The Milvus Embedding service provides built-in vectorization. Pass raw text, images, or videos during data ingestion and search — Milvus generates vectors automatically, with no separate inference service required.
Feature overview
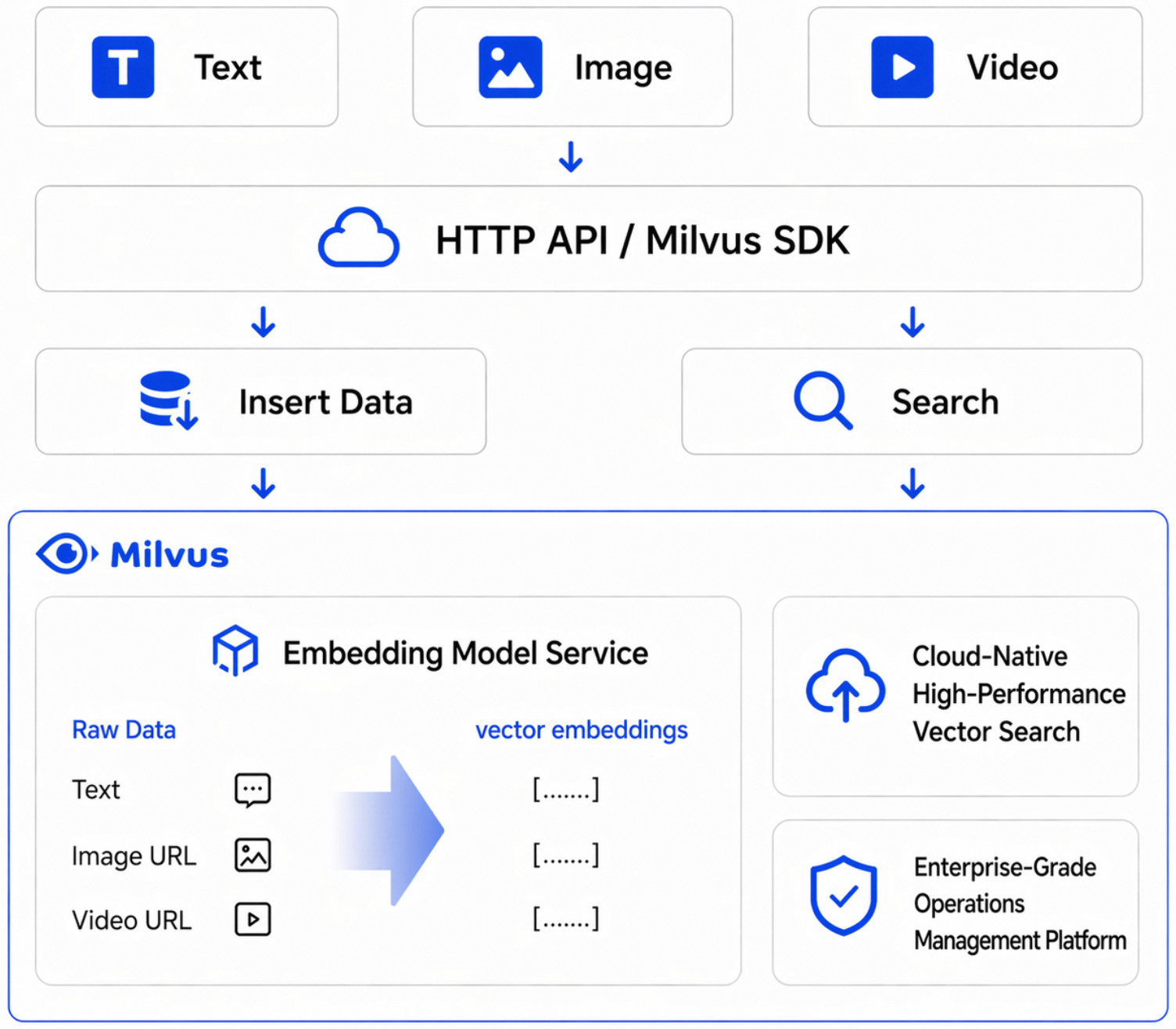
|
Feature |
Description |
|
Centralized console management |
Enable and configure the Embedding service and bind it to an instance from the console. |
|
Managed model capabilities |
Managed Embedding service with no need to deploy your own inference pipeline. |
|
Direct ingestion and search of raw data |
Pass raw text or multimodal content during inserts, updates, and queries. The system vectorizes automatically. |
|
Multiple model support |
Select and switch between multiple Embedding models to match your workload. |
|
Invocation and token statistics |
Provides instance-level statistics for invocations and token usage. |
|
Monitoring and alerts |
Configure alerts for QPS, success rate, and response time (RT). |
Procedure
Enable the Embedding service
In the Milvus console, select AI Center in the left navigation. On the Embedding Service page, click Enable Embedding.
