Raw text datasets used for LLM training often contain broken Unicode characters — garbled punctuation, misencoded apostrophes, and fullwidth characters that degrade model quality — as well as traditional Chinese text that needs to be unified to simplified Chinese. The LLM-Text Normalizer (DLC) component fixes both issues automatically as part of a Machine Learning Designer pipeline, so you can feed cleaner data to downstream filtering and deduplication steps without writing custom preprocessing scripts.
How it works
The component processes each JSON object in the input file and applies the selected normalization operations to the target field:
Unicode normalization uses the ftfy library to repair broken Unicode and then applies NFKC (Normalization Form Compatibility Composition) normalization via
ftfy.fix_text(text, normalization='NFKC').Traditional-to-simplified Chinese conversion uses the opencc library to convert traditional Chinese characters to simplified Chinese.
Both operations are enabled by default and can be applied independently.
Prerequisites
Before you begin, make sure you have:
Input data stored in Object Storage Service (OSS) in JSON Lines (JSONL) format
Input data format
The input file must meet the following requirements:
Each line is a valid JSON object
The file consists of multiple JSON objects, one per line
The file as a whole is not a valid JSON object
For a sample input file, see the example data.
Supported computing resources
Configure the component
On the pipeline page of Machine Learning Designer, configure the parameters of the LLM-Text Normalizer (DLC) component.
Fields setting
| Parameter | Required | Description | Default |
|---|---|---|---|
| Target Process Field | Yes | The name of the JSON field to normalize. | — |
| Whether to normalize Unicode text (NFKC form) | No | Normalizes Unicode text using the NFKC method via ftfy. | Selected |
| Whether to convert traditional to simplified chinese | No | Converts traditional Chinese characters to simplified Chinese using opencc. | Selected |
| OSS Directory for Saving OutputData | No | The OSS directory for the output data. If left blank, the default workspace path is used. | — |
Tuning
| Parameter | Required | Description | Default |
|---|---|---|---|
| Number of Processes | No | The number of parallel processes for normalization. | 8 |
Select resource group
| Parameter | Required | Description | Default |
|---|---|---|---|
| Public Resource Group | No | The instance type (CPU or GPU), number of instances, and virtual private cloud (VPC). | — |
| Dedicated resource group | No | The number of vCPUs, memory, shared memory, number of GPUs, and number of instances. | — |
| Maximum Running Duration | No | The maximum time the component can run. If exceeded, the job is terminated. | — |
Examples
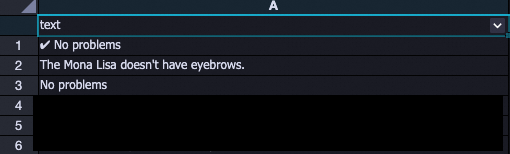
The following screenshots show the same text field before and after normalization.
Before processing:
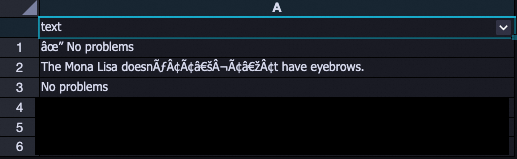
After processing: