The Assistant API helps developers build model applications like personal assistants, smart shopping guides, and meeting assistants. Unlike the text generation API, the Assistant API has built-in dialogue management and tool calling, reducing development effort.
What is an assistant
An assistant is a type of AI conversational assistant characterized by:
-
Multiple models: Configure your assistant with any foundational model and customize its personality and capabilities using system instructions.
-
Tool calling: Use official tools like Python code interpreter or custom tools via function calling.
-
Conversation management: Thread objects store message history and truncate it when exceeding the model's context length. Create a thread once, then append messages as users respond.
To experience an assistant, create an agent application in the console (no coding required). For programmatic access, see Get started with Assistant API for step-by-step integration guidance.
Agent applications and assistants are both LLM applications with different features and management methods (create, read, update, delete).
-
Agent application: Designed to be no-code or low-code. Can be managed only in the console.
-
Assistant: Designed to be pure-code. Can be managed only through the Assistant API.
Differences from the text generation API
The text generation API's primary element is messages generated by models like Qwen-Plus and Qwen-Max. This lightweight API requires manual management of conversation state, tool definitions, knowledge retrieval, and code execution to build applications.
On top of the text generation API, the Assistant API introduces the following core elements:
-
Message objects: Store conversation role and content (similar to text generation API messages).
-
Assistant objects: Bundle a foundational model, instructions, and tools.
-
Thread objects: Represent the current conversation status.
-
Run objects: Execute the assistant on a thread, including text responses and tool calls.
The following sections explain how these elements work together.
Interaction method
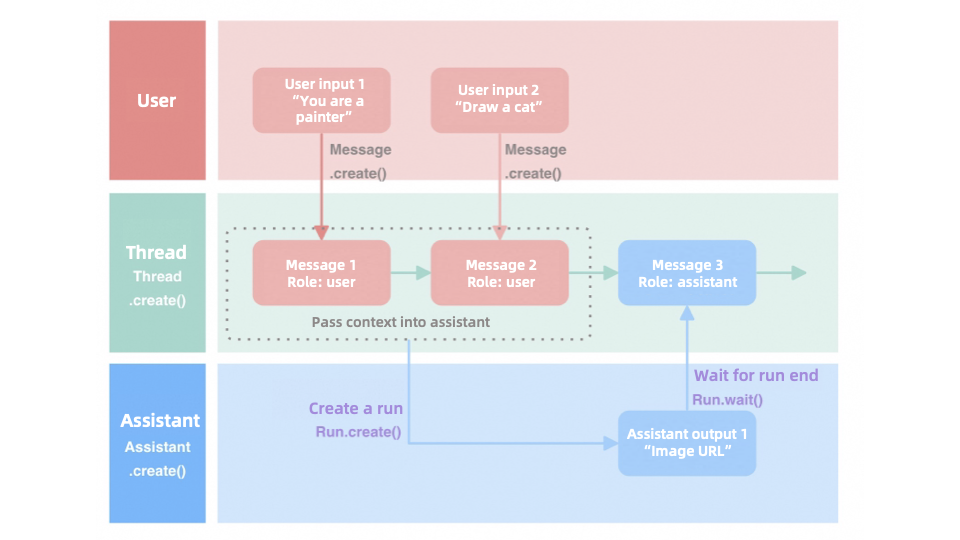
The Assistant API uses threads to process messages sequentially, preserving conversation continuity. The process is as follows:
-
Create a message: Create a message with
Message.create()and assign it to a thread to maintain context. -
Initialize a run:
Run.create()initializes the assistant runtime for message processing. -
Wait for results:
wait()pauses until the assistant completes processing and returns results.
Consider a simple drawing assistant as an example:
|
Model support
For model compatibility, see the execution results or refer to Models.
Tool support
For plug-in compatibility, see the execution results or refer to Plug-in.
|
Tool |
Identifier |
Description |
|
Python code interpreter |
code_interpreter |
Execute Python code for programming tasks, math, and data analysis. |
|
Image generation |
text_to_image |
Transform text descriptions into images to diversify response formats. |
|
Custom plug-in |
${plugin_id} |
Integrate custom business interfaces to extend AI capabilities. |
|
Function calling |
function |
Execute functions on local devices without requiring external network services. |
Get started
To test LLMs or get started with the Assistant API:
-
Playground: Test the inference capabilities of LLMs to find the most suitable one for your assistant.
-
Quick Start: Basic usage and examples to help you get started.
-
API references: Parameter details for resolving development challenges.