Overview
In the era of digital operations, gaming companies need fine-grained analysis of player behavior to improve retention, monetization, and engagement. Traditional data warehouse architectures face high costs, poor scalability, and engine fragmentation.
This solution is built on the Alibaba Cloud OpenLake open source lakehouse framework and uses the following core components:
EMR Serverless Spark: A serverless Spark engine for efficient ETL.
Paimon: A unified streaming-batch lake storage format that supports ACID transactions, schema evolution, and time travel.
DLF (Data Lake Formation): Unified metadata management that connects Spark, StarRocks, Flink, and other engines.
StarRocks: A high-speed unified analytics engine that supports high-concurrency point queries and complex OLAP.
With this solution, you can:
Model data in layers—from raw logs in OSS to the DWD and ADS layers.
Run flexible, powerful batch ETL with Spark.
Write processed results to Paimon lake tables for multi-engine sharing.
Query lake or internal tables directly with StarRocks to power BI reports and ad hoc analysis.
Architecture Diagram
Prerequisites
Complete the following preparations:
Product | Action |
EMR Serverless | Create a Spark compute cluster and attach DLF permissions. |
DLF | Enable the service. Create a Paimon catalog in your target region and get the |
StarRocks | Deploy an EMR Serverless StarRocks instance (optional—skip if you use only Spark + Paimon). |
DataWorks | Run Spark ETL scripts. |
Procedure
Step 1: Configure environment variables (run in Notebook)
%emr_serverless_spark
DLF_CATALOG_ID = "clg-paimon-e62c8d1e8fa04ee097be4870af155296" # ← Replace with your DLF Catalog ID
REGION = "cn-hangzhou" # ← Replace with your region
print(f"DLF Catalog ID: {DLF_CATALOG_ID}")
print(f"Region: {REGION}")Step 2: Initialize Spark Session and verify data sources
from pyspark.sql import SparkSession
OSS_PUBLIC_BUCKET = f"emr-starrocks-benchmark-resource-{REGION}"
PROFILE_SRC_GLOB = f"oss://{OSS_PUBLIC_BUCKET}/sr_game_demo_v2/user_profile/*.parquet"
EVENT_SRC_GLOB = f"oss://{OSS_PUBLIC_BUCKET}/sr_game_demo_v2/user_event/*.parquet"
spark = (
SparkSession.builder
.appName("DLF-Paimon-Ingest-sr_game_demo_v2")
.config("spark.dlf.catalog.id", DLF_CATALOG_ID)
.config("spark.dlf.region", REGION)
.config("spark.hadoop.fs.oss.endpoint", f"oss-{REGION}-internal.aliyuncs.com")
.enableHiveSupport()
.getOrCreate()
)
# Verify files exist
def glob_count(path_glob: str) -> int:
from py4j.java_gateway import java_import
jvm = spark._jvm
hconf = spark.sparkContext._jsc.hadoopConfiguration()
Path = jvm.org.apache.hadoop.fs.Path
p = Path(path_glob)
fs = p.getFileSystem(hconf)
stats = fs.globStatus(p)
return 0 if stats is None else len(stats)
print("profile matched:", glob_count(PROFILE_SRC_GLOB))
print("event matched: ", glob_count(EVENT_SRC_GLOB))
Step 3: Read raw data and write to Paimon ODS layer
Benefit: Paimon automatically manages file merging, indexing, and schema evolution—no manual Parquet partitioning required.
