OpenSearch Retrieval Engine Edition is a large-scale distributed search engine developed by Alibaba. It powers the search services across the Alibaba Group, including Taobao, Tmall, Cainiao, Youku, and overseas e-commerce businesses, and underpins the OpenSearch service on Alibaba Cloud. Built for high availability (HA), real-time performance, and low cost, it includes a mature automated O&M system that lets you build search services tailored to your business needs.
Service architecture
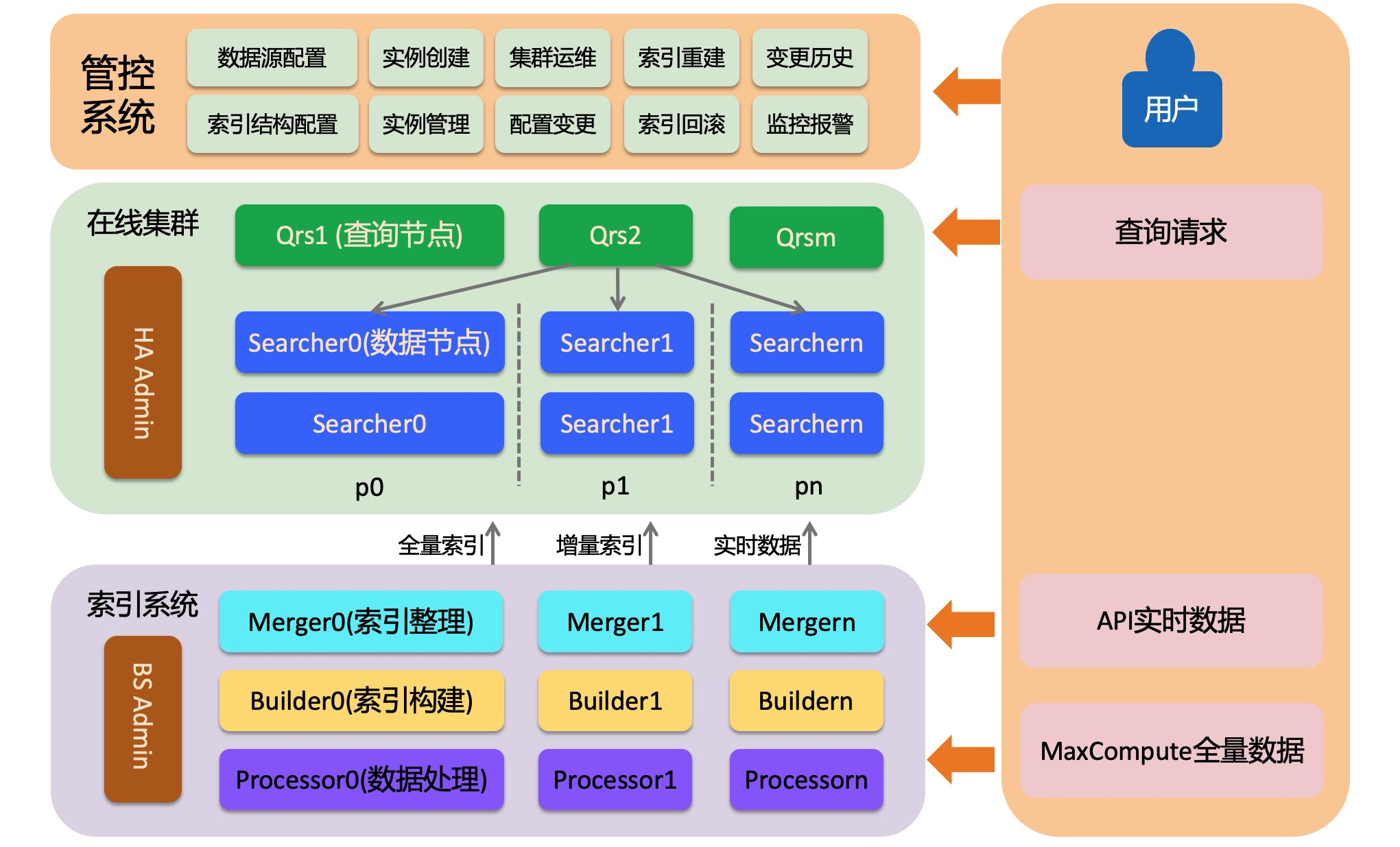
OpenSearch Retrieval Engine Edition consists of three parts: an online system, an offline index building system, and a control system. The online system loads indexes and serves retrieval requests. The offline system builds full, batch incremental, and real-time indexes from user data. The control system provides automated O&M and helps you create and manage clusters.
Online system
The online system is a distributed information retrieval system with three roles: admin, qrs, and searcher.
HA Admin
The HA Admin is the brain of the online system. Each physical cluster has at least one admin. It receives commands from the control system and sends O&M instructions to the Qrs and Searcher nodes. It also monitors these nodes in real time and automatically replaces any node whose heartbeat is abnormal.
Qrs (QRS worker)
A Qrs (QRS worker) is a query and result processing node. It parses, validates, or rewrites incoming queries, forwards them to the Searcher, and then collects, merges, and returns the results. QRS workers are compute-optimized and do not load user data, so they typically require little memory. Memory usage can increase, however, when many documents are returned or many statistical entries are generated. If QRS capacity becomes a bottleneck, you can add backup nodes or upgrade the node specifications.
