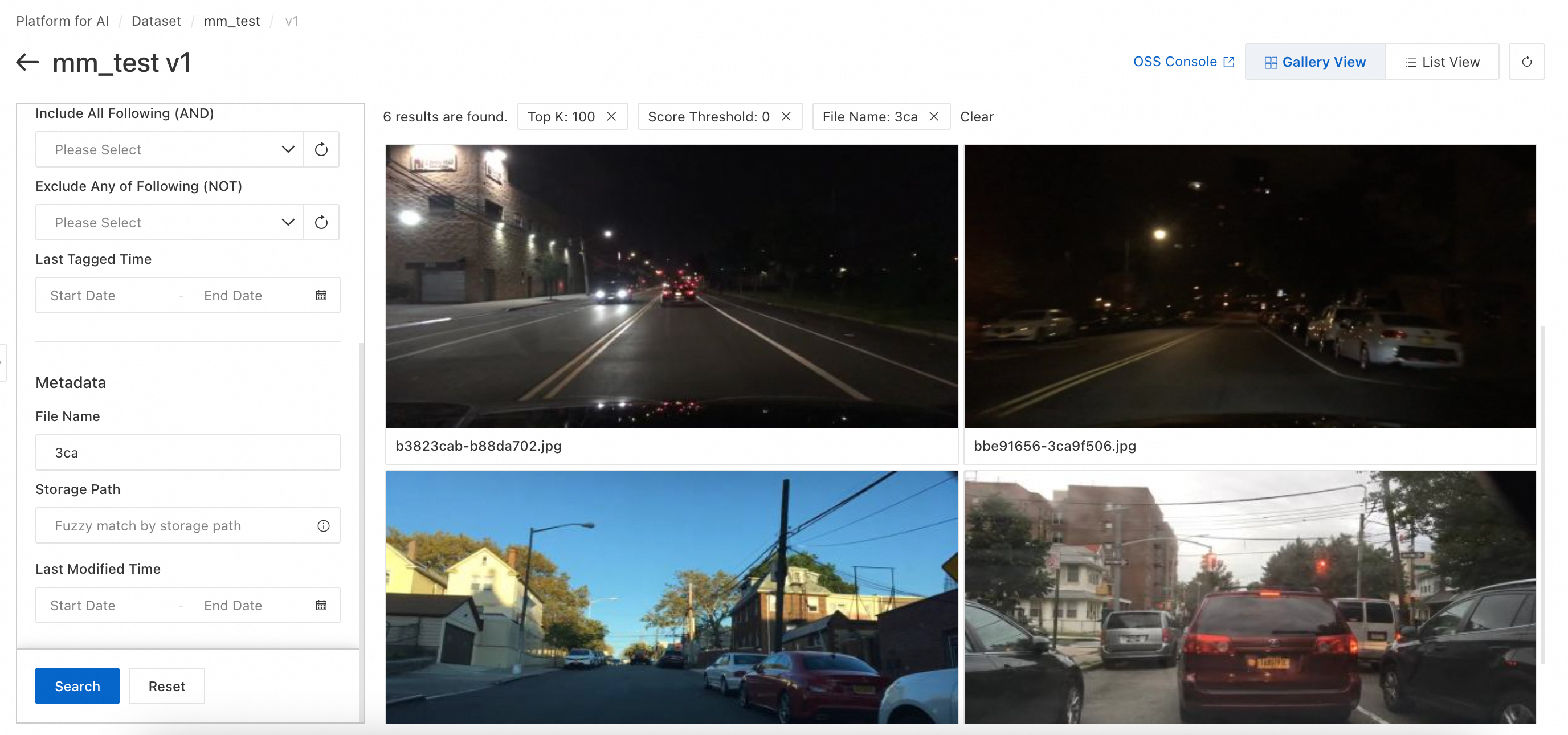
All search conditions use AND logic.
