ApsaraDB for MongoDB 4.4 was released in November 2020, making Alibaba Cloud the first cloud provider to offer MongoDB 4.4. MongoDB 4.4 was officially released on July 30, 2020. This version addresses the most requested improvements from previous releases, including index management, sharding flexibility, replication performance, and aggregation capabilities.
This topic describes each new feature, how it works, and how to enable it.
Hidden indexes
Dropping an index that turns out to be needed is costly — the index must be rebuilt, which takes time and resources. Hidden indexes let you evaluate the impact of removing an index without actually dropping it.
Alibaba Cloud and MongoDB jointly developed the hidden index feature as strategic partners.
Use the collMod command to hide an index:
db.runCommand({
collMod: "testcoll",
index: {
keyPattern: "key_1",
hidden: false
}
})The query planner ignores hidden indexes, so queries stop using them immediately. However, the index continues to be updated in the background, which means:
-
Unique index constraints and time to live (TTL) expiration remain active.
-
Unhiding the index makes it available immediately — no rebuild required.
If hiding the index causes no errors, the index can be safely dropped.
Refinable shard keys
| Version | Shard key behavior |
|---|---|
| 4.0 and earlier | Shard key and shard key value are immutable |
| 4.2 | Shard key value can be changed, but requires cross-shard data migration |
| 4.4 | Shard key can be extended with suffix fields using refineCollectionShardKey |
As workloads change, an initially well-chosen shard key can create hotspots. For example, a {customer_id: 1} shard key works well early on. As a major customer accumulates more orders, all queries for that customer route to a single shard, creating a hotspot. Changing customer_id alone cannot fix this because orders are tied to that field.
Use refineCollectionShardKey to add suffix fields to the existing shard key without migrating data:
db.adminCommand({
refineCollectionShardKey: "orders",
key: { customer_id: 1, order_id: 1 }
})The command modifies only the metadata on the config server. Data is redistributed gradually as chunks split or migrate. Before running the command, create an index that supports the new shard key.
Documents in a sharded collection can be missing the suffix fields added by refineCollectionShardKey. This is supported but can create jumbo chunks — use it only when necessary.
Compound hashed shard keys
| Version | Hashed index support |
|---|---|
| Earlier than 4.4 | Single-field hashed index only |
| 4.4 | Compound index with one hashed field as prefix or suffix |
Compound hashed indexes solve two sharding problems:
-
Zone compliance: Distribute data evenly across shards in a zone while still meeting geographic data residency requirements.
-
Monotonically increasing keys: A field like
customer_idthat increases monotonically routes all new writes to the same shard. Setting it as hashed distributes writes evenly.
Example — hash the customer_id field in a compound shard key:
sh.shardCollection(
"examples.orders",
{ customer_id: "hashed", order_id: 1 }
)Before compound hashed indexes, the workaround was to compute the hash value manually, store it in a dedicated field, and use ranged sharding on that field. This approach required extra application logic. Compound hashed indexes eliminate that workaround.
Hedged reads
Hedged reads reduce tail latencies (P95 and P99) in sharded clusters. When a read operation is issued, mongos routes it to two replica set members per queried shard and returns the result from whichever responds first.
Hedged reads are enabled per operation as part of the read preference setting. They are not supported when read preference is set to primary.
Step 1: Enable hedged reads on the mongos node.
db.adminCommand({ setParameter: 1, readHedgingMode: "on" })Step 2: Set per-operation read preference. If read preference is nearest, hedged reads are enabled automatically. For other modes (except primary), set hedgeOptions:
db.collection.find({}).readPref(
"secondary",
[{ datacenter: "B" }, {}],
{ enabled: true }
)P95 and P99 latency metrics represent the average latency for the slowest 5% and 1% of requests over the last 10 seconds.
Streaming replication
| Version | Replication mechanism |
|---|---|
| Earlier than 4.4 | Secondary polls primary using getMore (pull model) |
| 4.4 | Primary pushes a continuous oplog stream to secondaries (push model) |
In the polling model, each batch fetch requires a full round-trip time (RTT) between the primary and secondary. Each batch can be a maximum of 16 MB in size. Under high-latency network conditions, this degrades replication performance.