After activation, the following models are available:
-
text-embedding-v4: Multilingual text embedding based on Qwen3. Supports custom dimensions from 64 to 2048.
-
text-embedding-v3: General-purpose text embedding model.
-
text-embedding-v2: General-purpose text embedding model.
-
qwen3-vl-embedding: Multimodal embedding model for text, image, and video input.
The Embedding service is region-specific. Enable it separately in each region you use.
Associate a Milvus instance
Embedding requires a Milvus 2.6 instance. Associate one in either of these ways:
-
Enable Embedding when creating a 2.6 cluster.
-
Go to AI Center to enable Embedding for an existing 2.6 instance.
In the Embedding list, click Batch Enable next to the target Service ID. In the Batch Enable dialog box, select the instances.
View invocation metrics
Go to AI Center. On the Embedding page, click View Call Information for the target model to view these metrics:
-
Token Usage Overview: The trend of total token consumption.
-
QPS: The number of requests per second.
-
Success Rate: The request success rate.
-
Token Usage/s: The number of tokens consumed per second.
-
Average RT: The average response time.
Filter by instance ID, time range, or sampling interval.
Example 1: Text-to-text semantic search
Scenario
Ingest raw text without pre-generating vectors. At query time, pass a natural language question — Milvus vectorizes it and returns the most semantically relevant results. Applicable to knowledge base Q&A, document search, and FAQ retrieval.
Procedure
-
Create a collection and define a raw text field
documentand a vector fielddense. -
Bind the
text-embedding-v4model by using aFunction. -
Insert test text data.
-
Perform a search by using a natural language question and retrieve the most relevant text segments.
Sample code
import random
from pymilvus import MilvusClient, DataType, Function, FunctionType
client = MilvusClient(
uri="http://c-xxxx.milvus.aliyuncs.com:19530",
token='root:xxx',
)
# ========== Create a collection ==========
collection_name = 'demo1'
schema = client.create_schema()
schema.add_field("id", DataType.INT64, is_primary=True, auto_id=False)
schema.add_field("document", DataType.VARCHAR, max_length=9000)
schema.add_field("dense", DataType.FLOAT_VECTOR, dim=1024)
text_embedding_function = Function(
name="dashscope_api_test123",
function_type=FunctionType.TEXTEMBEDDING,
input_field_names=["document"],
output_field_names=["dense"],
params={
"provider": "aliyun_milvus",
"model_name": "text-embedding-v4"
}
)
schema.add_function(text_embedding_function)
index_params = client.prepare_index_params()
index_params.add_index(
field_name="dense",
index_type="AUTOINDEX",
metric_type="COSINE"
)
client.drop_collection(collection_name)
client.create_collection(
collection_name=collection_name,
schema=schema,
index_params=index_params
)
insert_data = []
record_id = 1
mock_texts = [
"A vector database converts text into high-dimensional vectors for semantic search, understanding the true intent of queries.",
"Deep learning models learn feature representations from large image datasets for tasks such as image classification and object detection.",
"Retrieval-augmented generation recalls relevant documents to provide external knowledge for large language models, reducing hallucinations and improving answer reliability.",
"In customer service scenarios, semantic search can quickly locate historical tickets, improving first-response efficiency and resolution rates.",
"Similarity search commonly uses cosine distance to measure vector direction proximity, suitable for text semantic matching tasks.",
"Data cleaning is a critical step before vectorization; denoising and format standardization significantly improve recall quality.",
"Higher embedding dimensions are not always better; you need to balance effectiveness, latency, and storage cost.",
"Chunking strategies that split long documents into small segments can improve search hit rates and reduce context redundancy.",
"Adding a source field to each piece of knowledge aids result explainability, making it easy to display citation evidence on the frontend.",