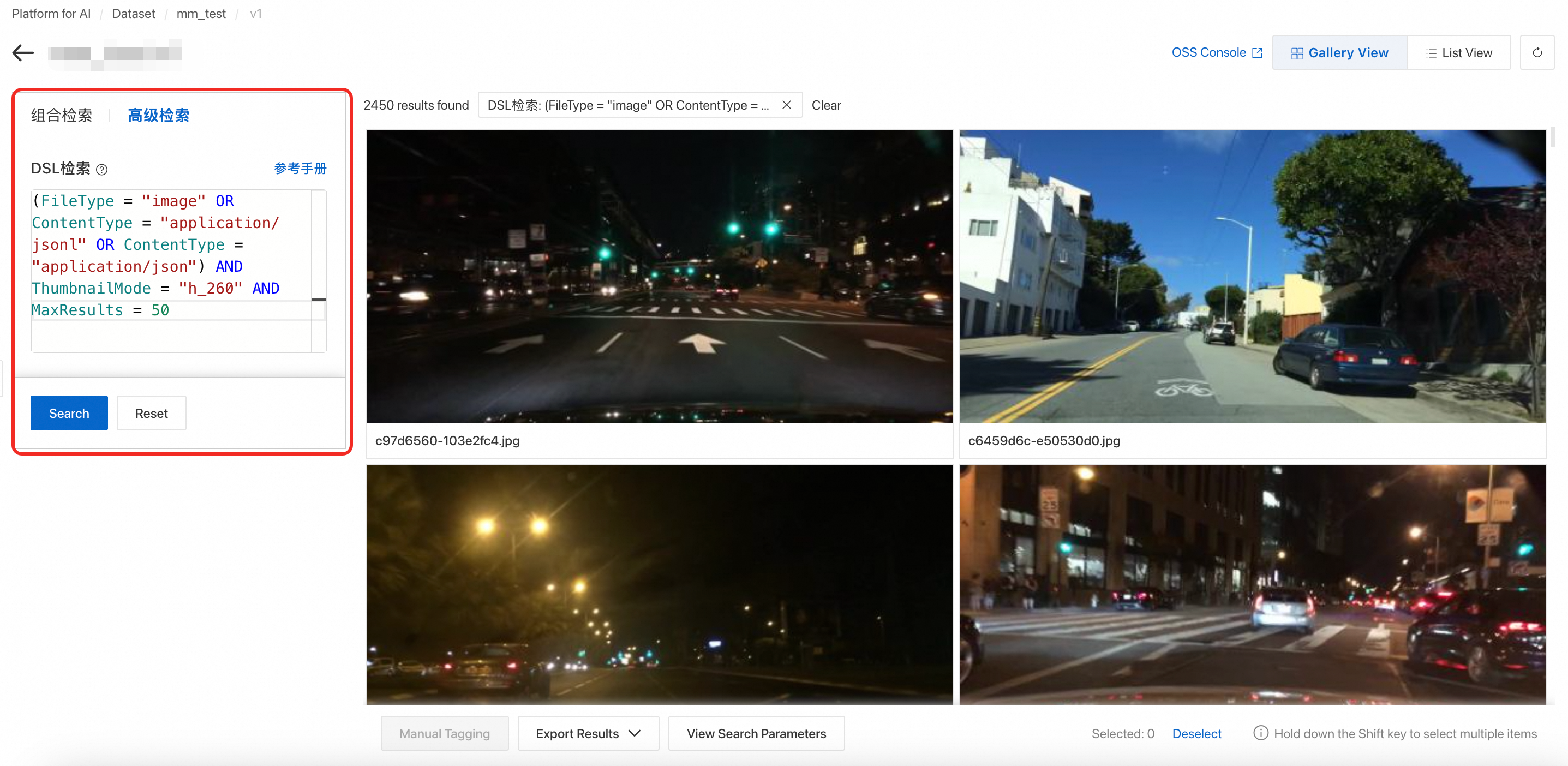
3.8 Advanced data search (DSL)
Advanced search supports DSL search. DSL is a domain-specific language for complex queries. It supports grouping, Boolean logic (AND/OR/NOT), range comparisons (>, >=, <, <=), attribute existence (HAS/NOT HAS), token matching (:), and exact matching (=). For syntax details, see List Dataset File Metadata.
