The Linear Model Feature Importance component calculates feature importance scores for linear models, including linear regression and logistic regression for binary classification. It supports both sparse and dense input data formats.
Use this component to identify which features contribute most to model predictions — a key step in model debugging, feature selection, and building trust in model behavior.
Limitations
This component runs only on MaxCompute computing resources.
Prerequisites
Before you begin, make sure you have:
A trained linear model (linear regression or logistic regression for binary classification)
An input table in MaxCompute containing the feature columns and label column
Configure the component
Configure the component using one of the following methods.
Method 1: PAI console (Machine Learning Designer)
Set the parameters on the Fields Setting and Tuning tabs in Machine Learning Designer.
Fields Setting tab
| Parameter | Required | Description | Default |
|---|---|---|---|
| Feature columns | No | Feature columns for training from the input table | All columns except the label column |
| Target column | Yes | The label column. Click Select fields, search for the column by keyword, select it, and click OK. | — |
| Input sparse format data | No | Specifies whether the input data is in sparse format | — |
Tuning tab
| Parameter | Required | Description | Default |
|---|---|---|---|
| Cores | No | Number of cores for computing | Determined by the system |
| Memory size per core | No | Memory allocated to each core, in MB | Determined by the system |
Method 2: PAI commands
Run the component using a PAI command. Use the SQL Script component to call PAI commands. For more information, see SQL Script.
PAI -name regression_feature_importance -project algo_public
-DmodelName=xlab_m_logisticregressi_20317_v0
-DoutputTableName=pai_temp_2252_20321_1
-DlabelColName=y
-DfeatureColNames=pdays,previous,emp_var_rate,cons_price_idx,cons_conf_idx,euribor3m,nr_employed,age,campaign
-DenableSparse=false -DinputTableName=pai_dense_10_9;| Parameter | Required | Description | Default |
|---|---|---|---|
inputTableName | Yes | Name of the input table | None |
outputTableName | Yes | Name of the output table | None |
labelColName | Yes | Label column from the input table | None |
modelName | Yes | Name of the input model | None |
featureColNames | No | Feature columns from the input table | All columns except the label column |
inputTablePartitions | No | Partitions to read from the input table | Full table |
enableSparse | No | Specifies whether the input data is in sparse format | false |
itemDelimiter | No | Delimiter between key-value pairs in sparse data | Space |
kvDelimiter | No | Delimiter between keys and values in sparse data | Colon (:) |
lifecycle | No | Lifecycle of the output table | Not specified |
coreNum | No | Number of cores | Determined by the system |
memSizePerCore | No | Memory size per core | Determined by the system |
Example
This example uses the bank_data dataset to train a logistic regression model and then calculate feature importance scores.
Create a table named
bank_dataand import data. For more information, see Create tables and Import data to tables.Run the following SQL statement to generate training data:
CREATE TABLE IF NOT EXISTS pai_dense_10_9 AS SELECT age, campaign, pdays, previous, emp_var_rate, cons_price_idx, cons_conf_idx, euribor3m, nr_employed, fixed_deposit FROM bank_data LIMIT 10;Build and run a pipeline in Machine Learning Designer. For more information about creating pipelines, see Algorithm modeling.
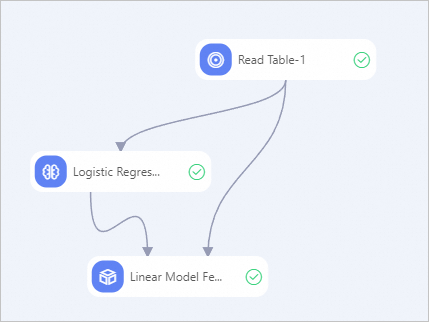
In the component list, search for and drag the following three components onto the canvas: Read Table, Logistic Regression for Multiclass Classification, and Linear Model Feature Importance.
Connect the components in the order shown in the figure above.
Configure each component:
Click Read Table-1. On the Select table tab, set Table name to
bank_data.Click Logistic Regression for Multiclass Classification-1. On the Fields Setting tab, set Training feature columns to
age,campaign,pdays,previous,emp_var_rate,cons_price_idx,cons_conf_idx,euribor3m, andnr_installed. Set Target columns tofixed_deposit.Click Linear Model Feature Importance-1. On the Fields Setting tab, set Target column to
fixed_deposit.
Click
 to run the pipeline.
to run the pipeline.
After the pipeline completes, right-click Linear Model Feature Importance-1 and choose View data > Model importance table.
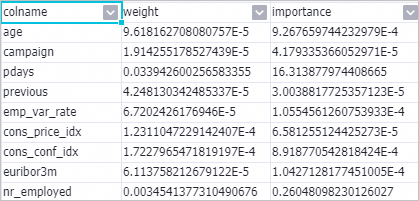 The output table contains two columns:
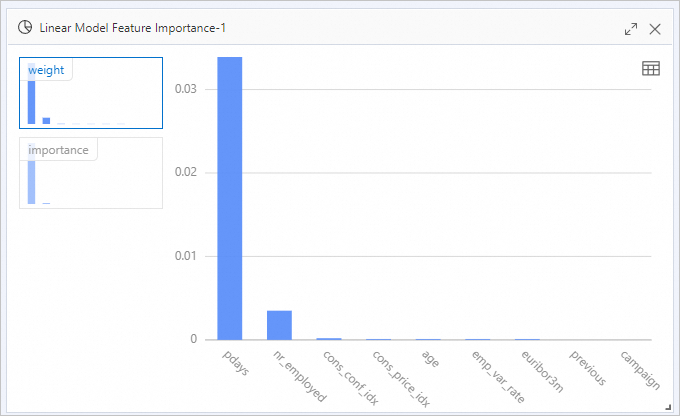
The output table contains two columns:Column Formula What it measures weightabs(w_)Absolute value of the feature coefficient importanceabs(w_j) × STD(f_i)Coefficient scaled by the feature's standard deviation (standard deviation of the training data) Right-click Linear Model Feature Importance-1 and select View analytics report to see visualized importance rankings.
What's next
For an overview of all components available in Machine Learning Designer, see Overview of Machine Learning Designer.
To explore other algorithm components, see Component reference: Overview of all components.