Overview of Retrieval Engine Edition
Retrieval Engine Edition is a large-scale distributed search engine independently developed by Alibaba Cloud. Retrieval Engine Edition provides the search service for the entire Alibaba Group, including Taobao, Tmall, Cainiao, Youku, and overseas E-commerce business. Retrieval Engine Edition also supports OpenSearch services on Alibaba Cloud. After years of development, Retrieval Engine Edition has met the business requirements for high availability, high timeliness, and low costs. Retrieval Engine Edition also provides an automated O&M system on which you can build your own search service based on business features.
Architecture
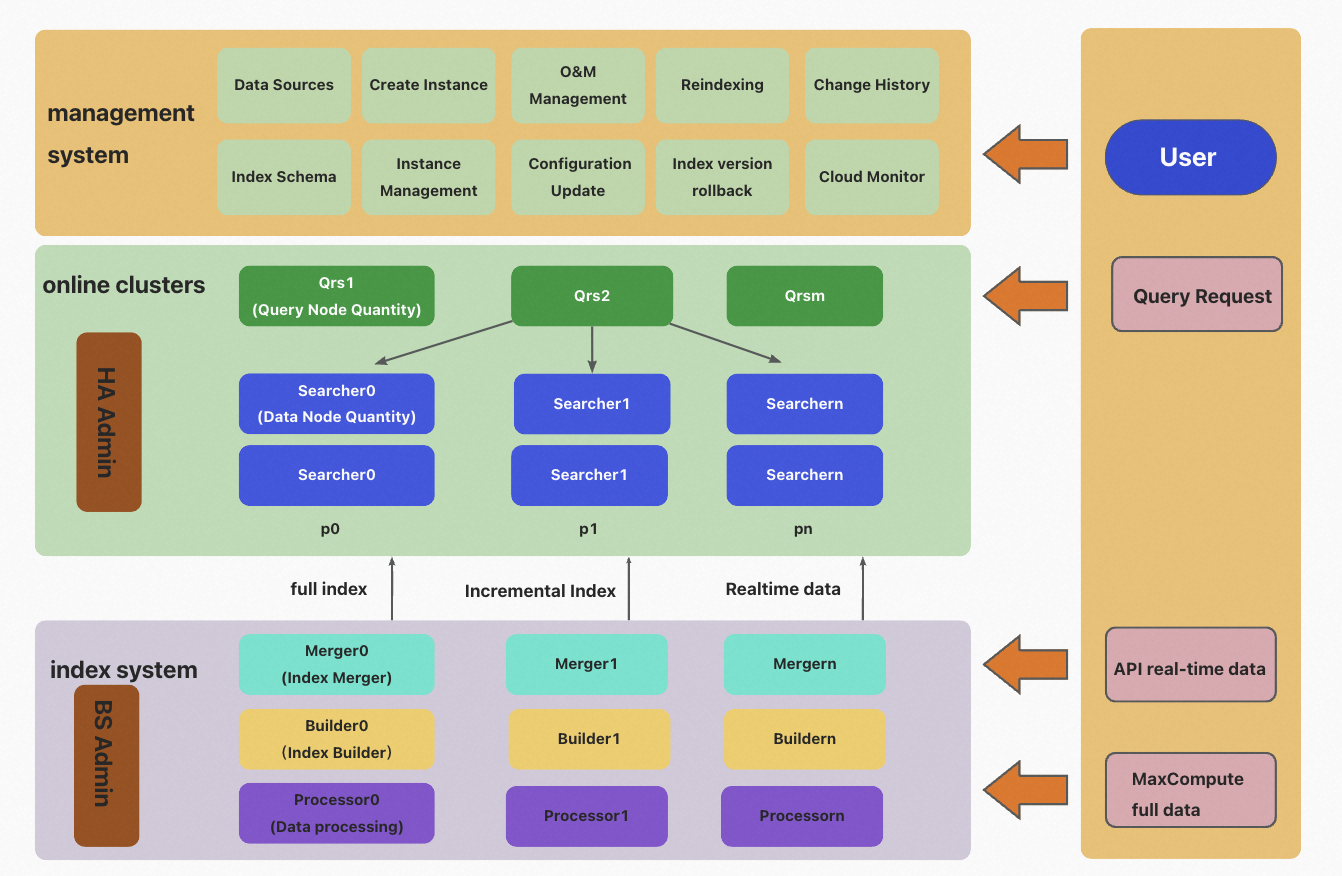
Retrieval Engine Edition consists of three main components: an online search system, an offline indexing system, and a management system. The online search system loads indexes and provides data retrieval services. The offline indexing system allows you to build indexes based on your business data, including full indexes, incremental indexes, and real-time data indexes. The management system provides automated O&M services that allow you to create clusters and manage clusters.