"Multilingual search leverages a unified vector space for cross-language matching, enhancing the experience of internationalized systems.",
"Index parameters such as ef and M affect the recall rate and query performance of HNSW and need to be tuned based on your business requirements.",
"Running offline evaluations before going live can quantify differences in search quality across different models and parameter combinations.",
"Metadata filtering in a vector database can be combined with semantic recall for more precise scoped search.",
"For high-frequency queries, caching search results briefly can reduce backend computation pressure and response time.",
"A semantic search pipeline should log queries to facilitate analysis of zero-result queries and continuous optimization of the knowledge base.",
"When knowledge content updates frequently, incremental indexing strategies can reduce the resource consumption of full rebuilds.",
"Adding a reranking model in a Q&A system can improve the relevance and readability of the top results.",
"Establishing access control policies for sensitive data is a fundamental security requirement for enterprise-grade vector search systems.",
"Setting topK appropriately balances coverage and noise, avoiding the return of too many low-relevance results.",
"Feeding user feedback back into the training and evaluation pipeline can continuously improve overall search and Q&A performance.",
]
for text in mock_texts:
insert_data.append({
"id": record_id,
"document": text,
})
record_id += 1
BATCH_SIZE = 30
print(f"Preparing to insert {len(insert_data)} records, batch_size={BATCH_SIZE}...")
for batch_start in range(0, len(insert_data), BATCH_SIZE):
batch = insert_data[batch_start:batch_start + BATCH_SIZE]
client.insert(collection_name, batch)
print(f" Inserted {min(batch_start + BATCH_SIZE, len(insert_data))}/{len(insert_data)} records")
print("Data insertion complete!\n")
# ========== Test 1: Text-to-text search (semantic search via the dense field) ==========
print("=" * 60)
print("Test 1: Text-to-text search - query content related to vector databases")
print("=" * 60)
results = client.search(
collection_name=collection_name,
data=['What is semantic search? How does a vector database work?'],
anns_field='dense',
limit=3,
output_fields=['document'],
)
for hits in results:
for hit in hits:
print(f" id={hit['id']}, distance={hit['distance']:.4f}, document={hit['entity']['document'][:80]}")Output
Preparing to insert 20 records, batch_size=30...
Inserted 20/20 records
Data insertion complete!
============================================================
Test 1: Text-to-text search - query content related to vector databases
============================================================
id=1, distance=0.8197, document=A vector database converts text into high-dimensional vectors for semantic search, understanding the true intent of queries.
id=13, distance=0.6906, document=Metadata filtering in a vector database can be combined with semantic recall for more precise scoped search.
id=18, distance=0.6563, document=Establishing access control policies for sensitive data is a fundamental security requirement for enterprise-grade vector search systems.Example 2: Multimodal search
Scenario
In retail, e-commerce, and content platforms, search targets include images and videos alongside text. The Milvus Embedding service unifies text and visual content in a single vectorization pipeline, enabling cross-modal search: text-to-image/video and image-to-image/video.
Download the images for this example from here.
Procedure
-
Upload local test images or videos to OSS and generate accessible signed URLs.
-
Create a collection and define a text field
document, a multimedia URL fieldurl, a text vector fielddense, and a multimodal vector fielddense_mm. -
Bind
text-embedding-v4andqwen3-vl-embeddingto the text field and the multimedia field, respectively. -
Insert test media assets and their corresponding text descriptions.
-
Perform search verification for text-to-text, text-to-image/video, and image-to-image/video searches.