3.9 Export search results
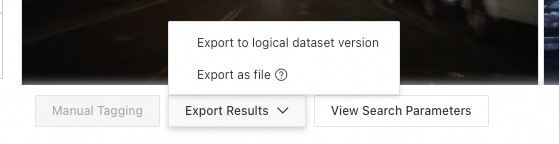
This step exports search results as a file list index for later model training or data analytics.
After searching, click Export Results at the bottom of the page. Two export options are available:
Export as file
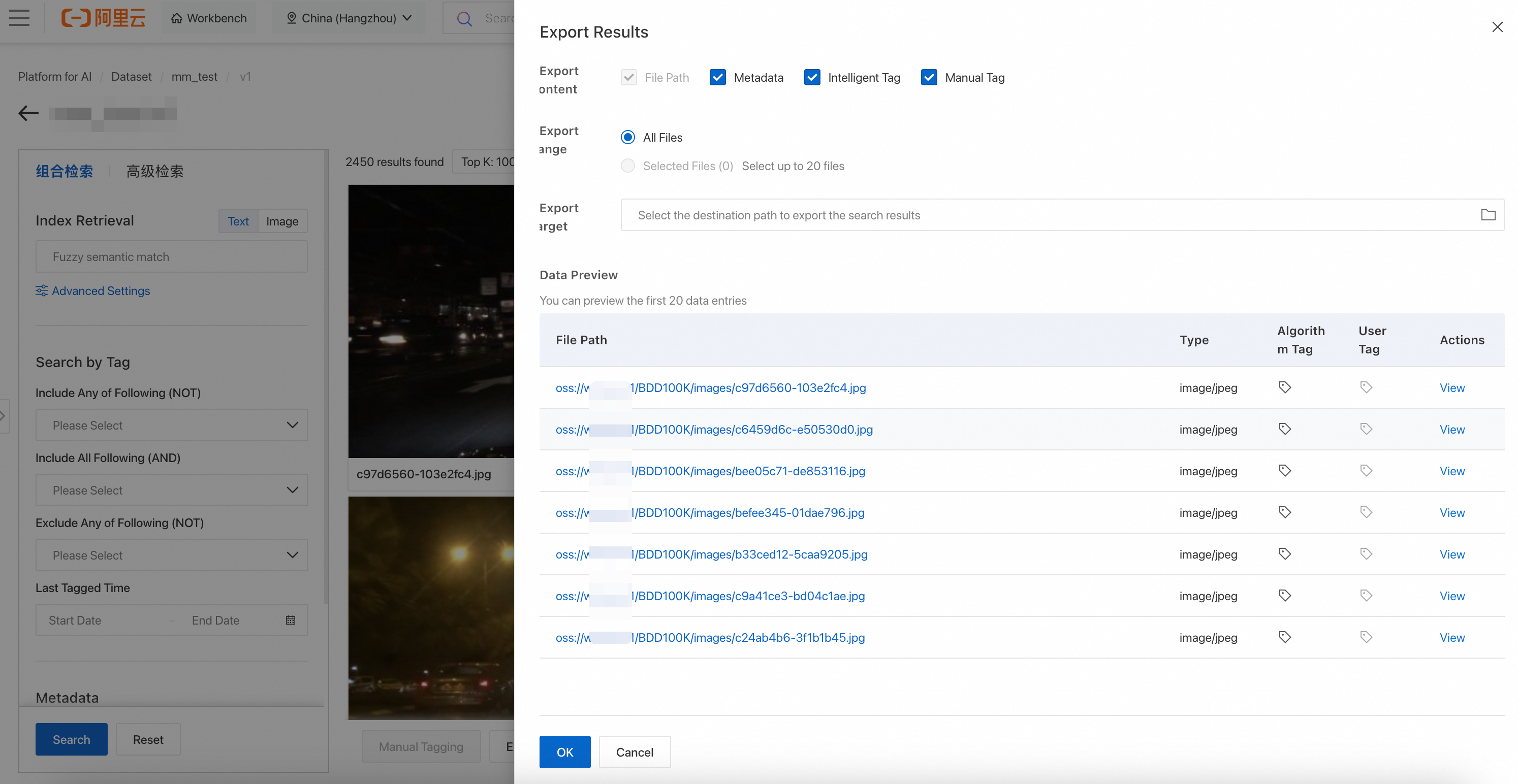
-
Click Export as file. On the config page, set export content and target OSS directory. Click OK.
