To repair an ECS instance with a damaged Linux system disk, use the OOS one-click repair feature.
Prerequisites
A RAM user is created with the AliyunOOSFullAccess, AliyunROSFullAccess, AliyunECSFullAccess, and AliyunVPCFullAccess policies attached. Create a RAM user, Policy overview.
Usage notes
Scenarios
An ECS instance with a damaged Linux system disk may appear as Running in the ECS console, but applications are inaccessible and the instance cannot be reached via ping, Workbench, or SSH. When you connect via VNC, you may see one of the following errors:
unexpected inconsistency;RUN fsck MANUALLYGive root password for maintenance (or type CTRL-D to continue)Enter 'help' for a list of built-in commands. (initramfs)
Possible causes:
-
Forced shutdown or restart.
-
Unexpected crash causing file system inconsistency.
-
A data disk was detached without removing its entry from /etc/fstab.
-
Missing or corrupted /etc/fstab file.
-
Corrupted initrd file.
-
Other file system damage.
Solution overview
This solution uses an OOS template tested by Alibaba Cloud for automated one-click repair. The template performs the following steps:
-
Create an image backup of the instance.
-
Detach the system disk and attach it to a temporary instance.
-
Check and repair the system disk on the temporary instance.
-
Reattach the repaired system disk to the original instance and try to restart it.
-
Release the temporary instance.
Supported operating systems
-
CentOS: 7.2 64-bit, 7.3 64-bit, 7.4 64-bit, 7.5 64-bit, 7.6 64-bit, 7.7 64-bit, and 8.0 64-bit
-
Debian: 8.9 64-bit, 8.11 64-bit, 9.8 64-bit, 9.9 64-bit, and 9.11 64-bit
-
openSUSE: 42.3 64-bit and 15.1 64-bit
-
SUSE Linux Enterprise Server: 12 SP4 64-bit and 12 SP2 64-bit
-
Alibaba Cloud Linux: 2.1903 64-bit
-
Ubuntu: 18.04 64-bit
This solution cannot repair all startup failures. A temporary instance is created during repair, incurring a fee typically less than USD 0.2. The solution modifies the fstab and initrd files. An image backup is automatically created before modification for data recovery. You are charged for the image backup. Snapshots. After repair, delete the backup to reduce costs.
Procedure
-
Log on to the CloudOps Orchestration Service console.
-
In the left-side navigation pane, choose . Search for the ACS-ECS-RescueUnreachableInstance-Linux template.
-
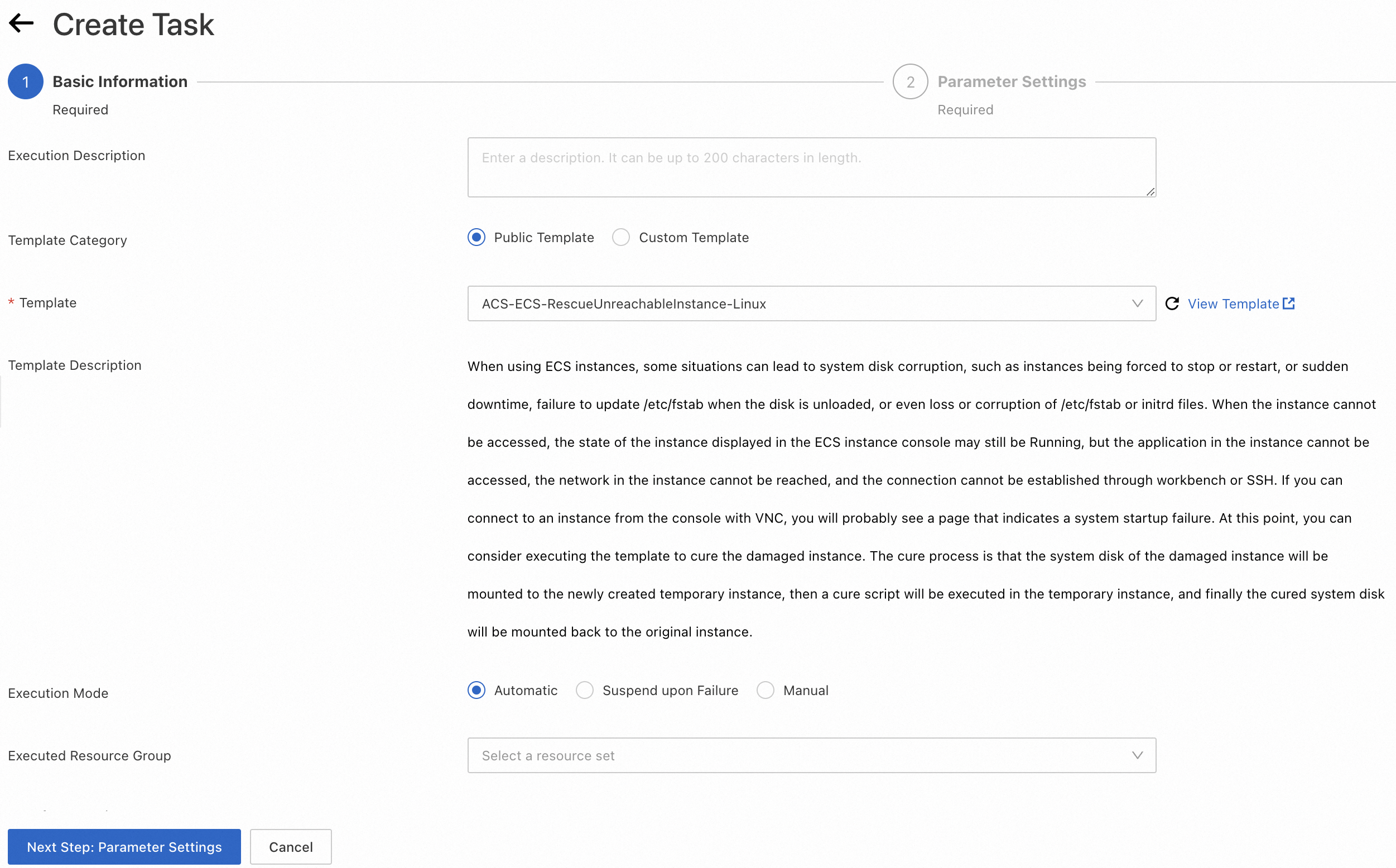
Click Create an execution.