Streaming replication saves at least half the RTT per batch. This has two practical benefits:
-
`"majority"` writes: Under high-latency networks, streaming replication improves average performance for
"majority"write operations by 50%, because these writes wait for replication to multiple nodes. -
Causally consistent sessions: Reading your own writes from a secondary requires the secondary to have replicated the primary's oplog immediately. Streaming replication makes this reliable.
Simultaneous indexing
| Version | Index creation behavior |
|---|---|
| Earlier than 4.4 | Indexes created on primary first, then replicated to secondaries |
| 4.4 | Indexes created simultaneously on primary and all secondaries |
Creating indexes on the primary first and replicating them to secondaries introduces replication lag. CPU and I/O load during index creation, along with special operations like collMod, could block the oplog or push secondaries into a Recovering state.
Simultaneous indexing keeps secondaries in sync during the build. Secondaries can serve reads throughout the process. The index becomes usable only after a majority of voting members finish building it, which prevents read/write splitting scenarios from returning inconsistent results due to index differences.
Mirrored reads
After a failover, the newly elected primary starts with a cold cache. Incoming reads generate cache misses, and data must be reloaded from disk — causing a noticeable spike in latency until the cache warms up. This effect is most pronounced on instances with large memory.
Mirrored reads pre-warm secondary caches by having the primary mirror a subset of its read operations to electable secondaries. If a secondary is elected, its cache is already warm.
Mirrored reads are fire-and-forget: the primary does not wait for a response, so there is no impact on primary performance. Secondary workload increases.
Set the sampling rate with the mirrorReads parameter (default: 1%):
db.adminCommand({ setParameter: 1, mirrorReads: { samplingRate: 0.10 } })Check mirrored read statistics:
SECONDARY> db.serverStatus({ mirroredReads: 1 }).mirroredReads
// Example output:
// { "seen": NumberLong(2), "sent": NumberLong(0) }Resumable initial sync
| Version | Behavior on network interruption during initial sync |
|---|---|
| Earlier than 4.4 | Entire initial sync must restart from the beginning |
| 4.4 | Secondary attempts to resume; restarts only if resume fails within the retry period |
By default, a secondary attempts to resume for 24 hours. Use replication.initialSyncTransientErrorRetryPeriodSeconds to adjust the retry period or change the sync source.
If the network error is non-transient, the secondary must restart the full initial sync regardless.
Time-based oplog retention
The oplog is a capped collection that records all data-modifying operations. It is used for replication, incremental backup, data migration, and change stream consumers. Since MongoDB 3.6, replSetResizeOplog adjusts the oplog's maximum size in bytes — but there is no guarantee that a given time window of oplog entries is retained.
Time-based retention addresses scenarios such as:
-
A secondary is shut down for scheduled maintenance from 02:00 to 04:00. Without sufficient oplog retention, the primary may trigger a full sync when the secondary reconnects.
-
A change stream consumer goes offline for up to 3 hours. If the oplog rolls over during that window, the consumer cannot resume from where it left off.
Set the minimum retention period using storage.oplogMinRetentionHours:
// Check the current configured value
db.getSiblingDB("admin").serverStatus().oplogTruncation.oplogMinRetentionHours
// Set minimum retention to 2 hours
db.adminCommand({
replSetResizeOplog: 1,
minRetentionHours: 2
})$unionWith
| Stage | SQL equivalent | Sharded collection support |
|---|---|---|
$lookup |
LEFT OUTER JOIN |
Limited |
$unionWith |
UNION ALL |
Yes |
$unionWith combines the output of one collection's pipeline with the output of another. Multiple $unionWith stages can be chained to merge results across many collections.