-
To track progress, click AI Asset Management > Job > Dataset jobs.
-
Use the exported result. After export, mount the result file and original dataset to your training environment (such as DLC or DSW instances). Then use code to read the index file and load target files for model training or analysis.
Export to logical dataset version
Export a search result from an advanced dataset to a version of a logical dataset. Later, use the dataset SDK to access that version.
-
Click Export to logical dataset version. Select a target logical dataset and click Confirm.
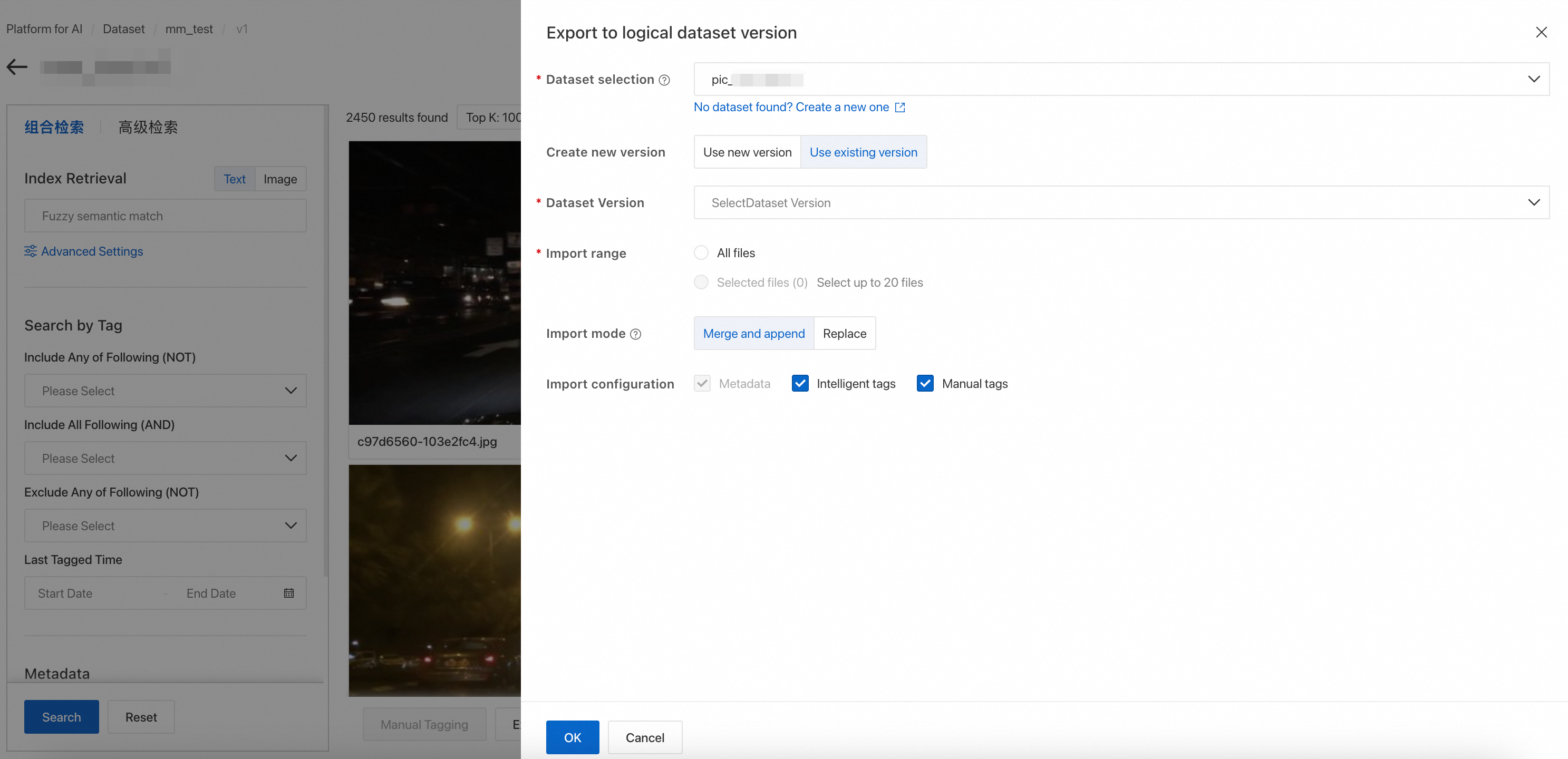
If a Boolean dataset is not available, see the following:
-
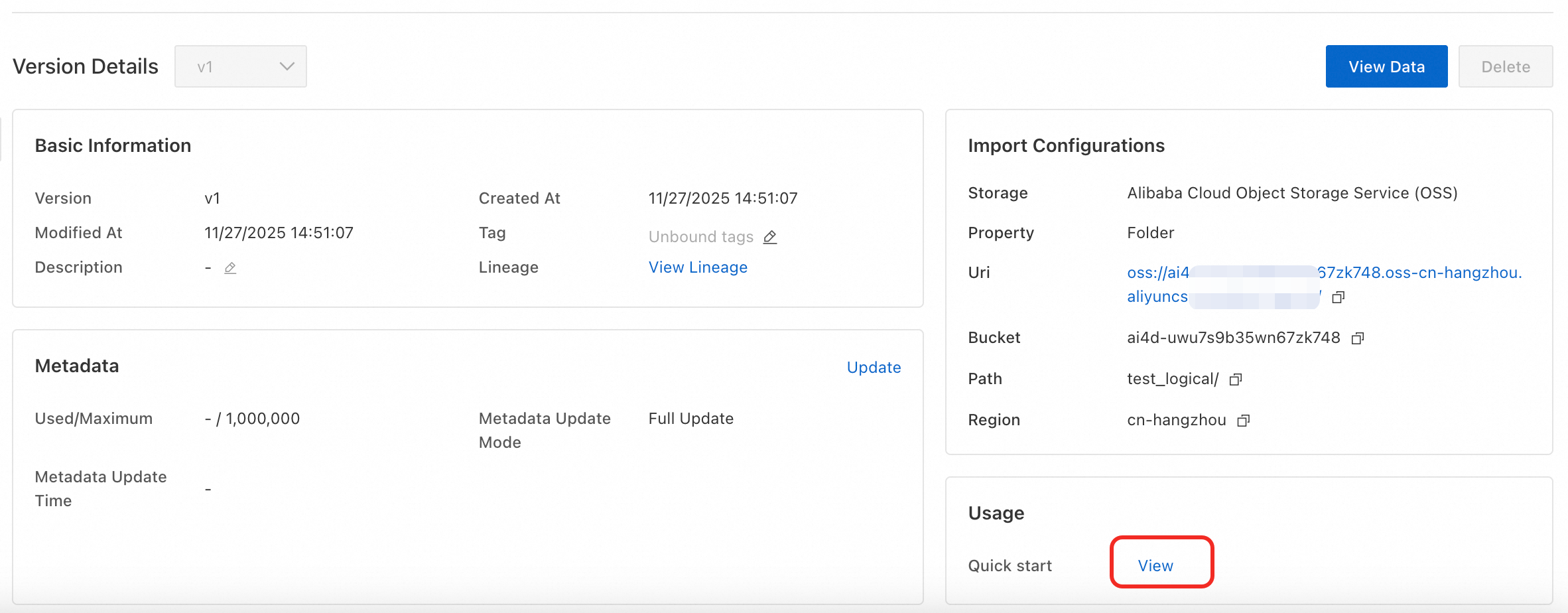
Use the logical dataset. After the import job finishes, the target logical dataset contains the exported metadata. Load and use it with the SDK. See the dataset details page for SDK usage instructions.