-
Click Next Step: Parameter Settings.
-
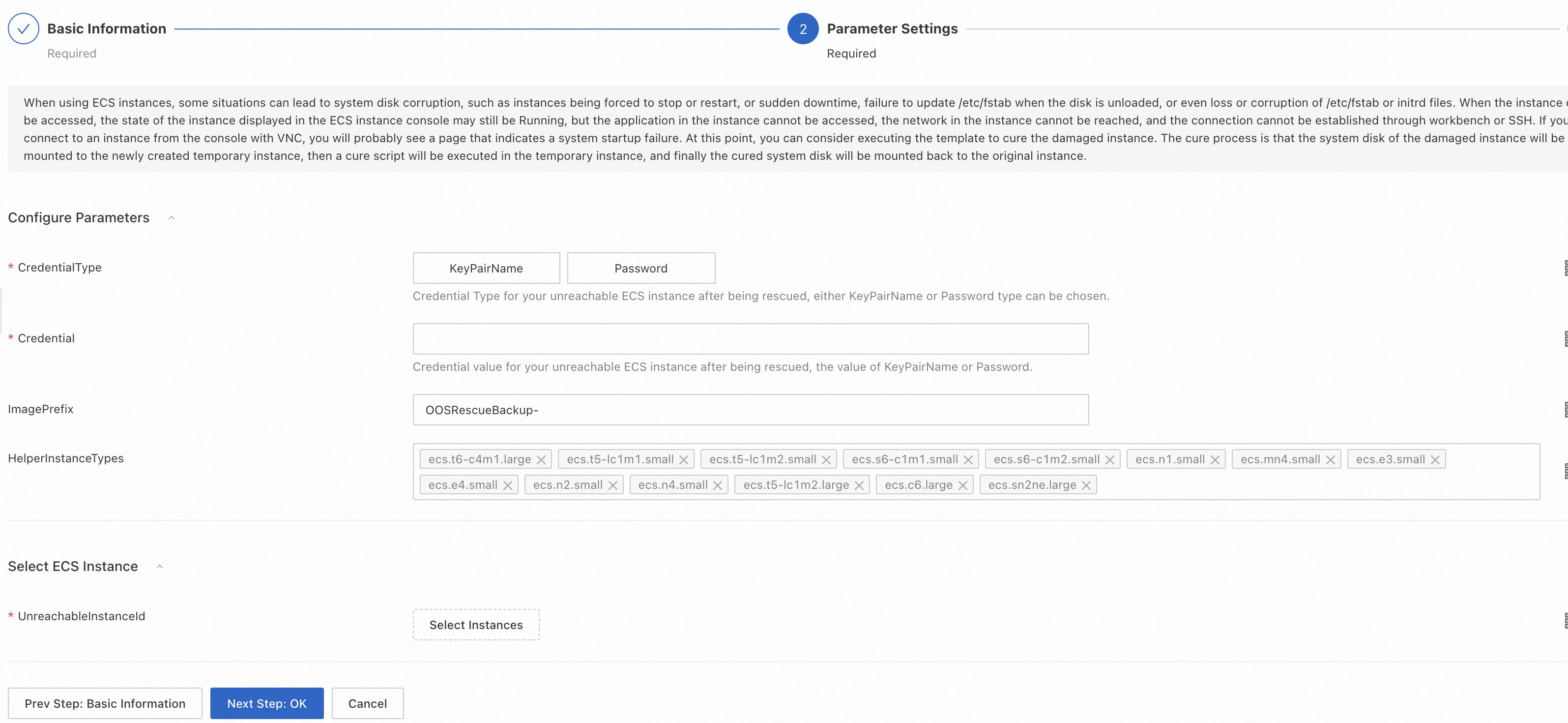
Set the following parameters:
-
UnreachableInstanceId: required. ID of the instance to repair.
-
CredentialType: required. Authentication type for reattaching the repaired disk. Valid values: KeyPairName, Password.
-
Credential: required. The key pair name or password, depending on CredentialType.
-
ImagePrefix: optional. Prefix for the backup image name. Default: OOSRescueBackup-.
-
HelperInstanceTypes: optional. Instance type for the temporary instance. Defaults to the lowest-priced type available.
-
OOSAssumeRole: Select Use Existing Permissions of Current Account.
-
-
Click Next Step: OK. In the OK step, click Create.

View the execution status on the details page, or check repair script output via the rtCommandOutput parameter. Execution takes 5 to 10 minutes. After successful execution, the instance is repaired and enters the Running state.
(Optional) Attach the system disk and repair the instance
Implementation logic
Repair the /etc/fstab file
-
Check if /etc/fstab exists. If it does, create a backup.
-
Repair /etc/fstab. If the file is missing or unparseable, create a default.
-
Add the nofail option if not set to prevent startup failures.
-
Disable fsck if enabled.
Update the ramdisk file
-
Check if the ramdisk file exists in /boot. If it does, create a backup.
-
Rebuild the ramdisk file.