Online search system
The online search system is a system for distributed information retrieval. Three roles exist in the system: HA Admin, Query Result Searcher (QRS), and Searcher. The following content describes the roles:
HA Admin
HA Admin works as the brain of the online search system. Each physical cluster has at least one HA Admin. HA Admin receives requests from the management system and sends the corresponding O&M commands to QRS and Searcher workers. HA Admin also monitors the running status of QRS and Searcher workers in real time, and performs automatic failover when workers that have abnormal heartbeats are identified.
QRS workers
QRS workers are nodes for data queries or nodes that process queries and query results. QRS workers parse, verify, or rewrite query requests, forward the parsed requests to Searcher workers for execution, and then collect and merge the results returned by Searcher workers. Then, QRS workers return the query results that are processed. QRS workers are compute nodes that do not load user data and do not require much memory. The memory usage is high only when a large number of documents are returned or a large number of statistical entries are generated. If the processing capacity of QRS workers reaches a bottleneck, you can increase the number of QRS workers or upgrade the specifications of QRS workers.
Searcher workers
Searcher workers load the index data, retrieve documents based on queries, and filter, collect, and sort the documents. The indexes on the Searcher node can be sharded. You can split indexes into multiple shards and hash the fields in the shards to values in the range of [0, 65535]. You can specify the number of shards when you create indexes. If a cluster contains a large amount of data or requires high query performance, you can use sharding to improve the performance of a single query. If you want to improve the query performance of a cluster, for example, increase the QPS from 1,000 to 10,000, you can increase the number of replicas. You must increase the number of replicas for all Searcher workers instead of increasing the specifications of a single Searcher worker. This means that you must split data on all searcher workers into a specified number of shards. The hash values of the shards must constitute the complete range of [0, 65535].
Offline indexing system
Retrieval Engine Edition supports the read/write splitting feature. Data writes do not affect online retrieval. Therefore, Retrieval Engine Edition allows you to write a large amount of data in real time and ensures stable query performance. The offline indexing system builds indexes in two processes: full indexing and incremental indexing. In each process, three roles in the system work together to process data and build indexes.
Full indexing
Retrieval Engine Edition supports indexes of multiple versions. Each index version is built based on a copy of raw data. By default, the API data source is empty. The first time Retrieval Engine Edition starts to build indexes, full indexing is performed. Full indexing is a one-off job. The process ends when data is processed and a full index is generated. Then, the full index is applied to online clusters for data retrieval. Subsequent incremental data is updated to the index and a new index version is generated each time. Retrieval Engine Edition supports full data reads only from MaxCompute data sources and Hadoop Distributed File System (HDFS) data sources.
Indexes of multiple versions ensure data integrity despite multiple data changes. When the index schema or the data structure changes, the index of a new version is isolated from the indexes of earlier versions. In this case, if an error occurs on data changes, you can roll back the data to an earlier version.
Several steps are required to build full indexes, such as data processing, index building, and index merge. You can set the concurrency of index processing in each step to speed up full indexing.
Incremental indexing
After the full index is built, you must call API operations to push subsequent data updates. If you call API operations to push data, the data can be processed in the following two ways: After data is processed by a processor, the data is pushed to a Searcher worker and a real-time index is built in memory. The builder and the merger build an incremental index for the processed data, and the incremental index is applied to Searcher workers. When the incremental index is being applied to Searcher workers, real-time indexes in the memory are deduplicated and the incremental data is deleted from the memory. This helps reduce data in the memory of data nodes.