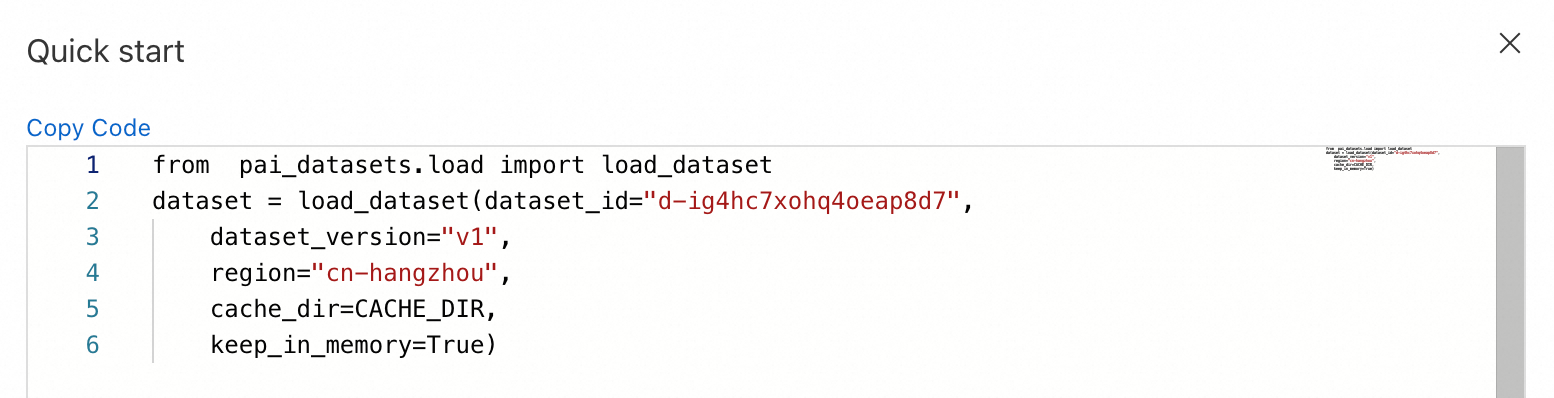
Install the SDK with:
pip install https://pai-sdk.oss-cn-shanghai.aliyuncs.com/dataset/pai_dataset_sdk-1.0.0-py3-none-any.whl
Custom semantic indexing model (optional)
Fine-tune a custom semantic retrieval model. After deploying it on EAS, create a model connection using the steps in 3.3.2. Then use it in multimodal data management.
Prepare data
This topic provides a sample dataset retrieval_demo_data. Click to download.
Data format requirements
Each data sample is one JSON line in dataset.jsonl. Include these fields:
-
image_id: Unique identifier for the image (e.g., filename or ID).
-
tags: List of text labels for the image. Must be a string array.
Example format:
{
"image_id": "c909f3df-ac4074ed",
"tags": ["silver sedan", "white SUV", "city street", "snow", "night"],
}File organization
Put all image files in an images folder. Place dataset.jsonl in the same directory as the images folder.
Directory example:
├── images
│ ├── image1.jpg
│ ├── image2.jpg
│ └── image3.jpg
└── dataset.jsonl Use the exact filename dataset.jsonl. Do not rename the images folder.
Train model
-
In Model Gallery, find retrieval-related models. Choose one based on size and compute resource needs.