Sample code
import glob
import os
import random
import oss2
from pymilvus import MilvusClient, DataType, Function, FunctionType
client = MilvusClient(
uri="http://c-xxxx.milvus.aliyuncs.com:19530",
token='root:xxx',
)
# ========== OSS configuration: upload multimedia resources and generate signed URLs ==========
SCRIPT_DIR = os.path.dirname(os.path.abspath(__file__))
OSS_ACCESS_KEY_ID = os.environ['OSS_ACCESS_KEY_ID']
OSS_ACCESS_KEY_SECRET = os.environ['OSS_ACCESS_KEY_SECRET']
OSS_ENDPOINT = 'https://oss-cn-hangzhou.aliyuncs.com'
OSS_BUCKET_NAME = '002test'
auth = oss2.Auth(OSS_ACCESS_KEY_ID, OSS_ACCESS_KEY_SECRET)
bucket = oss2.Bucket(auth, OSS_ENDPOINT, OSS_BUCKET_NAME)
def upload_and_sign(relative_path, oss_key_prefix="milvus-embedding-test"):
"""Upload a local multimedia resource to OSS and return a signed URL (valid for 1 hour)"""
full_path = os.path.join(SCRIPT_DIR, relative_path)
oss_key = f"{oss_key_prefix}/{os.path.basename(relative_path)}"
bucket.put_object_from_file(oss_key, full_path)
signed_url = bucket.sign_url('GET', oss_key, 3600)
print(f" Upload successful: {oss_key} -> {signed_url[:80]}...")
return signed_url
def upload_directory_with_patterns(
directory_relative_path,
patterns,
oss_key_prefix="milvus-embedding-test",
random_pick_count=None,
):
"""Upload multimedia files matching the given suffixes from a directory to OSS, return {filename: signed_url}"""
full_dir = os.path.join(SCRIPT_DIR, directory_relative_path)
matched_files = []
for pattern in patterns:
matched_files.extend(glob.glob(os.path.join(full_dir, pattern)))
matched_files = sorted(set(matched_files))
if random_pick_count is not None and len(matched_files) > random_pick_count:
matched_files = random.sample(matched_files, random_pick_count)
result = {}
for file_path in matched_files:
filename = os.path.basename(file_path)
relative_path = os.path.join(directory_relative_path, filename)
signed_url = upload_and_sign(relative_path, oss_key_prefix)
result[filename] = signed_url
return result
# Upload test assets from the banana and orange directories to OSS
print("Uploading test assets to OSS...")
banana_urls = upload_directory_with_patterns("qwen-vl/train/banana", ["*.JPEG"])
orange_urls = upload_directory_with_patterns("qwen-vl/train/orange", ["*.JPEG"])
print(f"Uploaded {len(banana_urls)} images from the banana directory, {len(orange_urls)} images from the orange directory")
print("Image asset upload complete!\n")
# Upload videos to OSS (same logic as image assets)
print("Uploading videos to OSS...")
selected_video_urls = upload_directory_with_patterns(
"qwen-vl/short_video_10_of_42",
["*.mp4", "*.MP4", "*.mov", "*.MOV"],
random_pick_count=5,
)
print(f"Uploaded and selected {len(selected_video_urls)} videos from the short_video_10_of_42 directory")
print("Video upload complete!\n")
banana_url_list = list(banana_urls.values())
orange_url_list = list(orange_urls.values())
selected_video_url_list = list(selected_video_urls.values())
# ========== Create a collection ==========
collection_name = 'demo11'
schema = client.create_schema()
schema.add_field("id", DataType.INT64, is_primary=True, auto_id=False)
schema.add_field("document", DataType.VARCHAR, max_length=9000)
schema.add_field("url", DataType.VARCHAR, max_length=9000)
schema.add_field("dense", DataType.FLOAT_VECTOR, dim=1024)
schema.add_field("dense_mm", DataType.FLOAT_VECTOR, dim=1024)
text_embedding_function = Function(
name="dashscope_api_test123",
function_type=FunctionType.TEXTEMBEDDING,
input_field_names=["document"],
output_field_names=["dense"],
params={
"provider": "aliyun_milvus",
"model_name": "text-embedding-v4"
}
)
mm_embedding_function = Function(
name="dashscope_api_mm123",
function_type=FunctionType.TEXTEMBEDDING,
input_field_names=["url"],
output_field_names=["dense_mm"],
params={
"provider": "aliyun_milvus",
"model_name": "qwen3-vl-embedding",
"dim": "1024"
}
)
schema.add_function(text_embedding_function)
schema.add_function(mm_embedding_function)
index_params = client.prepare_index_params()
index_params.add_index(
field_name="dense",
index_type="AUTOINDEX",
metric_type="COSINE"
)
index_params.add_index(
field_name="dense_mm",
index_type="AUTOINDEX",
metric_type="COSINE"
)
client.drop_collection(collection_name)
client.create_collection(
collection_name=collection_name,
