The Factorization Machine (FM) algorithm is a nonlinear model that incorporates interactions among features. This algorithm is suitable for recommendation scenarios in e-commerce, advertising, and live streaming industries. Machine Learning Designer uses FM training, FM prediction, and evaluation components to preset an FM algorithm template. You can use the template to generate an FM recommendation model based on the Alink framework. This topic describes how to use the FM algorithm template provided by Machine Learning Designer to generate an FM recommendation model.
Procedure
Go to the Machine Learning Designer page.
-
Log on to the PAI console.
-
In the left-side navigation pane, click Workspaces. On the Workspaces page, click the name of the workspace that you want to manage.
-
In the left-side navigation pane, choose .
-
-
Create a pipeline.
-
On the Visualized Modeling (Designer) page, click the Preset Templates tab.
-
On this tab, find the [Alink]FM-Embedding for Rec-System template and click Create.
-
In the New Workflow dialog box, configure the parameters. You can use the default values.
The Workflow Data Storage is set to an OSS bucket path to store temporary data and models generated when the workflow is running.
-
Click OK.
The workflow is created in about 10 seconds.
-
On the Pipelines tab, click the created pipeline. In the Basic Information section on the right side, click Open.
On the pipeline configuration tab, you can view the created pipeline on a canvas, as shown in the following figure.

The pipeline allows you to call the Alink algorithm to perform FM training and prediction by using one of the following two methods:
-
Method 1: Use encapsulated FM Train and FM Prediction components to perform FM training and prediction.
The FM Train and FM Prediction components are Alink components that are marked with a purple dot. Alink components can be run in groups. For information about how to run Alink components by group and the advantages and disadvantages, see Alink components.
-
Method 2: Use PyAlink components to perform FM training and prediction.
You can use custom PyAlink components to perform FM training and prediction based on Python code. This method implements the same feature as Method 1. For information about operators supported by PyAlink components, see Overview of Alink.
-
-
-
Configure the parameters of the FM Train-1 node.
-
Click the FM Train-1 node on the canvas.
-
On the Fields Setting tab in the right-side panel, configure the parameters that are described in the following table.
Parameter
Description
Feature Columns
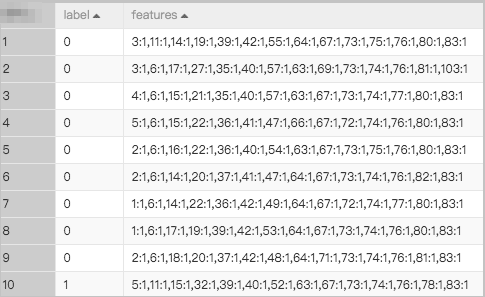
The name of the feature column. The data in the feature column is in the key:value format. Multiple key-value pairs in the feature column are separated by commas (,).
Label column
The name of the label column. The label column must be of the DOUBLE data type.
The FM algorithm that is provided by Machine Learning Designer supports only data in the LIBSVM format. You can convert data that is in another format to the LIBSVM format by using a one-hot encoding component. For more information, see One-hot encoding. The input data must include a feature column and a label column, as shown in the following figure.
-
On the Parameters Setting and Tuning tabs in the right-side panel, configure the training parameters.
If the pipeline involves 120 million sample data records and 1.3 million feature data records, we recommend that you set the training parameters that are described in the following table to the recommended values, and use the default values for other parameters. You can modify the values for the training parameters based on the amount of data that is involved.
Tab
Parameter
Description
Parameters Setting
Learning rate
The learning rate. Recommended value: 0.005. If the training is divergent, set this parameter to a smaller value.
Dimensions
The number of dimensions. Recommended value: 1,1,16.
Block size
-
The size of the block. If less than two million feature data records are involved, we recommend that you set this parameter to 1000000.
-
If two million feature data records or more are involved, you do not need to set this parameter.
Tuning
Number of Workers
The number of nodes to be used. Recommended value: 32. If a large amount of data is involved, set this parameter to a greater value.
Memory Size per Node (MB)
The memory size to be allocated to each node. Recommended value: 16384. Unit: MB.
-
-
-
Write code for the PyAlink FM training node and PyAlink FM prediction node.
-
Write code for the PyAlink FM training node.

