For complex model inference scenarios, such as AIGC and video processing, long processing times can cause issues like connection timeouts and unbalanced instance loads. These workloads are not suitable for synchronous inference. To address these challenges, Platform for AI (PAI) provides an Asynchronous Inference Service that allows you to retrieve inference results by polling or through a subscription model. This document describes how to use the Asynchronous Inference Service.
Background information
Feature description
Asynchronous inference
Online inference scenarios that require low latency typically use synchronous inference, where a client sends a request and waits for the response in the same connection.
However, for scenarios with long or unpredictable processing times, waiting for a synchronous response causes issues such as HTTP connection drops and client-side timeouts. Asynchronous inference resolves these issues. The client sends a request to the server and, instead of waiting, can periodically check for the result or subscribe to a notification that is sent when the task is complete.
Queue service
For near-real-time inference scenarios, such as processing short videos, video streams, or computationally intensive images, results are not required instantly but must be available within a specified time. These scenarios present several challenges:
Simple load balancing methods like the round-robin algorithm are insufficient. Requests must be distributed based on the actual load of each instance.
If an instance failure occurs, tasks that were being processed by the failed instance must be reassigned to healthy instances.
PAI provides a dedicated queue service framework to solve these request distribution challenges.
How it works

When you create an asynchronous Inference Service, two sub-services are integrated within it: an inference sub-service and a queue sub-service. The queue sub-service contains two built-in message queues: an input queue and a sink queue. Service requests are first sent to the input queue of the queue sub-service. The EAS framework within the Inference sub-service instances automatically subscribes to the queue to fetch request data in a streaming fashion, calls the inference interface to process the data, and writes the response to the sink queue.
If the sink queue is full and cannot accept new data, the service framework stops consuming data from the Input Queue. This back-pressure mechanism prevents data from being processed when results cannot be stored.
If you do not need a sink queue, for example, if you write results directly to Object Storage Service (OSS) or your own message middleware, you can return an empty response from your synchronous HTTP inference interface. In this case, the sink queue is ignored.
A highly available queue sub-service is created to receive client requests. Instances of the inference sub-service subscribe to a specific number of requests based on their concurrent processing capacity. The queue sub-service ensures that the number of active requests on each inference sub-service instance does not exceed its subscription window size, which prevents instance overload. The final results are then returned to the client through subscription or polling.
NoteFor example, if each inference sub-service instance can only process five concurrent audio streams, set the window size to 5 when subscribing to the queue sub-service. After an instance finishes processing one stream and commits the result, the queue sub-service pushes a new stream to it. This ensures that the instance handles a maximum of five streams at any time.
The queue sub-service performs health checks by monitoring the connection status of the inference sub-service instances. If a connection is lost due to an instance failure, the queue sub-service marks the instance as unhealthy. Any requests that were already dispatched to that instance are automatically re-queued and sent to other healthy instances, ensuring no data loss during failures.
Create an asynchronous inference service
When you create an asynchronous inference service, a service group with the same name is automatically created. The queue sub-service is also created automatically and integrated into the asynchronous inference service. By default, the queue sub-service starts with one instance and scales dynamically with the number of inference sub-service instances, up to a maximum of two instances. Each queue sub-service instance is configured with 1 core and 4 GB of memory by default. If the default configuration does not meet your needs, see the Parameter configuration for a queue sub-service section of this topic.
The asynchronous inference service of EAS converts synchronous inference logic to an asynchronous pattern and supports two deployment methods:
Deploy a service using the console
Go to the Custom Deployment page and configure the following key parameters. For more information about other parameter settings, see Custom Deployment.
Deployment Method: Select Image-based Deployment or Processor-based Deployment.
Asynchronous Services: Turn on Asynchronous Services.
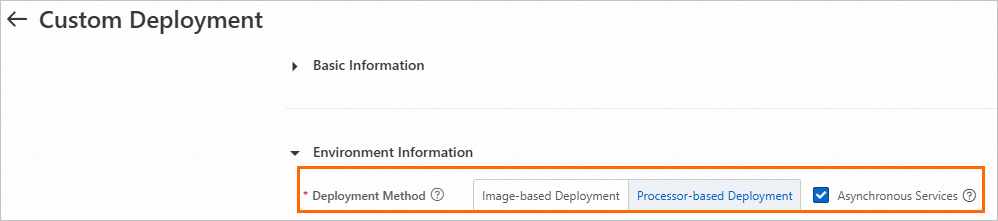
After you configure the parameters, click Deploy.