VRAM for fine-tuning (bs=4)
Fine-tuning speed (4×A800, samples/sec)
Deploy VRAM
Vector dimensions
GME-2B
14 GB
16.331
5G
1536
GME-7B
35 GB
13.868
16 GB
3584
-
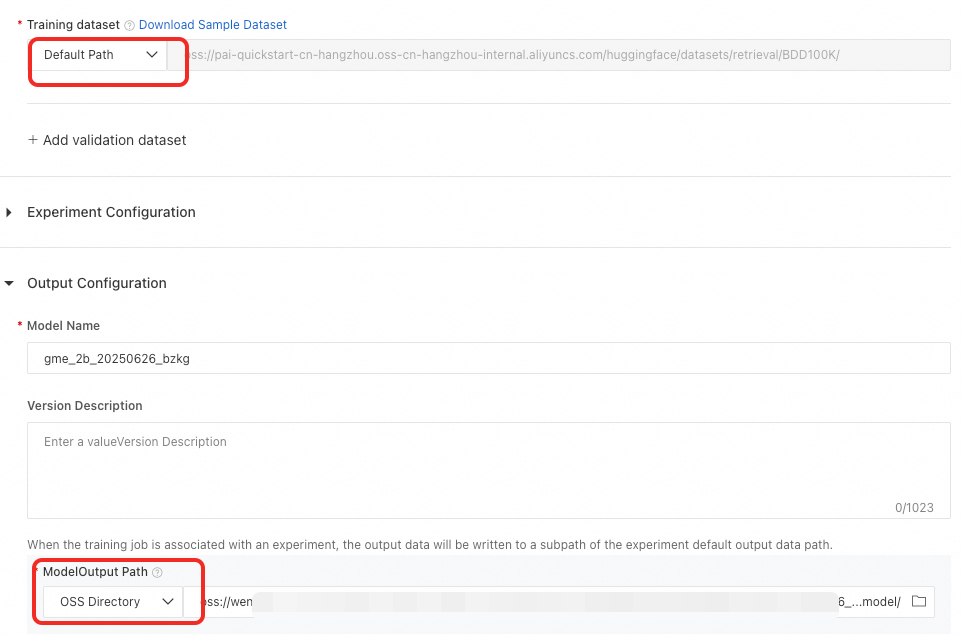
As an example, train the GME-2B model. Click Train. Enter the data path (default is the sample data path). Enter the model output path. Then start training.
Deploy model
After training, click Deploy in the training job to deploy the fine-tuned model.
Click the Deploy button in the Model Gallery tab to deploy the original GME model.

After deployment, get the EAS Endpoint and Token. 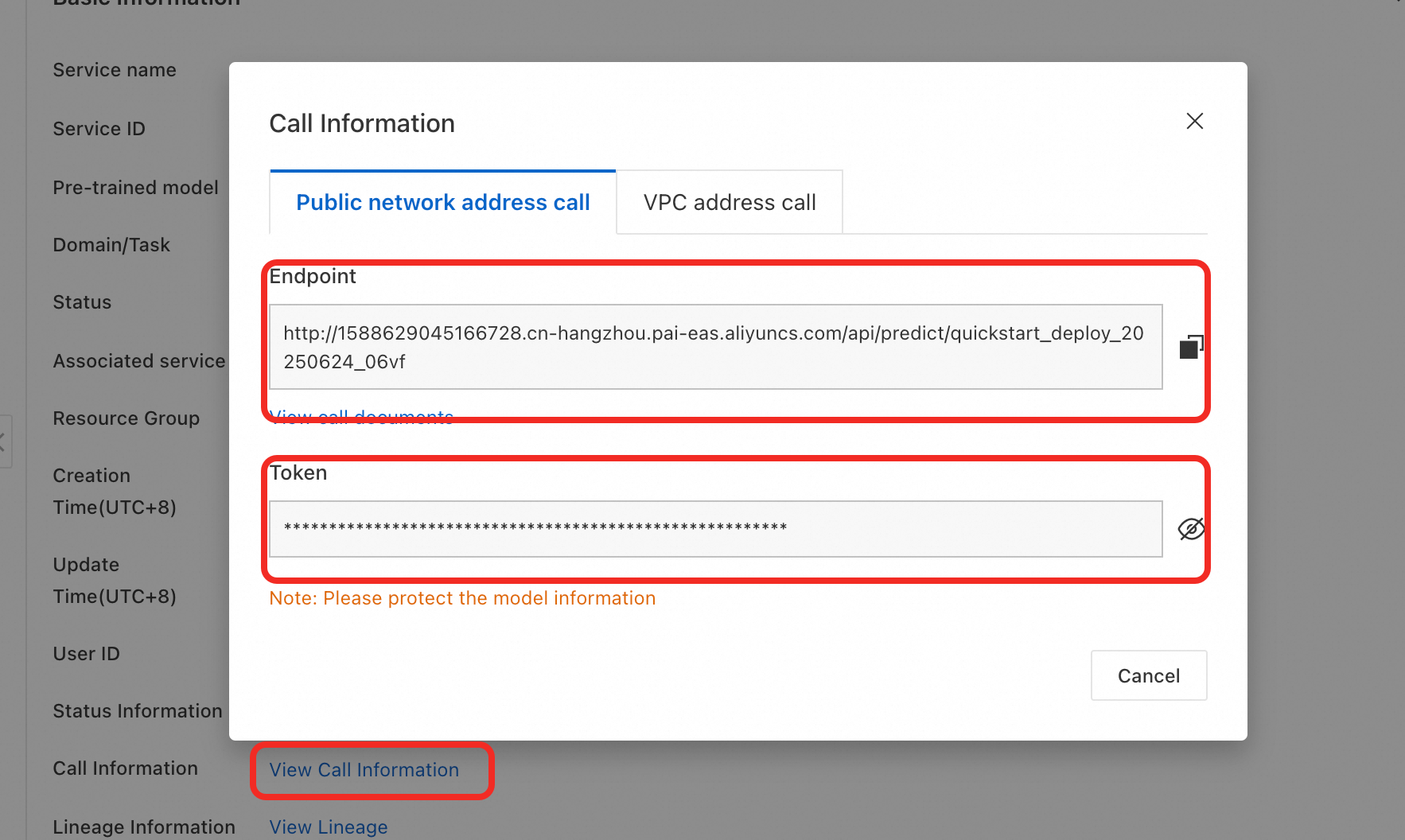
Call model service
Input parameters
|
Name |
Type |
Required |
Example |
Description |
|
model |
String |
Yes |
pai-multimodal-embedding-v1 |
Model type. Supports custom models and base model version updates. |
|
contents.input |
list(dict) or list(str) |
No |
input = [{'text': text}] input=[xxx,xxx,xxx,...] input = [{'text': text},{'image', f"data:image/{image_format};base64,{image64}"}] |
Content to embed. Supports text and image only. |
Output parameters
|
Name |
Type |
Example |
Description |
|
status_code |
Integer |
200 |
HTTP status code. 200: Success 204: Partial success 400: Failure |
|
message |
list(str) |
['Invalid input data: must be a list of strings or dict'] |
Error message |
|
output |
dict |
See next table |
Embedding result |