Example: A business stores order data across three collections by month. To generate a quarterly sales report:
// Insert sample data
db.orders_april.insertMany([
{ _id: 1, item: "A", quantity: 100 },
{ _id: 2, item: "B", quantity: 30 }
]);
db.orders_may.insertMany([
{ _id: 1, item: "C", quantity: 20 },
{ _id: 2, item: "A", quantity: 50 }
]);
db.orders_june.insertMany([
{ _id: 1, item: "C", quantity: 100 },
{ _id: 2, item: "D", quantity: 10 }
]);
// Aggregate across all three collections
db.orders_april.aggregate([
{ $unionWith: "orders_may" },
{ $unionWith: "orders_june" },
{ $group: { _id: "$item", total: { $sum: "$quantity" } } },
{ $sort: { total: -1 } }
])Expected output:
[
{ _id: "A", total: 150 },
{ _id: "C", total: 120 },
{ _id: "B", total: 30 },
{ _id: "D", total: 10 }
]Before $unionWith, aggregating across collections required reading all data at the application layer or using a data warehouse.
Each $unionWith stage also accepts a pipeline parameter, letting you filter or transform each collection's data before combining.
Custom aggregation expressions
| Approach | Limitation |
|---|---|
$where operator |
Cannot use aggregation pipeline |
| MapReduce | Cannot use aggregation pipeline |
$accumulator / $function (4.4) |
Runs inside the aggregation pipeline |
MongoDB 4.4 adds two operators that let you define custom JavaScript logic inside an aggregation pipeline.
$accumulator — works similarly to MapReduce. Use it to aggregate data across documents with custom state management:
-
init: initializes state for each group. -
accumulate: updates state for each document. -
merge: combines states when running on sharded collections. -
finalize(optional): transforms the merged state into the final result.
$function — works similarly to $where but integrates with other pipeline stages. Use it with $expr in a find command for a direct equivalent to $where.
{ $accumulator: {
init: function() { return { count: 0, sum: 0 }; },
accumulate: function(state, value) {
return { count: state.count + 1, sum: state.sum + value };
},
accumulateArgs: ["$price"],
merge: function(s1, s2) {
return { count: s1.count + s2.count, sum: s1.sum + s2.sum };
},
finalize: function(state) { return state.sum / state.count; },
lang: "js"
} }New aggregation pipeline operators
In addition to $accumulator and $function, MongoDB 4.4 introduces the following operators:
| Operator | Description |
|---|---|
$accumulator |
Returns the result of a user-defined accumulator |
$binarySize |
Returns the size of a string or binary object, in bytes |
$bsonSize |
Returns the size of a BSON-encoded document, in bytes |
$first |
Returns the first element in an array |
$function |
Defines a custom aggregation expression in JavaScript |
$last |
Returns the last element in an array |
$isNumber |
Returns true if the expression is an integer, decimal, double, or long; returns false for other BSON types, null, or missing fields |
$replaceOne |
Replaces the first occurrence of a matched string |
$replaceAll |
Replaces all occurrences of a matched string |
Connection monitoring and pooling
MongoDB 4.4 standardizes the API for configuring and monitoring connection pools through drivers. Subscribe to connection pool events — including connections opening and closing, and pool clearing — using a standard event API.
Configurable pool options include:
-
Maximum and minimum number of connections
-
Maximum time a connection can remain idle
-
Maximum time a thread waits for an available connection
For the full list of options, see Connection pool options.