Deploy a service using the EASCMD client
Prepare a service configuration file named service.json.
Deployment method: Deploy a service using a model and a processor.
{ "processor": "pmml", "model_path": "http://example.oss-cn-shanghai.aliyuncs.com/models/lr.pmml", "metadata": { "name": "pmmlasync", "type": "Async", "cpu": 4, "instance": 1, "memory": 8000 } }Take note of the following parameters. For information about other parameter settings, see JSON deployment.
type: Set this parameter to Async to create an asynchronous inference service.
model_path: Replace this with the path to your model.
Deployment method: Deploy a service using an image.
{ "metadata": { "name": "image_async", "instance": 1, "rpc.worker_threads": 4, "type": "Async" }, "cloud": { "computing": { "instance_type": "ecs.gn6i-c16g1.4xlarge" } }, "queue": { "cpu": 1, "min_replica": 1, "memory": 4000, "resource": "" }, "containers": [ { "image": "eas-registry-vpc.cn-beijing.cr.aliyuncs.com/pai-eas/chat-llm-webui:3.0.1", "script": "python webui/webui_server.py --port=8000 --model-path=Qwen/Qwen-7B-Chat", "port": 8000 } ] }Take note of the following parameters. For information about other parameters, see Model service parameters.
type: Set this parameter to Async to create an asynchronous inference service.
instances: The number of instances for the inference sub-service. This does not include instances of the queue sub-service.
rpc.worker_threads: The number of worker threads in the EAS service framework for the asynchronous inference service. This parameter corresponds to the window size for subscribing to data from the queue. A setting of
4means that a maximum of four messages can be subscribed from the queue at a time. The queue sub-service does not push new data to the inference sub-service until these four messages are processed.For example, consider a video stream processing service where a single Inference sub-service instance can handle only two streams at a time. Set this parameter to
2. The queue sub-service then pushes a maximum of two video stream URLs to the Inference sub-service. It does not push new URLs until the instance returns a result for one of the streams. After a stream is processed and a result is returned, the queue sub-service pushes a new stream URL, ensuring that a single instance never handles more than two streams simultaneously.
Create an asynchronous inference service.
After you log on to the eascmd client, run the
createcommand to create the asynchronous inference service. For more information about how to log on to the EASCMD client, see Download and authenticate the client. The following is an example.eascmd create service.json
Access an asynchronous inference service
As described previously, a service group with the same name as your asynchronous inference service is created by default. Because the queue sub-service within this group serves as the traffic ingress, access the queue sub-service directly by using the following paths. For more information, see Access the queue service.
Endpoint type | Address format | Example |
Input queue address |
|
|
Output queue address |
|
|
Manage the asynchronous inference service
You can manage an asynchronous inference service like a regular service. Its sub-services are managed automatically by the system. For example, when you delete the asynchronous inference service, both the queue sub-service and the inference sub-service are deleted. When you update the Inference sub-service, the queue sub-service remains unchanged to ensure maximum availability.
Due to the sub-service architecture, even if you configure one instance for your asynchronous inference service, the instance list shows an additional instance for the queue sub-service.

The number of instances for an asynchronous inference service refers to the number of inference sub-service instances. The number of queue sub-service instances adjusts automatically based on the number of Inference sub-service instances. For example, when you scale out the Inference sub-service to three instances, the queue sub-service scales out to two instances.
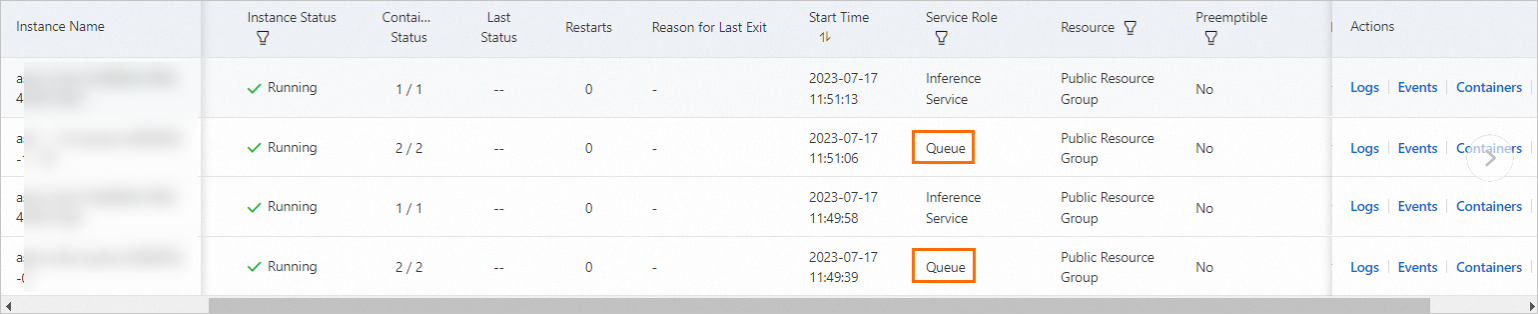
The instance ratio between the two sub-services follows these rules:
When the asynchronous inference service is stopped, the instance count for both the queue sub-service and the inference sub-service scales down to 0. The instance list is empty.
