DSW overview
DSW (Data Science Workshop) is a cloud-based AI development IDE that supports Notebook, VS Code, and Terminal environments. DSW provides built-in images for mainstream AI frameworks such as PyTorch and TensorFlow, supports heterogeneous compute resources, and supports mounting OSS, NAS, and CPFS datasets.
Product overview
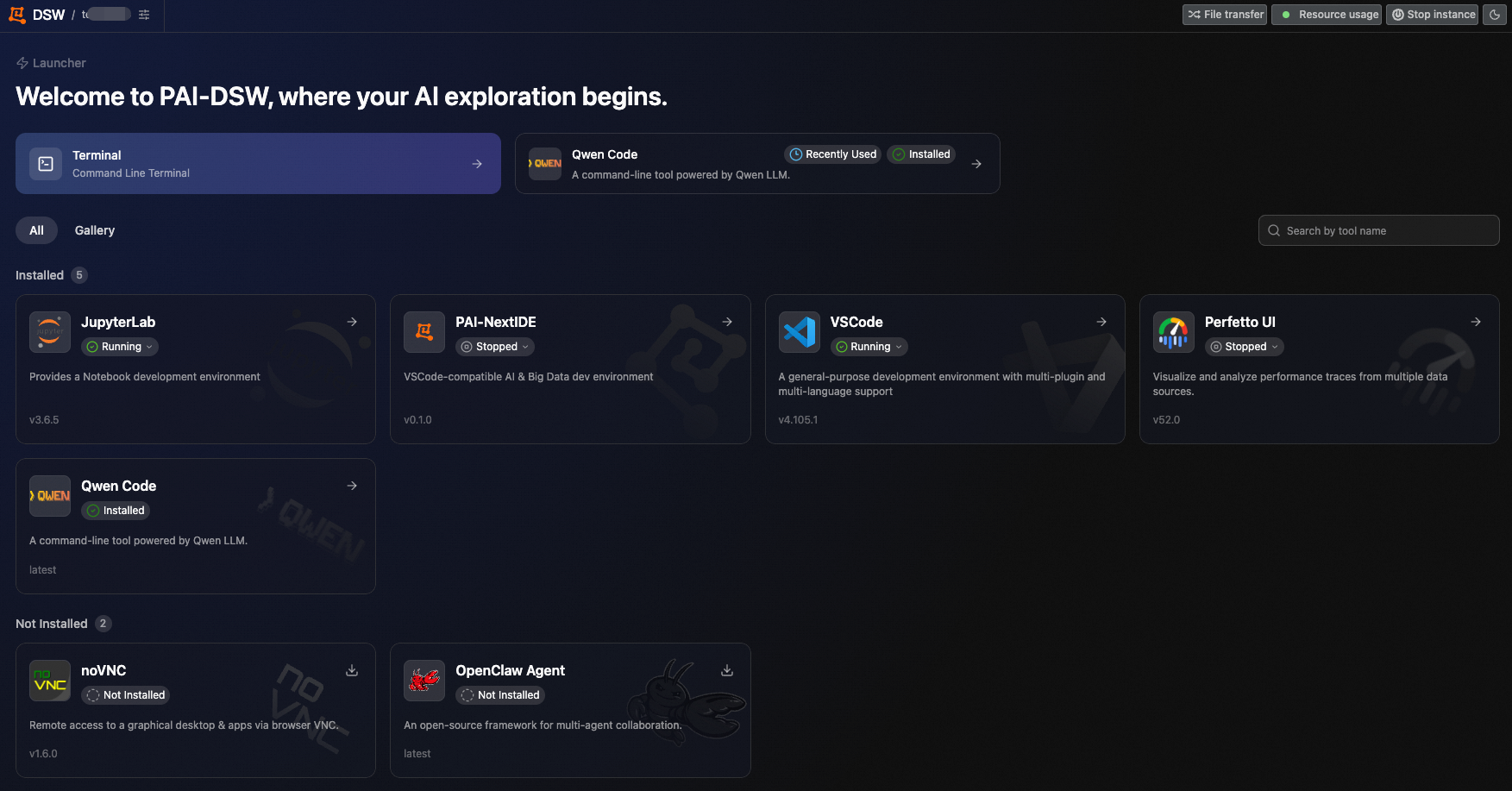
The following figures show the DSW development environment:
New version
Legacy version
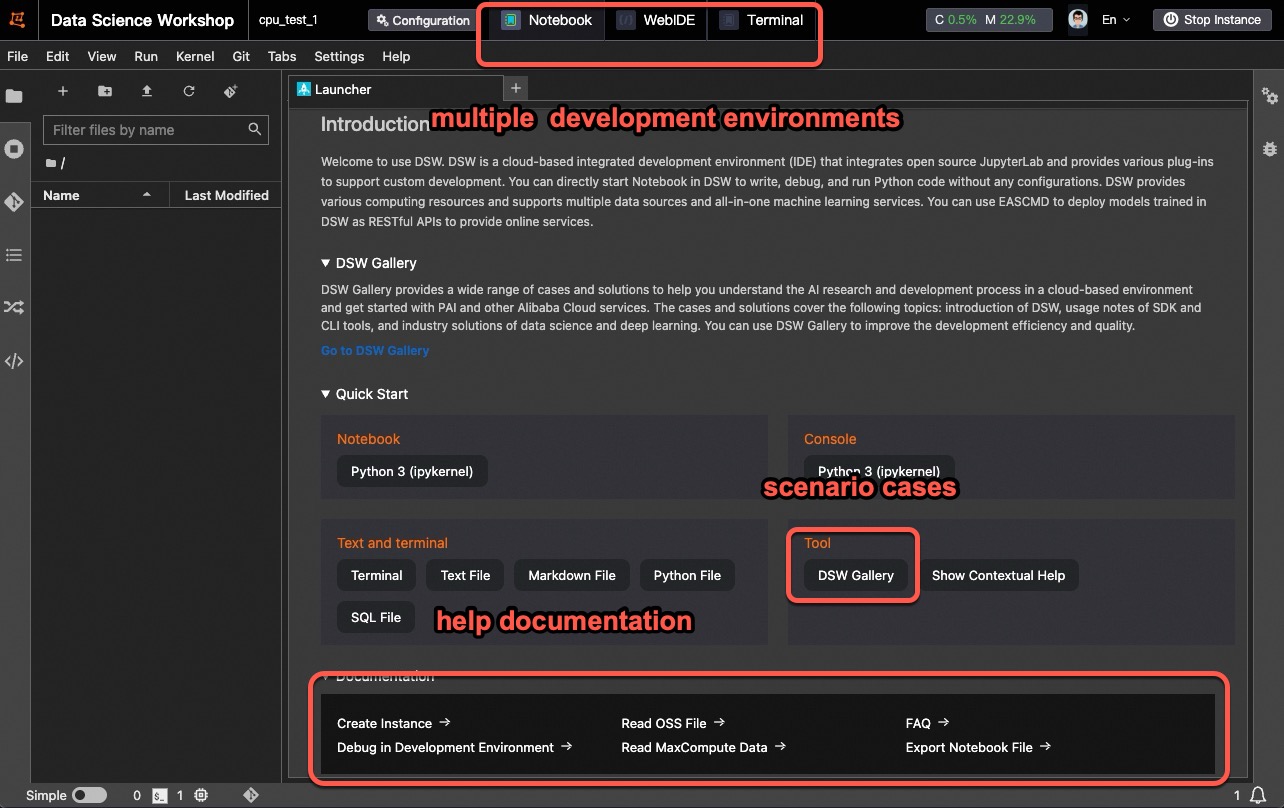
Product advantages
Flexible and easy to use: Integrates multiple development environments with built-in images for open-source frameworks such as PyTorch and TensorFlow. Supports heterogeneous compute resources: public resource groups, dedicated resources (general-purpose compute), and Lingjun intelligent computing resources.
