Asynchronous inference services decouple request submission from result retrieval, preventing timeouts and load imbalance for long-running AI workloads such as video processing and AIGC.
Use cases
| Scenario | Recommended mode |
|---|---|
| Processing time per request exceeds several seconds or varies unpredictably | Asynchronous |
| Requests must be distributed based on instance load | Asynchronous |
| Failed tasks are automatically reassigned to healthy instances | Asynchronous |
| Scaling to zero instances during idle periods reduces costs | Asynchronous |
| Sub-second latency required | Synchronous |
| Processing time short and predictable | Synchronous |
Architecture

An asynchronous inference service consists of two sub-services that communicate through message queues:
-
Inference sub-service: Processes requests by calling inference interfaces.
-
Queue sub-service: Manages two message queues: input queue and sink queue.
Request flow
-
Client sends request to input queue.
-
EAS framework in inference sub-service subscribes to queue and fetches request data in streaming fashion.
-
Inference sub-service processes data.
-
Inference sub-service writes response to sink queue.
-
Client retrieves result from sink queue by polling or subscription.
Load balancing and failover
Each inference sub-service instance subscribes to a specific number of requests based on its concurrent processing capacity (subscription window size). The queue sub-service withholds new data until the instance completes current tasks, preventing overload.
Example: If each instance processes five concurrent audio streams, set window size to 5. After an instance finishes one stream and commits results, the queue pushes a new stream. The instance never handles more than five streams simultaneously.
The queue sub-service monitors connection status of inference sub-service instances. If a connection drops due to instance failure, the queue marks the instance as unhealthy. Requests already dispatched to that instance are automatically re-queued and sent to healthy instances, preventing data loss.
Back pressure
If the sink queue is full, the framework stops consuming data from the input queue, preventing processing when results cannot be stored.
If a sink queue is unnecessary (for example, if results are written directly to OSS or message middleware), return an empty response from the synchronous HTTP inference interface. The sink queue is then ignored.
Prerequisites
-
PAI workspace with EAS activated. See Custom Deployment.
-
(For EASCMD deployment) EASCMD client installed and authenticated. See Download and authenticate the client.
Create an asynchronous inference service
Creating an asynchronous inference service automatically creates a service group with the same name. The queue sub-service is created automatically with the following defaults:
| Property | Default |
|---|---|
| Initial instances | 1 |
| Maximum instances | 2 (scales dynamically with inference sub-service instances) |
| CPU per instance | 1 core |
| Memory per instance | 4 GB (4000 MB) |
Deploy using the console
-
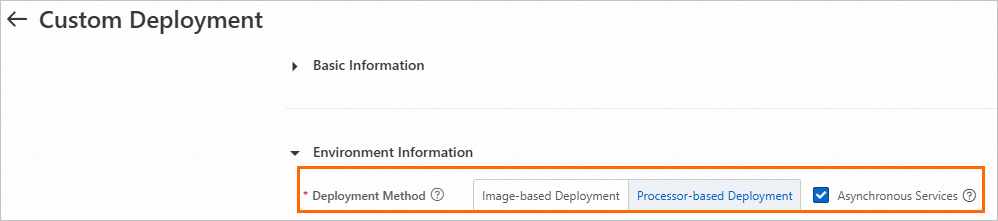
Go to the Custom Deployment page and configure the following parameters. For other parameters, see Custom Deployment.
-
Deployment Method: Select Image-based Deployment or Processor-based Deployment.
-
Asynchronous Services: Enable Asynchronous Services.
-
-
Click Deploy.
Deploy using the EASCMD client
-
Create a service configuration file named
service.json. Model and processor deployment: Image-based deployment: For other parameters, see Model service parameters.Example: For a video stream processing service where a single instance handles two streams at a time, set
rpc.worker_threadsto2. The queue sub-service pushes a maximum of two video stream URLs to the instance. After a stream is processed and a result returns, the queue sub-service pushes a new stream URL. A single instance never handles more than two streams simultaneously.Key parameters
Parameter Description typeSet to Asyncto create asynchronous inference service.instanceNumber of inference sub-service instances. Excludes queue sub-service instances. model_pathPath to model. Replace with your model path. rpc.worker_threadsSubscription window size: maximum messages fetched from queue at a time. The queue sub-service withholds new data until these messages are processed. { "processor": "pmml", "model_path": "http://example.oss-cn-shanghai.aliyuncs.com/models/lr.pmml", "metadata": { "name": "pmmlasync", "type": "Async", "cpu": 4, "instance": 1, "memory": 8000 } }{ "metadata": { "name": "image_async", "instance": 1, "rpc.worker_threads": 4, "type": "Async" }, "cloud": { "computing": { "instance_type": "ecs.gn6i-c16g1.4xlarge" } }, "queue": { "cpu": 1, "min_replica": 1, "memory": 4000, "resource": "" }, "containers": [ { "image": "eas-registry-vpc.cn-beijing.cr.aliyuncs.com/pai-eas/chat-llm-webui:3.0.4", "script": "python webui/webui_server.py --port=8000 --model-path=Qwen/Qwen-7B-Chat", "port": 8000 } ] } -
Run the
createcommand:eascmd create service.json
Access the service
The queue sub-service serves as traffic ingress. Send requests directly to the queue sub-service using the following endpoints. For more information, see Access the queue service.
| Endpoint | Address format | Example |
|---|---|---|
| Input queue | {domain}/api/predict/{service_name} |
xxx.cn-shanghai.pai-eas.aliyuncs.com/api/predict/{service_name} |
| Output queue (sink) | {domain}/api/predict/{service_name}/sink |
xxx.cn-shanghai.pai-eas.aliyuncs.com/api/predict/{service_name}/sink |
Manage the service
Manage an asynchronous inference service like a regular service. Sub-services are managed automatically:
-
Deleting the asynchronous inference service deletes both sub-services.
-
Updating the inference sub-service does not affect the queue sub-service, ensuring availability.
Due to the sub-service architecture, the instance list shows an additional instance for the queue sub-service even if one instance is configured.

Instance count refers to inference sub-service instances only. Queue sub-service instances adjust automatically based on inference sub-service instance count.
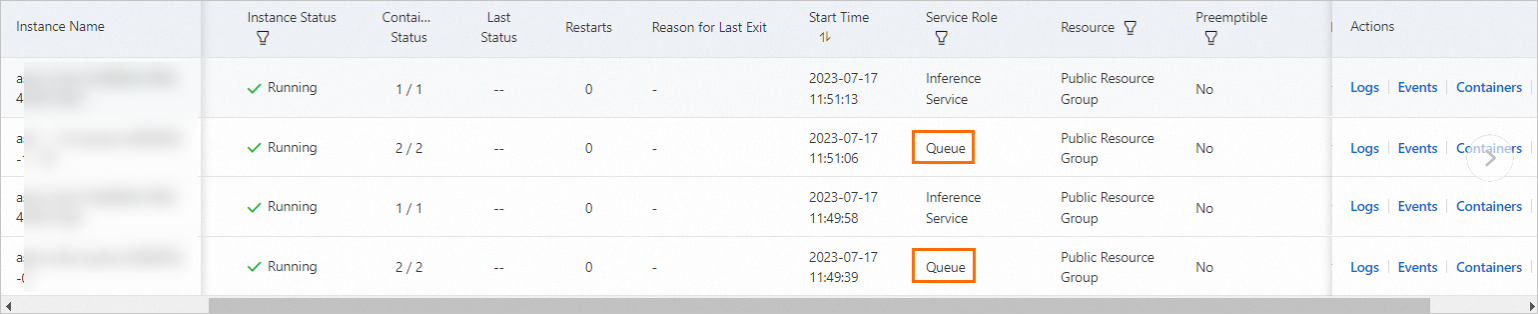
Instance ratio rules
| Inference sub-service instances | Queue sub-service instances |
|---|---|
| 0 (service stopped) | 0 |
| 1 | 1 (unless customized) |
| More than 2 | 2 (unless customized) |
| Auto scaling with min = 0 (inference scaled to 0) | 1 (retained for availability) |
Configure horizontal auto scaling
The system dynamically scales inference sub-service instances based on queue status. It supports scaling to zero instances when the queue is empty.

-
In the service list, click the service name to open service details.
-
On the Auto Scaling tab, in the Auto Scaling area, click Enable Auto Scaling.
-
In the Auto Scaling Settings dialog box, configure the following parameters. For more information about parameters and EASCMD client configuration, see Horizontal auto scaling.
Parameter Description Default Minimum number of instances Minimum instance count. Minimum value is 0. - Maximum number of instances Maximum instance count. Maximum value is 1000. - Standard scaling metrics Metric to trigger scaling. Select Asynchronous Queue Length, which represents average task count per instance in the queue. - Scale-out duration Observation window in seconds for scale-out decisions. If metric falls below threshold during this window, scale-out is canceled. Set to 0 to execute immediately. 0 Scale-in effective time Observation window in seconds for scale-in decisions. Scale-in occurs only after metric remains below threshold for this duration. Avoid setting too low to prevent instability. 300 Effective duration of scale-in to 0 When Minimum number of instances is 0, wait time in seconds before instance count is reduced to 0. - Number of instances scaled out from zero Number of instances to add when the service scales from 0 instances. -
Customize queue sub-service
In most cases, default configuration is sufficient. To customize the queue sub-service, add a queue block to the JSON configuration file.