schema=schema,
index_params=index_params
)
# ========== Insert Chinese test data, multimedia resources use OSS signed URLs ==========
banana_descriptions = [
'A bunch of ripe yellow bananas hanging from a tree in a tropical orchard, with sunlight casting dappled shadows through the leaves.',
'Neatly arranged bananas in the supermarket fruit section, with a price tag showing today\'s special, attracting many customers.',
'A few bananas and a glass of milk on the kitchen table, a simple and healthy breakfast combination.',
'Freshly picked green bananas neatly stacked in a bamboo basket, waiting to ripen naturally before going to market.',
'A child holding a banana, happily walking and eating in the park, face beaming with satisfaction.',
'A baker mashing overripe bananas to make a classic banana cake, the kitchen filled with a sweet aroma.',
'Wild banana trees growing in clusters in the tropical rainforest, their large leaves gently swaying in the breeze.',
'Sliced bananas on the breakfast table paired with oatmeal and yogurt, a nutritionally balanced healthy breakfast.',
'A fruit vendor weighing a large bunch of fresh bananas for a customer, the scale showing exactly three jin.',
'A few bananas displayed alongside apples and oranges in a fruit bowl, colorful and pleasing to the eye.',
]
orange_descriptions = [
'Oranges hanging from branches in the orchard gleam golden in the sunlight, a joyful harvest season.',
'A glass of freshly squeezed orange juice on the table, with cut oranges beside it, the flesh plump and juicy.',
'Mom is peeling oranges in the kitchen, the air filled with a fresh citrus fragrance, as the children gather around waiting to eat.',
'Navel oranges and blood oranges neatly lined up on supermarket shelves, each variety with its own distinctive characteristics.',
'On a winter afternoon, a plate of sliced oranges on the coffee table is the whole family\'s favorite afternoon tea fruit.',
'Grandma skillfully dries orange peels in the sun for tea, said to help regulate qi and strengthen the spleen.',
'A fruit farmer carefully packs freshly picked oranges into cardboard boxes, ready to ship to customers across the country.',
'The dessert shop window displays an exquisite orange mousse cake, its orange appearance very tempting.',
'An orange cut in half reveals tender flesh, rich with juice, making one\'s mouth water.',
'The fruit shop at the neighborhood entrance displays a sign announcing the arrival of Gannan navel oranges, attracting many residents to queue up.',
]
video_descriptions = [
"A short fruit-themed video showing orchard picking and transportation.",
"A short video of a fruit store display, with close-up shots of the fruit details.",
"A short beverage-making video including slicing, pressing, and pouring into a glass.",
"A short dessert-making video showing fruit decoration and the finished product.",
]
insert_data = []
record_id = 1
for idx, img_url in enumerate(banana_url_list):
insert_data.append({
'id': record_id,
'document': banana_descriptions[idx],
'url': img_url,
})
record_id += 1
for idx, img_url in enumerate(orange_url_list):
insert_data.append({
'id': record_id,
'document': orange_descriptions[idx],
'url': img_url,
})
record_id += 1
for idx, video_url in enumerate(selected_video_url_list):
insert_data.append({
"id": record_id,
"document": video_descriptions[idx % len(video_descriptions)],
"url": video_url,
})
record_id += 1
# Plain text data (the url field contains text, and dense_mm also generates a corresponding text vector)
insert_data.append({
'id': record_id,
'document': 'A vector database converts text into high-dimensional vectors for semantic search, understanding the true intent of queries.',
'url': 'A vector database converts text into high-dimensional vectors for semantic search, understanding the true intent of queries.',
})
record_id += 1
insert_data.append({
'id': record_id,
'document': 'Deep learning models learn feature representations from large image datasets for tasks such as image classification and object detection.',
'url': 'Deep learning models learn feature representations from large image datasets for tasks such as image classification and object detection.',
})
BATCH_SIZE = 20
print(f"Preparing to insert {len(insert_data)} records, batch_size={BATCH_SIZE}...")