df_profile = spark.read.parquet(PROFILE_SRC_GLOB)
df_event = spark.read.parquet(EVENT_SRC_GLOB)
spark.sql("CREATE DATABASE IF NOT EXISTS game_db")
# Write to Paimon tables (ODS layer)
(df_profile.write
.format("paimon")
.mode("overwrite")
.saveAsTable("game_db.ods_user_profile"))
(df_event.write
.format("paimon")
.mode("overwrite")
.saveAsTable("game_db.ods_user_event"))
Step 4: Build the DWD detail data layer (Spark SQL ETL)
4.1 User detail table dwd_user_details
DROP TABLE IF EXISTS game_db.dwd_user_details;CREATE TABLE game_db.dwd_user_details
USING paimon
AS
WITH p AS (
SELECT
user_id,
decode(gender, 'UTF-8') AS gender,
decode(os_version, 'UTF-8') AS os_version,
CAST(decode(current_level, 'UTF-8') AS INT) AS current_level,
decode(device_type, 'UTF-8') AS device_type,
TO_DATE(decode(last_login_date, 'UTF-8')) AS last_login_date,
decode(favorite_game_mode, 'UTF-8') AS favorite_game_mode,
decode(language_preference, 'UTF-8') AS language_preference,
decode(active_time, 'UTF-8') AS active_time,
TO_DATE(decode(registration_date, 'UTF-8')) AS registration_date,
CAST(decode(total_deaths, 'UTF-8') AS INT) AS total_deaths,
CAST(decode(game_hours, 'UTF-8') AS DOUBLE) AS game_hours,
decode(location, 'UTF-8') AS location,
decode(play_frequency, 'UTF-8') AS play_frequency,
ROW_NUMBER() OVER (
PARTITION BY user_id
ORDER BY TO_DATE(decode(last_login_date, 'UTF-8')) DESC NULLS LAST
) AS rn
FROM game_db.ods_user_profile
)
SELECT * EXCEPT (rn)
FROM p
WHERE rn = 1; -- Deduplicate: Keep only the record with the latest last_login_date for each user_id4.2 User event detail table dwd_user_event
DROP TABLE IF EXISTS game_db.dwd_user_event;CREATE TABLE game_db.dwd_user_event
USING paimon
AS
WITH e AS (
SELECT
user_id,
LOWER(decode(event_type, 'UTF-8')) AS event_type,
TRIM(decode(timestamp, 'UTF-8')) AS ts_str,
decode(event_details, 'UTF-8') AS event_details,
decode(location, 'UTF-8') AS event_location
FROM game_db.ods_user_event
),
e_ts AS (
SELECT *,
CASE
WHEN ts_str RLIKE '^[0-9]{13}$' THEN TO_TIMESTAMP(FROM_UNIXTIME(CAST(ts_str AS BIGINT)/1000))
WHEN ts_str RLIKE '^[0-9]{10}$' THEN TO_TIMESTAMP(FROM_UNIXTIME(CAST(ts_str AS BIGINT)))
ELSE TO_TIMESTAMP(ts_str)
END AS event_ts
FROM e
)
SELECT
e.user_id,
e.event_ts,
TO_DATE(e.event_ts) AS event_date,
e.event_type,
COALESCE(NULLIF(e.event_location,''), d.location) AS location,
-- Extract amount from JSON
COALESCE(CAST(get_json_object(event_details, '$.amount') AS DOUBLE), 0.0) AS amount,
d.gender, d.device_type
FROM e_ts e
LEFT JOIN game_db.dwd_user_details d ON e.user_id = d.user_id
WHERE e.event_ts IS NOT NULL;Step 5: Build the ADS application data layer (metric aggregation)
5.1 Daily retention rate table ads_retention_daily
DROP TABLE IF EXISTS game_db.ads_retention_daily;CREATE TABLE game_db.ads_retention_daily
USING paimon
AS
WITH dau AS (
SELECT event_date AS dt, user_id
FROM game_db.dwd_user_event
GROUP BY event_date, user_id
)
SELECT
base.dt,
base.dau,
COALESCE(d1.d1_retained, 0) AS d1_retained,
ROUND(COALESCE(d1.d1_retained,0) * 1.0 / base.dau, 4) AS d1_retention_rate,
COALESCE(d7.d7_retained, 0) AS d7_retained,
ROUND(COALESCE(d7.d7_retained,0) * 1.0 / base.dau, 4) AS d7_retention_rate
FROM (
SELECT dt, COUNT(DISTINCT user_id) AS dau FROM dau GROUP BY dt
) base
LEFT JOIN (
SELECT a.dt, COUNT(DISTINCT a.user_id) AS d1_retained
FROM dau a JOIN dau b ON a.user_id = b.user_id AND b.dt = DATE_ADD(a.dt, 1)
GROUP BY a.dt
) d1 ON base.dt = d1.dt
LEFT JOIN (
SELECT a.dt, COUNT(DISTINCT a.user_id) AS d7_retained
FROM dau a JOIN dau b ON a.user_id = b.user_id AND b.dt = DATE_ADD(a.dt, 7)
GROUP BY a.dt
) d7 ON base.dt = d7.dt;5.2 Other ADS tables (see original code)
ads_purchase_trends_daily: Daily GMV and paying usersads_device_preference_daily: Device distribution and shareads_region_distribution_daily: Provincial and municipal DAU distribution
Step 6: Connect to StarRocks
Create a StarRocks node to query lake tables directly.