When the inference sub-service has 1 instance, the queue sub-service also has 1 instance, unless you customized the queue sub-service parameters.
When the number of inference sub-service instances exceeds 2, the number of queue sub-service instances remains at 2, unless you customized its parameters.
If you configure auto scaling for the asynchronous inference service with a minimum instance count of 0, one instance of the queue sub-service remains active even when the inference sub-service scales down to 0.
Queue sub-service parameters and descriptions
In most cases, the default configuration for the queue sub-service is sufficient. If you have specific requirements, you can configure the queue instances through the queue block in the top level of your JSON file. The following code provides an example:
{
"queue": {
"sink": {
"memory_ratio": 0.3
},
"source": {
"auto_evict": true,
}
}The following sections describe the configuration options in detail.
Configure queue sub-service resources
By default, the resources for the queue sub-service are configured based on the fields in the metadata section. However, in some use cases, you may need to configure its resources separately as described in this section.
Use
queue.resourceto specify the resource group for the queue sub-service.{ "queue": { "resource": eas-r-slzkbq4tw0p6xd**** # By default, the resource group of the inference subservice is used. } }The queue sub-service uses the same resource group as the inference sub-service by default.
If you want to deploy the queue sub-service to a public resource group, you can declare
resourceas an empty string (""). This is useful when your dedicated resource group has insufficient CPU or memory.NoteDeploy the queue sub-service to a public resource group.
Use
queue.cpuandqueue.memoryto specify the CPU (in cores) and memory (in MB) for each queue sub-service instance.{ "queue": { "cpu": 2, # Default value: 1. "memory": 8000 # Default value: 4000. } }If you do not configure these resources, the queue sub-service defaults to 1 CPU core and 4 GB of memory, which is adequate for most scenarios.
ImportantIf you have more than 200 subscribers, such as inference sub-service instances, configure 2 or more CPU cores.
Do not reduce the memory allocation for the queue sub-service in a production environment.
Use
queue.min_replicato configure the minimum number of queue sub-service instances.{ "queue": { "min_replica": 3 # Default value: 1. } }When you use an asynchronous inference service, the number of queue sub-service instances automatically adjusts based on the runtime number of inference sub-service instances. The default adjustment range is
[1, min(2, number of Inference Sub-service instances)]. In the special case where you configure an auto scaling rule that allows scaling down to 0 instances, one queue sub-service instance is automatically retained. You can usequeue.min_replicato adjust this minimum number of retained instances.NoteIncreasing the number of queue sub-service instances improves availability but does not improve performance.
Configure queue sub-service features
The queue sub-service has several configurable features that you can adjust.
Use
queue.sink.auto_evictorqueue.source.auto_evictto enable automatic data eviction for the sink queue and input queue, respectively.{ "queue": { "sink": { "auto_evict": true # Enable automatic eviction for the output queue. Default value: false. }, "source": { "auto_evict": true # Enable automatic eviction for the input queue. Default value: false. } } }By default, automatic data eviction is disabled. If a queue is full, you cannot write new data to it. In scenarios where data overflow is acceptable, enable this feature. The queue automatically evicts the oldest data to make room for new data.
Use
queue.max_deliveryto configure the maximum number of delivery attempts.{ "queue": { "max_delivery": 10 # Set the maximum number of data deliveries to 10. Default value: 5. If you set the value to 0, data can be delivered for an unlimited number of times. } }When the number of delivery attempts for a single message exceeds this threshold, the message is considered unprocessable and is marked as a dead-letter message. For more information, see dead-letter policies.