from pyalink.alink import * def main(sources, sinks, parameter): print('start') # Mode 1 for calling the Alink algorithm. # train = HugeFmTrainBatchOp().setVectorCol('features').setLabelCol('label').linkFrom(sources[0]) # Mode 2 for calling the Alink algorithm. train = HugeFmTrainBatchOp( vectorCol='features', labelCol='label', task='binary_classification', numEpochs=10) # Obtain the training data from input port 0. The trained model is generated from output port 0 and passed downstream. sources[0].link(train).link(sinks[0]) BatchOperator.execute() print('end') -
Write code for the PyAlink FM prediction node.

from pyalink.alink import * def main(sources, sinks, parameter): predictor = HugeFmPredictBatchOp().setPredictionCol("prediction_result")\ .setPredictionDetailCol("prediction_detail").setReservedCols(["label"]) output = predictor.linkFrom(sources[0], sources[1]) # The prediction result is generated from the first output port and passed downstream. output.link(sinks[0]) BatchOperator.execute() print('predict end')
-
-
In the upper-left corner of the canvas, click the Run icon.

-
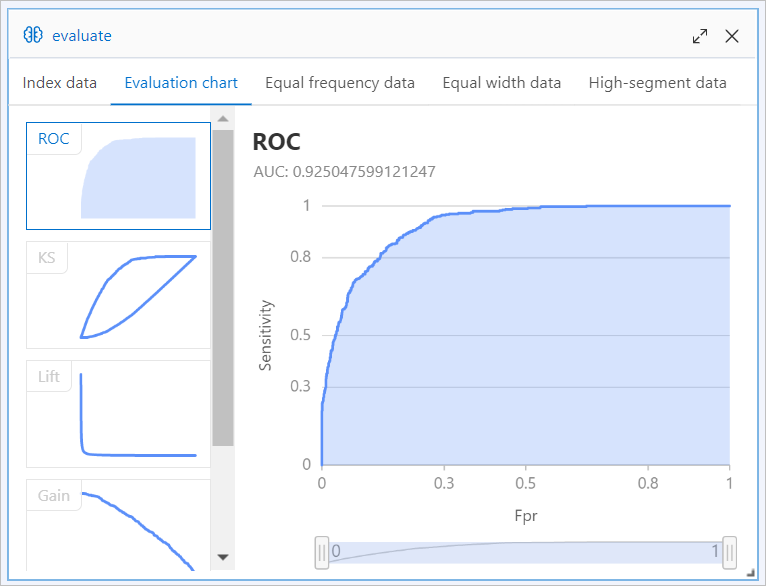
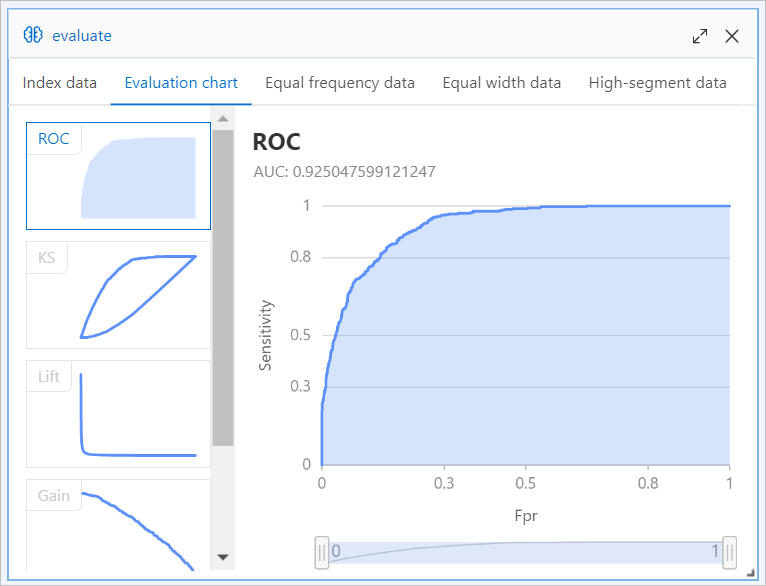
After the pipeline is run, right-click a Binary Classification Evaluation node on the canvas and select Visual Analysis.
The FM algorithm provided by Machine Learning Designer can use the data of the [Alink]FM-Embedding for Rec-System template to create a model with an area under curve (AUC) close to 0.92.
-
Evaluation report generated by using Method 1
-
Evaluation report generated by using Method 2
-