-- Query lake tables directly
SELECT * FROM paimon_catalog.game_db.ads_retention_daily LIMIT 10;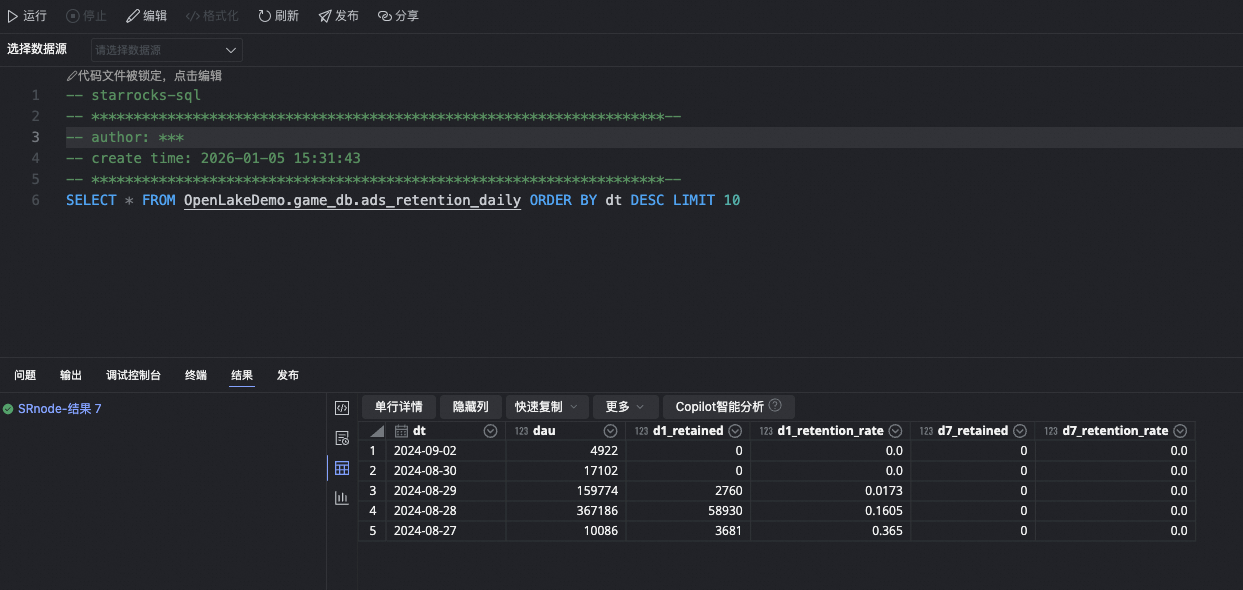
Step 7: Visualization (Quick BI)
In the Quick BI console, create a StarRocks data source.
Create new datasets with the following SQL:
Dataset SQL 1:
SELECT * FROM game_db.ADS_MV_USER_RETENTION;Dataset SQL 2:
SELECT * FROM game_db.ADS_MV_USER_GEOGRAPHIC_DISTRIBUTION;Dataset SQL 3:
SELECT * FROM game_db.ADS_MV_USER_DEVICE_PREFERENCE;Dataset SQL 4:
SELECT * FROM game_db.ADS_MV_USER_PURCHASE_TRENDS;
Build line charts, maps, dashboards, and other visualizations to monitor key metrics.
Summary of Solution Benefits
Dimension | Traditional approach | This solution |
Storage cost | High HDFS cost | Low-cost OSS + automatic small-file merging in Paimon |
Compute elasticity | Requires always-on clusters | EMR Serverless with pay-as-you-go billing |
Data consistency | Manual partition and version management | Paimon ACID + time travel |
Multi-engine collaboration | Data silos | Unified metadata in DLF—shared by Spark, Flink, and StarRocks |
Development efficiency | Complex scheduling dependencies | End-to-end ETL and SQL modeling in Notebook |