Queue parameters reference
| Parameter | Default | Description |
|---|---|---|
queue.cpu |
1 core | CPU allocation per queue sub-service instance. Set to 2 or more cores for more than 200 subscribers. |
queue.memory |
4000 MB (4 GB) | Memory allocation per queue sub-service instance. Avoid reducing in production. |
queue.min_replica |
1 | Minimum queue sub-service instances. |
queue.resource |
Same as inference sub-service | Resource group for queue sub-service. Set to empty string ("") to deploy to public resource group. |
queue.sink.memory_ratio |
0.5 | Memory ratio allocated to the sink queue. Increase for large outputs; decrease for large inputs. |
queue.sink.max_payload_size_kb / queue.source.max_payload_size_kb |
8 KB | Maximum payload size per message. |
queue.sink.max_length / queue.source.max_length |
Not set (capacity depends on memory and payload size) | Maximum queue length. With 4 GB memory and 8 KB max payload, each queue holds up to 230,399 messages. Cannot be set with max_payload_size_kb for same queue. |
queue.max_delivery |
5 | Maximum delivery attempts per message. Set to 0 for unlimited. When exceeded, message is marked as dead-letter. |
queue.max_idle |
0 (no limit) | Maximum processing time per message. Supports h, m, s units. |
queue.dead_message_policy |
Rear |
Dead-letter policy. Rear moves the message to the end of the queue. Drop deletes it. |
queue.sink.auto_evict / queue.source.auto_evict |
false | Automatic data eviction. When enabled, queue evicts oldest data to accommodate new data. When disabled and queue is full, new data cannot be written. |
Max queue length and max payload size are inversely related. Increasing max payload size per message decreases max queue length. The system reserves 10% of total memory. Both max_length and max_payload_size_kb cannot be configured for same queue simultaneously.

Configure resource allocation
By default, the queue sub-service uses the same resource group as the inference sub-service.
Specify a resource group
{
"queue": {
"resource": "eas-r-slzkbq4tw0p6xd****"
}
}To deploy the queue sub-service to a public resource group (useful when dedicated resource group has insufficient CPU or memory), set resource to empty string ("").
Specify CPU and memory
{
"queue": {
"cpu": 2,
"memory": 8000
}
}-
For more than 200 subscribers (inference sub-service instances), configure 2 or more CPU cores.
-
Avoid reducing memory allocation for queue sub-service in production.
Specify minimum number of queue instances
{
"queue": {
"min_replica": 3
}
}The default adjustment range for queue sub-service instances is [1, min(2, number of inference sub-service instances)]. With auto scaling that allows scaling to 0 instances, one queue sub-service instance is automatically retained. Use queue.min_replica to adjust this minimum.
Increasing the number of queue sub-service instances improves availability but does not improve performance.
Configure memory allocation between queues
By default, input queue and sink queue evenly share memory of the queue sub-service instance. Adjust the ratio based on workload.
{
"queue": {
"sink": {
"memory_ratio": 0.9
}
}
}If the service takes text as input and produces images as output, increasequeue.sink.memory_ratioto store more results. If the service takes images as input and produces text as output, decreasequeue.sink.memory_ratio.
Configure queue length and payload size
With default 4 GB memory and 8 KB max payload size, both input queue and sink queue hold 230,399 messages. To store more messages, increase memory size as described in the resource configuration section.
Configure max queue length
{
"queue": {
"sink": {
"max_length": 8000
},
"source": {
"max_length": 2000
}
}
}Configure max payload size
{
"queue": {
"sink": {
"max_payload_size_kb": 10
},
"source": {
"max_payload_size_kb": 1024
}
}
}Enable automatic data eviction
By default, automatic data eviction is disabled. If a queue is full, new data cannot be written. In scenarios where data overflow is acceptable, enable eviction. The queue automatically evicts oldest data to accommodate new data.
{
"queue": {
"sink": {
"auto_evict": true
},
"source": {
"auto_evict": true
}
}
}Configure message delivery and dead-letter handling
Maximum delivery attempts
{
"queue": {
"max_delivery": 10
}
}When delivery count for a message exceeds this threshold, the message is marked as dead-letter.
Maximum processing time
{
"queue": {
"max_idle": "1m"
}
}Supported time units: h (hour), m (minute), s (second). If a message exceeds configured processing time:
-
If delivery count has not reached
queue.max_delivery, the message is redelivered to another subscriber. -
If
queue.max_deliveryhas been reached, dead-letter policy is executed.
Dead-letter policy
{
"queue": {
"dead_message_policy": "Rear"
}
}Valid values: Rear (default) moves message to queue end. Drop deletes it.