DashScope returns {'output', {'embeddings': list(dict), 'usage': xxx, 'request_id':xxx}} (ignore 'usage' and 'request_id').
Each element in embeddings includes these keys (errors go to message):
|
Name |
Type |
Example |
Description |
|
index |
Data ID |
0 |
HTTP status code. 200, 400, 500, etc. |
|
embedding |
List[Float] |
[0.0391846,0.0518188,.....,-0.0329895, 0.0251465] 1536 |
Embedded vector |
|
type |
String |
"Internal execute error." |
Error message |
Output example:
{
"status_code": 200,
"message": "",
"output": {
"embeddings": [
{
"index": 0,
"embedding": [
-0.020782470703125,
-0.01399993896484375,
-0.0229949951171875,
...
],
"type": "text"
}
]
}
}Evaluate model
Results on our sample data (using the evaluation file):
|
Precision of original model |
Precision after 1 epoch fine-tuning |
|
|
gme2b |
Precision@1 0.3542 Precision@5 0.5280 Precision@10 0.5923 Precision@50 0.5800 Precision@100 0.5792 |
Precision@1 0.4271 Precision@5 0.6480 Precision@10 0.7308 Precision@50 0.7331 Precision@100 0.7404 |
|
gme7b |
Precision@1 0.3958 Precision@5 0.5920 Precision@10 0.6667 Precision@50 0.6517 Precision@100 0.6415 |
Precision@1 0.4375 Precision@5 0.6680 Precision@10 0.7590 Precision@50 0.7683 Precision@100 0.7723 |
Use model
After deploying your fine-tuned embedding model on EAS, create a model connection using the steps in 3.3.2. Then use it in multimodal data management.