Global read and write concerns
| Version | Default read/write concern behavior |
|---|---|
| Earlier than 4.4 | readConcern: local, writeConcern: {w: 1} — fixed, not configurable |
| 4.4 | Global defaults configurable with setDefaultRWConcern |
Set global defaults with setDefaultRWConcern:
db.adminCommand({
setDefaultRWConcern: 1,
defaultWriteConcern: { w: "majority" },
defaultReadConcern: { level: "majority" }
})Retrieve current global defaults with getDefaultRWConcern:
db.adminCommand({ getDefaultRWConcern: 1 })MongoDB 4.4 also logs the provenance of each read or write concern in slow query and diagnostic logs:
| Provenance | Description |
|---|---|
clientSupplied |
Specified in the application |
customDefault |
Set via setDefaultRWConcern |
implicitDefault |
Server default, applied when no other concern is specified |
getLastErrorDefaults |
(Write concern only) Originates from the replica set's settings.getLastErrorDefaults field |
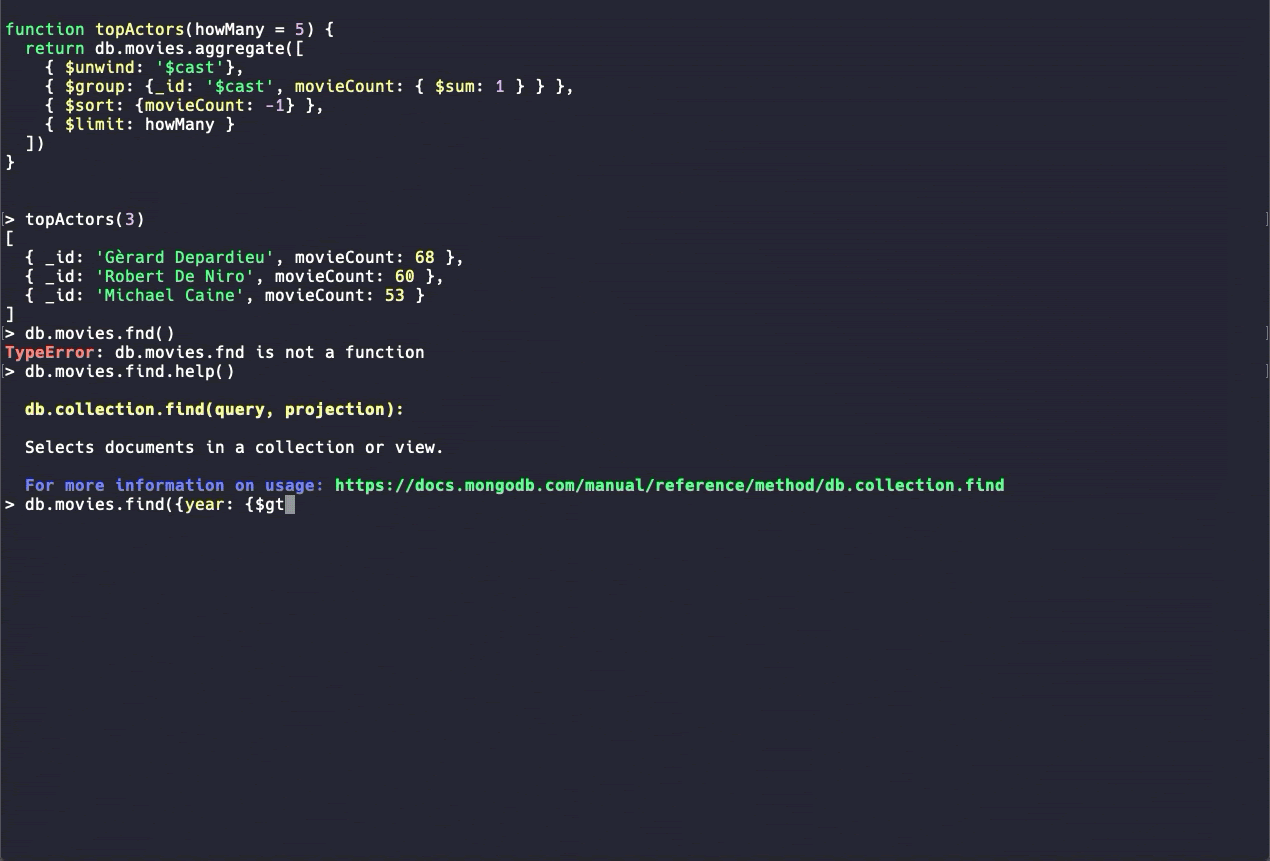
New MongoDB Shell (beta)
MongoDB 4.4 ships with a new MongoDB Shell that improves the developer experience with:
-
Syntax highlighting
-
Command autocomplete
-
Clearer error messages
The new shell is in beta. Use it for exploration and testing rather than production scripts while additional commands are being developed.
Summary
MongoDB 4.4 is a maintenance release focused on reliability, operational flexibility, and developer productivity. Beyond the features described above, it includes:
-
Optimization of the
$indexStatsaggregation operator -
TCP Fast Open (TFO) connection support
-
Index deletion optimization
-
Structured logging (
logv2) -
New authentication mechanisms
For the complete list of changes, see Release notes for MongoDB 4.4.