Use
queue.max_idleto configure the maximum processing time for a message.{ "queue": { "max_idle": "1m" # Set the maximum processing time for a single data entry to 1 minute. If the processing time exceeds this limit, the data entry is delivered to other subscribers and the delivery count is incremented by 1. The default value is 0, which means no maximum processing time limit. } }The time value in the example is 1 minute. Multiple time units are supported, such as
h(hour),m(minute), ands(second). If a message's processing time exceeds the configured duration, one of two things happens:If the delivery count has not reached the
queue.max_deliverythreshold, the message is redelivered to another subscriber.If the
queue.max_deliverythreshold has been reached, the dead-letter policy is executed for the message.
Use
queue.dead_message_policyto configure the dead-letter policy.{ "queue": { "dead_message_policy": "Rear" # The valid values are Rear (default) and Drop. Rear moves the message to the end of the queue, and Drop deletes the message. } }
Configure maximum queue length or maximum data volume
The maximum length and maximum payload size of a queue sub-service are inversely related. The relationship is calculated as follows:

The memory of a queue sub-service instance is fixed. Therefore, increasing the maximum payload size per message decreases the maximum length of the queue.
With the default 4 GB memory configuration and a default maximum payload size of 8 KB, both the Input Queue and Sink Queue can hold 230,399 messages. If you need to store more items, you can increase the memory size as described in the resource configuration section. The system reserves 10% of the total memory.
You cannot configure both the maximum length and maximum payload size for the same queue.
Use
queue.sink.max_lengthorqueue.source.max_lengthto configure the maximum length of the sink queue or input queue, respectively.{ "queue": { "sink": { "max_length": 8000 # Set the maximum length of the output queue to 8000 entries. }, "source": { "max_length": 2000 # Set the maximum length of the input queue to 2000 entries. } } }Use
queue.sink.max_payload_size_kborqueue.source.max_payload_size_kbto configure the maximum payload size for a single message in the sink queue or input queue, respectively.{ "queue": { "sink": { "max_payload_size_kb": 10 # Set the maximum size of a single data entry in the output queue to 10 KB. Default value: 8 KB. }, "source": { "max_payload_size_kb": 1024 # Set the maximum size of a single data entry in the input queue to 1024 KB (1 MB). Default value: 8 KB. } } }
Configure memory allocation skew
Use
queue.sink.memory_ratioto adjust the memory allocation between the input and sink queues.{ "queue": { "sink": { "memory_ratio": 0.9 # Specify the memory ratio of the output queue. Default value: 0.5. } } }NoteBy default, the input queue and sink queue evenly share the memory of the queue sub-service instance. If your service takes text as input and produces images as output, and you want to store more data in the sink queue, you can increase
queue.sink.memory_ratio. Conversely, if your service takes images as input and produces text as output, you can decreasequeue.sink.memory_ratio.
Configure horizontal auto scaling
How it works
In an asynchronous inference scenario, the system can dynamically scale the number of inference service instances based on the queue status. It also supports scaling the number of instances down to zero when the queue is empty to reduce costs. The following diagram illustrates how auto scaling for an asynchronous inference service works:

Configuration method
In the service list, click the name of the target service to open the service details page.
Switch to the Auto Scaling tab, in the Auto Scaling area, click Enable Auto Scaling.
In the Auto Scaling Settings dialog box, configure the parameters.
Basic configurations:
Parameter
Note
Example value
Minimum number of instances
The minimum number of instances a service can scale in to. The minimum value is 0.
0
Maximum number of instances
The maximum number of instances a service can scale out to. The maximum value is 1000.
10
Standard scaling metrics
Built-in performance metrics used to trigger scaling.
The Asynchronous Queue Length represents the average number of tasks per instance in the queue.
Select Asynchronous Queue Length and set the threshold to 10.
Advanced configurations:
Parameter
Note
Example value
Scale-out duration
The observation window for scale-out decisions. After a scale-out is triggered, the system observes the metric during this period. If the metric value falls back below the threshold, the scale-out is canceled. The unit is seconds.
The default value is
0seconds. A value of 0 executes the scale-out immediately.0
Scale-in effective time
The observation window for scale-in decisions, which is a key parameter to prevent service jitter. A scale-in only occurs after the metric remains below the threshold for this entire duration. The unit is seconds.
The default is
300seconds. This is the core safeguard against frequent scale-in events due to traffic fluctuations. Do not set this value too low, as it may affect service stability.300
Effective duration of scale-in to 0
When Minimum Number Of Instances is
0, this parameter defines the wait time before the instance count is reduced to0.600
Number of instances scaled out from zero
The number of instances to add when the service scales out from
0instances.1
For more information about parameter descriptions and how to use the eascmd client, see Horizontal auto scaling.