Model compression reduces model size and computational complexity through techniques such as quantization, with minimal impact on its predictive performance. It is ideal for scenarios with limited GPU memory or when you need to lower deployment costs.
How it works
PAI Model Gallery supports model quantization based on the Weight-only Quantization technique. By using the MinMax-8Bit or MinMax-4Bit strategy, you can quantize a model's floating-point weight parameters into 8-bit or 4-bit integer representations. This reduces model size and GPU memory usage while maintaining good performance.
Compress a model
-
Train the model.
A model must be trained before you can compress it. For more information, see model deployment and training.
-
After model training completes, click Compression in the upper-right corner of the Task details page.
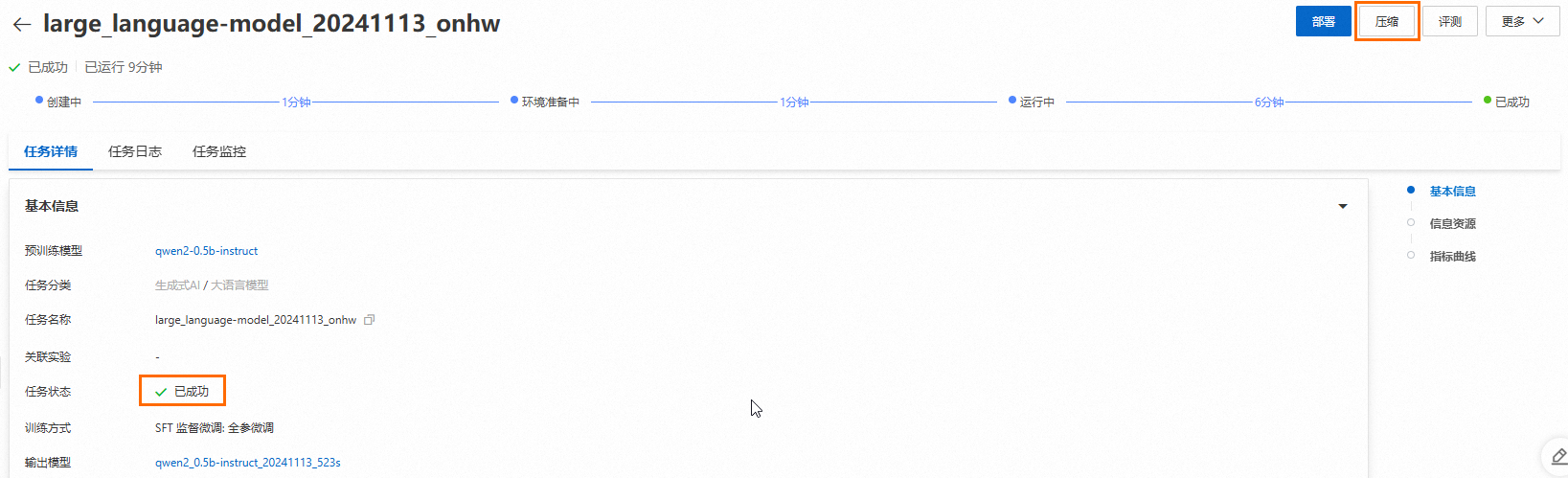
-
Configure compression parameters.
The following table describes the key parameters.
Parameter
Description
Compression method
Only model quantization (Weight-only Quantization) is supported. This converts weight parameters to a lower bit width to reduce GPU memory usage during inference.
Compression strategy
-
MinMax-8Bit: Quantizes model weights to 8-bit integers by using min-max scaling.
-
MinMax-4Bit: Quantizes model weights to 4-bit integers by using min-max scaling.
For other parameters, see Model deployment and training.
-
-
Click Compression.
You are redirected to the Task details page, where you can view the compression job's basic information, real-time status, and task logs.
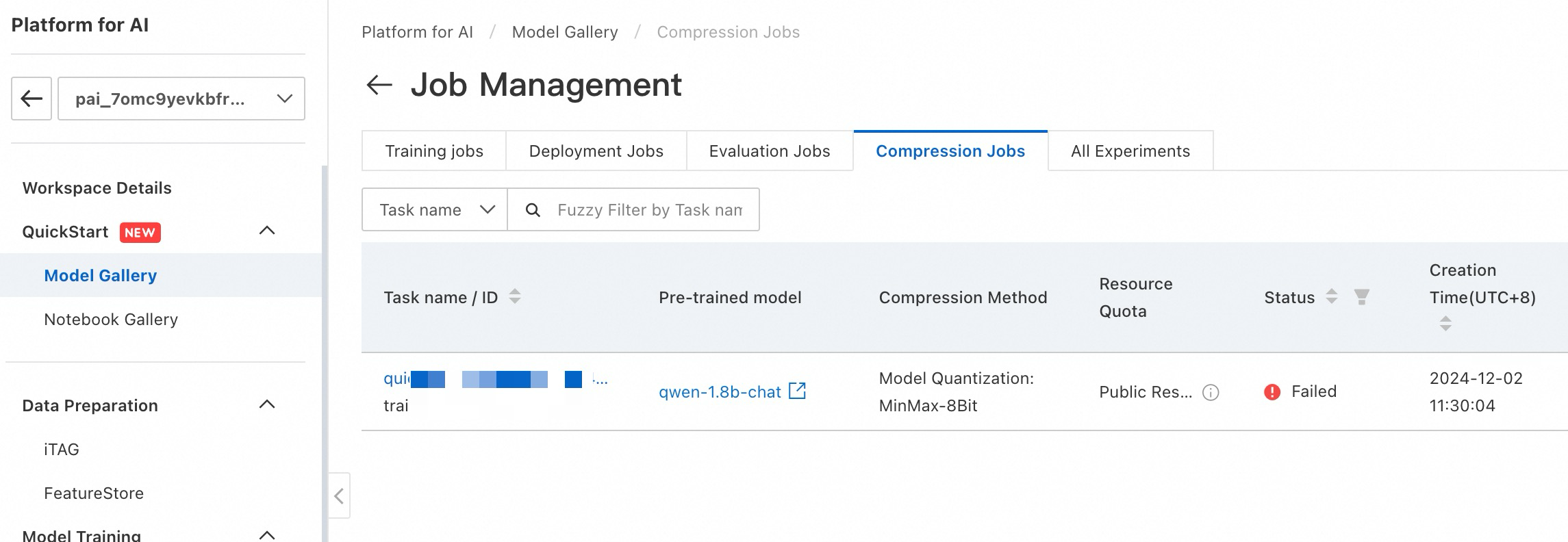
View compression jobs
To view compression jobs, go to PAI Model Gallery > Job Management > Compression Jobs.