End-to-end AI development: PAI-DLC handles distributed training and PAI-EAS handles model serving, covering the entire AI workflow from data processing to model deployment.
Fine-grained management: Supports lifecycle controls including scheduled and idle shutdown to reduce costs. Workspaces let you centrally allocate and reclaim resources.
Hands-on tutorials: Notebook Gallery Tutorials and sample projects cover LLM fine-tuning and AIGC use cases. Run them to get started, or use them as a starting point for your own projects.
Core features
Create and manage
Create a DSW instance: Select the instance resource type, mount datasets, and specify custom images when you create a DSW instance.
Access and manage DSW instances: Use DSW features in the console, and stop, release, or modify the configuration of instances.
Instance RAM role: Attach a RAM role to an instance so that you can access other cloud resources by using STS temporary credentials, without configuring long-lived AccessKey pairs. This reduces the risk of credential leaks.
Model development environment
Manage third-party libraries: Manage and install third-party Python libraries or software packages.
TensorBoard training visualization: Use the TensorBoard plug-in to visualize metrics and information during model training.
Deploy a model as an online service: When your model is ready, use PAI-EAS to deploy it as an online service with auto-scaling, version control, and resource monitoring.
Sub-container management (DockerBoard)、Use Docker in DSW: Create and manage secondary containers within a DSW instance.
Data access and mounting
Mount a dataset, OSS, NAS, or CPFS: Expand instance storage, store data persistently, and read files by mounting datasets, OSS, NAS, or CPFS paths.
Read and write data in OSS: Read and write OSS data files by using APIs or SDKs within a DSW instance.
File upload and download: Transfer data and models between your local machine and the instance.
Network configuration
Remote connection: Direct SSH connection: Connect to a DSW instance over SSH for a local development experience while using DSW's compute power.
Improve internet access with a private gateway: Create a NAT gateway and bind an elastic IP address (EIP) to the instance's VPC to increase upload and download speeds.
Access services in an instance over the public network: Access services running inside the instance from a VPC or the Internet. This is useful for testing and validating models.
Access overseas models and container images: Configure Global Accelerator (GA) for DSW to accelerate container image pulls from overseas registries (such as docker.io) or model downloads from platforms like Hugging Face.
Billing
Compute instances
DSW instances can use public resource groups or dedicated resources (general-purpose compute or Lingjun intelligent computing resources). Each option has a different billing method.
|
Instance type |
Billing method |
Billable item |
Billing rule |
Stop billing |
|
Public resources |
Pay-as-you-go |
DSW instance uptime (the duration for which the instance uses public resources). |
Billing is based on the DSW instance uptime. Important
Billing notes: DSW instances are billed by the minute, and bills are generated hourly. Due to data aggregation and processing, bills may be delayed by 2 to 3 hours. The final bill prevails. |
Stop or delete the DSW instance. Important
Stop the instance manually or configure a scheduled shutdown. For more information, see Manage DSW instances. |
|
Dedicated resources (general-purpose compute or Lingjun intelligent computing resources) |
Subscription |
Number of nodes and subscription duration for the node specifications. |
Dedicated resources are prepaid. Billing is based on the number of nodes and subscription duration for the selected node specifications. For more information, see Billing of AI computing resources. |
Unsubscribe from the resources. |
System disk
|
Billing method |
Billable item |
Billing rule |
Stop billing |
|
Pay-as-you-go |
System disk capacity and usage duration. |
A free quota is included based on the instance type and specifications. You can expand the disk; the expanded capacity is billed by capacity and usage duration. |
Delete the DSW instance. |
For more billing details, see Data Science Workshop (DSW) billing. For bill details, see View PAI billing details.
Quick start
If you're new to DSW, start with Quick start: Interactive modeling with DSW, which walks you through MNIST handwritten digit recognition to get you started.
Get help
If you encounter issues such as instance startup or shutdown failures, billing questions, free trial expirations, SSH connection failures, slow download speeds, or public access to DSW, see DSW FAQ.