The Clustering Model Evaluation component is used to evaluate clustering models and generate evaluation metrics based on raw data and clustering results.
Limits
The report of this component is available only in the Machine Learning Studio console.
Background information
The Calinski-Harabasz index is also known as the variance ratio criterion (VRC). The following figure shows the formula used to calculate the VRC. 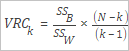
Parameter | Description |
SSB | The variance between clusters. The following figure shows the formula used to calculate the variance between clusters.
|
SSW | The variance within a cluster. The following figure shows the formula used to calculate the variance within a cluster.
|
N | The total number of records. |
k | The number of cluster center points. |
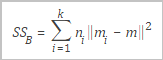 Formula description:
Formula description: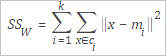 Formula description:
Formula description:Configure the component
You can use the following methods to configure the component parameters:
Method 1: Use Machine Learning Designer
Configure the component parameters on the pipeline configuration tab of Machine Learning Designer.
Tab | Parameter | Description |
Fields Setting | Evaluation Columns | The columns that are selected from the input table for evaluation. The value of this parameter must be consistent with the feature columns in the model. |
Input Sparse Format | Specifies whether the input data is sparse. Sparse data is presented by using key-value pairs. | |
KV Pair Delimiter | The delimiter that is used to separate key-value pairs. By default, commas (,) are used. | |
KV Delimiter | The delimiter that is used to separate keys and values. By default, colons (:) are used. | |
Tuning | Cores | The number of cores. This parameter must be used together with the Memory Size per Core parameter. The value of this parameter must be a positive integer. |
Memory Size per Core | The memory size of each core. This parameter must be used together with the Cores parameter. Unit: MB. |
Method 2: Use PAI commands
Configure the parameters of this component by using a Machine Learning Platform for AI (PAI) command. You can use the SQL Script component to call these commands. For more information, see SQL Script. The following table describes the parameters of the command.
PAI -name cluster_evaluation
-project algo_public
-DinputTableName=pai_cluster_evaluation_test_input
-DselectedColNames=f0,f3
-DmodelName=pai_kmeans_test_model
-DoutputTableName=pai_ft_cluster_evaluation_out;Parameter | Required | Description | Default value |
inputTableName | Yes | The name of the input table. | N/A |
selectedColNames | No | The names of the columns that are selected from the input table for evaluation. Separate multiple columns with commas (,). The value of this parameter must be consistent with the feature columns in the model. | All columns |
inputTablePartitions | No | The partitions selected from the input table for training. Specify this parameter in one of the following formats:
Note If you specify multiple partitions, separate these partitions with commas (,). | Full table |
enableSparse | No | Specifies whether the input data is sparse. Valid values: true and false. | false |
itemDelimiter | No | The delimiter that is used to separate sparse key-value pairs. | , |
kvDelimiter | No | The delimiter that is used to separate sparse keys and values. | : |
modelName | Yes | The name of the input clustering model. | N/A |
outputTableName | Yes | The name of the output table. | N/A |
lifecycle | No | The lifecycle of the output table. | N/A |
Example
Execute the following SQL statements to generate test data:
create table if not exists pai_cluster_evaluation_test_input as select * from ( select 1 as id, 1 as f0,2 as f3 union all select 2 as id, 1 as f0,3 as f3 union all select 3 as id, 1 as f0,4 as f3 union all select 4 as id, 0 as f0,3 as f3 union all select 5 as id, 0 as f0,4 as f3 )tmp;Run the following PAI command to build a clustering model. A k-means clustering model is built in this example.
PAI -name kmeans -project algo_public -DinputTableName=pai_cluster_evaluation_test_input -DselectedColNames=f0,f3 -DcenterCount=3 -Dloop=10 -Daccuracy=0.00001 -DdistanceType=euclidean -DinitCenterMethod=random -Dseed=1 -DmodelName=pai_kmeans_test_model -DidxTableName=pai_kmeans_test_idxRun the following PAI command to submit the parameters configured for the Clustering Model Evaluation component:
PAI -name cluster_evaluation -project algo_public -DinputTableName=pai_cluster_evaluation_test_input -DselectedColNames=f0,f3 -DmodelName=pai_kmeans_test_model -DoutputTableName=pai_ft_cluster_evaluation_out;View the output evaluation table pai_ft_cluster_evaluation_out and the following visualized graph.
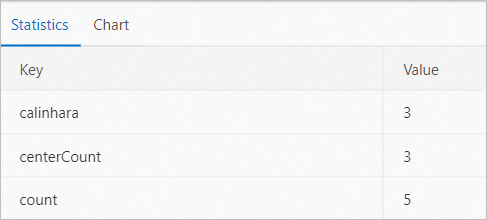 The following table describes the fields displayed in the graph.
The following table describes the fields displayed in the graph. Field
Description
count
The total number of returned entries.
centerCount
The number of cluster centers.
calinhara
The VRC.