for batch_start in range(0, len(insert_data), BATCH_SIZE):
batch = insert_data[batch_start:batch_start + BATCH_SIZE]
client.insert(collection_name, batch)
print(f" Inserted {min(batch_start + BATCH_SIZE, len(insert_data))}/{len(insert_data)} records")
print("Data insertion complete!\n")
# ========== Test 1: Text-to-text search (semantic search via the dense field) ==========
print("=" * 60)
print("Test 1: Text-to-text search - query content related to vector databases")
print("=" * 60)
results = client.search(
collection_name=collection_name,
data=['What is semantic search? How does a vector database work?'],
anns_field='dense',
limit=3,
output_fields=['document', 'url'],
)
for hits in results:
for hit in hits:
print(f" id={hit['id']}, distance={hit['distance']:.4f}, document={hit['entity']['document'][:80]}")
# ========== Test 2: Text-to-image/video search (query multimedia content via the dense_mm field using text) ==========
print("\n" + "=" * 60)
print("Test 2: Text-to-image/video search - search for banana-related images and video assets using a text description")
print("=" * 60)
results = client.search(
collection_name=collection_name,
data=['yellow bananas'],
anns_field='dense_mm',
limit=3,
output_fields=['document', 'url'],
)
for hits in results:
for hit in hits:
has_image = "has image" if hit['entity'].get('url') else "no image"
print(f" id={hit['id']}, distance={hit['distance']:.4f}, [{has_image}] document={hit['entity']['document'][:80]}")
# ========== Test 3: Image-to-image/video search (query multimedia content via the dense_mm field using visual assets) ==========
print("\n" + "=" * 60)
print("Test 3: Image-to-image/video search - search for similar images and videos using a visual asset from the orange directory")
print("=" * 60)
results = client.search(
collection_name=collection_name,
data=[orange_url_list[0]],
anns_field='dense_mm',
limit=3,
output_fields=['document', 'url'],
)
for hits in results:
for hit in hits:
has_media = "has media" if hit['entity'].get('url') else "no media"
print(f" id={hit['id']}, distance={hit['distance']:.4f}, [{has_media}] document={hit['entity']['document'][:80]}")Output
Preparing to insert 27 records, batch_size=20...
Inserted 20/27 records
Inserted 27/27 records
Data insertion complete!
============================================================
Test 1: Text-to-text search - query content related to vector databases
============================================================
id=26, distance=0.8197, document=A vector database converts text into high-dimensional vectors for semantic search, understanding the true intent of queries.
id=27, distance=0.3091, document=Deep learning models learn feature representations from large image datasets for tasks such as image classification and object detection.
id=22, distance=0.2337, document=A short video of a fruit store display, with close-up shots of the fruit details.
============================================================
Test 2: Text-to-image/video search - search for banana-related images and video assets using a text description
============================================================
id=9, distance=0.4862, [has image] document=A fruit vendor weighing a large bunch of fresh bananas for a customer, the scale showing exactly three jin.
id=1, distance=0.4834, [has image] document=A bunch of ripe yellow bananas hanging from a tree in a tropical orchard, with sunlight casting dappled shadows through the leaves.
id=7, distance=0.4797, [has image] document=Wild banana trees growing in clusters in the tropical rainforest, their large leaves gently swaying in the breeze.
============================================================
Test 3: Image-to-image/video search - search for similar images and videos using a visual asset from the orange directory
============================================================
id=11, distance=1.0000, [has media] document=Oranges hanging from branches in the orchard gleam golden in the sunlight, a joyful harvest season.
id=12, distance=0.9898, [has media] document=A glass of freshly squeezed orange juice on the table, with cut oranges beside it, the flesh plump and juicy.
id=13, distance=0.9858, [has media] document=Mom is peeling oranges in the kitchen, the air filled with a fresh citrus fragrance, as the children gather around waiting to eat.