Incremental indexing is a routine job. Each index table corresponds to an incremental indexing process. You can set the concurrency of index processing for each worker to improve the processing of real-time data.
Processor
A processor is used to process the original documents, including tokenizing single words and rewriting the content in fields based on business logic. A processor provides a routine distributed service in the incremental indexing process. You can set the concurrency for a processor to improve data processing capabilities. Retrieval Engine Edition also allows you to configure data processing plug-ins for a processor. This feature is not available to the public. If you want to use this feature, contact Alibaba Cloud technical support.
Builder
A builder is used to build indexes based on processed documents. A builder does not run a routine job and it runs alternately with a merger. Each time an index is built, a merger starts to sort the index. Then, the index is applied to Searcher workers.
Merger
A merger is used to merge and sort the index data that is produced by a builder and make the index data neat and compact. When the index data is updated, indexes of earlier versions may contain a large amount of data that needs to be deleted. In this case, the merger cleans up and merges the data based on the specified index merge policy.
Index schema of Retrieval Engine Edition
|-- generation_0
|-- partition_0_32767
|-- index_format_version
|-- index_partition_meta
|-- schema.json
|-- version.0
|-- segment_0
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary
|-- segment_1
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary
|-- partition_32768_65535
|-- index_format_version
|-- index_partition_meta
|-- schema.json
|-- version.0
|-- segment_0
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary
|-- segment_1
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summaryItem | Description |
generation | The identifier that Retrieval Engine Edition uses to distinguish the versions of full indexes. |
partition | The basic unit for a Searcher worker to load indexes. If a partition contains an excessive amount of data, the performance of a Searcher worker decreases. You can split online data into multiple partitions to ensure the retrieval efficiency of each Searcher worker. |
schema.json | The configuration file that is used to configure indexes. The file contains information about fields, indexes, attributes, summaries, and others. Retrieval Engine Edition uses this file to load indexes. |
version.0 | The version number of the index file. This field contains the segment that Retrieval Engine Edition needs to load and the timestamp of the most recent document in the partition. When Retrieval Engine Edition builds indexes for real-time data, the system filters out the outdated original documents based on the timestamps in the incremental index. |
segment | The basic unit for an index. A segment stores data for inverted indexes and forward indexes. The builder generates a segment for each data dump. Segments can be merged based on merge policies. The segments that are available in a partition are displayed in the version field. |
segment_info | The summary information about segments. In this field, you can obtain information about the number of documents in the segment, whether the segment is merged, the locator information, and the timestamp of the most recent document. |
index | The inverted indexes. |
attribute | The forward indexes. |
deletionmap | The information about the documents that are deleted. |
summary | The directory of the summary index. |
Management system
The management system is an O&M platform for Retrieval Engine Edition. This platform helps you significantly reduce O&M costs. For more information, see Retrieval Engine Edition product documentation.
Characteristics of Retrieval Engine Edition
Stability
The underlying layer of Retrieval Engine Edition is developed by using the C++ programming language. After more than ten years of development, Retrieval Engine Edition provides stable search services for various core business systems. Retrieval Engine Edition is suitable for core search scenarios that require high stability.
Efficiency
Retrieval Engine Edition is a distributed search engine that allows you to retrieve large amounts of data. Retrieval Engine Edition supports real-time data updates. Data updates can take effect within seconds. Therefore, Retrieval Engine Edition is suitable for query and search scenarios that are time-sensitive.
Cost-effectiveness
Retrieval Engine Edition supports multiple policies for index compression and multi-value index loading tests, and can meet query requirements at low costs.
Rich features
Retrieval Engine Edition supports multiple types of analyzers and indexes, and various types of query syntax to meet your data retrieval requirements. Retrieval Engine Edition also supports plug-ins. This way, you can customize your own business logic.
SQL queries
Retrieval Engine Edition allows you to use SQL syntax and join tables online. Retrieval Engine Edition provides a variety of built-in user-defined functions (UDFs) and function customization mechanisms to meet different requirements for data retrieval. To facilitate SQL development and testing, an SQL studio will be integrated into the O&M system of Retrieval Engine Edition in later versions.