Searcher (data node)
A Searcher loads user index data and retrieves documents based on queries, performing filtering, statistics, and sorting. Indexes on a Searcher can be sharded by hashing the sharding field to a value in the range [0, 65,535] and dividing that range into a specified number of shards (set during index building). Sharding improves single-request performance for clusters with large data volumes or strict latency requirements. To increase overall throughput — for example, from 1,000 QPS to 10,000 QPS — you can scale out by adding backup Searcher nodes that host all the data. The shards must cover the complete [0, 65,535] range.
Offline index building system
OpenSearch Retrieval Engine Edition uses read/write splitting, so data writes do not affect the online retrieval service. This ensures stable queries while supporting large-scale, real-time writes. The index building system has two flows — full and incremental — each involving three roles for data processing and index building.
Full flow
Indexes support multiple versions, each built from raw data (API data sources are empty by default). The first build runs a one-time full data processing job to generate a full index, which is then switched to the online cluster for retrieval. Subsequent incremental updates are applied to the new full index. Currently, full jobs can only read data from MaxCompute or Hadoop Distributed File System (HDFS) data sources.
Multiple index versions ensure stability during data modifications. When the index schema or data structure changes, a full build generates a new index completely isolated from the old version, allowing you to roll back promptly if issues arise.
Full index generation involves multiple stages — data processing, index building, and index merging. You can set the concurrency at each stage to increase generation speed.
Incremental flow
After a full index is generated, subsequent data updates are pushed through an API and handled by two pipelines. In one pipeline, a Processor pushes data directly to a data node to build a real-time index in memory. In the other, a Builder and a Merger create an incremental index that is applied to the data node through an incremental switch. During an incremental switch, the in-memory real-time index is cleared, and data already in the incremental index is removed from the real-time index to reduce memory pressure.
Each index table corresponds to an incremental flow, which is a long-running job. You can improve real-time data processing by adjusting the concurrency of each node in the flow.
Processor
A Processor handles raw documents by tokenizing or rewriting field content based on business logic. In an incremental flow, the Processor runs as a long-running distributed service whose concurrency you can adjust to improve throughput. The Processor also supports multiple data processing plugins. This feature is not yet publicly available. If you need it, contact us.
Builder
A Builder builds an index from processed documents. It runs alternately with the Merger — after each build, a Merger task organizes the index, and only the organized index is switched to the data node.
Merger
A Merger consolidates and organizes index data from the Builder into a more compact form. As data is updated, legacy indexes accumulate records marked for deletion. The Merger cleans up and merges this data according to a specified merge policy.
Index structure of Retrieval Engine Edition
|-- generation_0
|-- partition_0_32767
|-- index_format_version
|-- index_partition_meta
|-- schema.json
|-- version.0
|-- segment_0
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary
|-- segment_1
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary
|-- partition_32768_65535
|-- index_format_version
|-- index_partition_meta
|-- schema.json
|-- version.0
|-- segment_0
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary
|-- segment_1
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary|
Structure Name |
Description |
|
generation |
`generation_x` is an identifier that the engine uses to distinguish between different versions of a full index. |
|
partition |
A partition is the basic unit for a searcher to load an index. Too much data in one partition can degrade searcher performance. Online data is typically divided into multiple partitions to ensure the retrieval efficiency of each searcher. |
|
schema.json |
Index configuration file that records field, index, attribute, and summary information. The engine uses this file to load the index. |
|
version.0 |
Version file that records the segments to load in the current partition and the timestamp of the latest document. During a real-time build, the engine filters legacy raw documents based on the incremental version timestamp. |
|
segment |
A segment is the basic unit of an index. A segment contains the inverted and forward index structures of a document. The index builder generates a segment with each dump. Multiple segments can be merged based on a merge policy. The available segments in a partition are specified in the version file. |
|
segment_info |
Segment metadata that records the document count, merge status, locator information, and latest document timestamp. |
|
index |
Inverted index directory. |
|
attribute |
Forward index directory. |
|
deletionmap |
Deleted document records. |
|
summary |
Summary index directory. |
Control system
The control system is an O&M platform for Retrieval Engine Edition instances that significantly reduces O&M costs. For more information, see the Retrieval Engine Edition product documentation.
Product features
Stable
Built in C++ and refined over more than a decade, Retrieval Engine Edition has powered multiple core businesses and is proven to be highly stable — ideal for mission-critical search scenarios.
Efficient
As a distributed search engine, Retrieval Engine Edition efficiently retrieves massive datasets and supports real-time data updates that take effect in seconds — ideal for latency-sensitive search scenarios that require real-time data.
Low cost
Retrieval Engine Edition supports multiple index compression policies and multi-value index loading, helping you meet query requirements at a lower cost.
Rich features
Retrieval Engine Edition supports various analyzer types, multiple index types, and a powerful query syntax. It also provides a plugin mechanism that lets you customize your business processing logic.
SQL query
Retrieval Engine Edition supports SQL query syntax and online multi-table joins, with a rich set of built-in User-Defined Functions (UDFs) and a UDF customization mechanism. SQL Studio will soon be integrated into the O&M system to help you develop and test SQL queries.