ApsaraDB for Memcache runs on a cluster-based architecture with built-in data partitioning and reading algorithms. Routing and sharding are handled transparently — your application connects to a uniform domain and the cluster manages the rest.
How it works
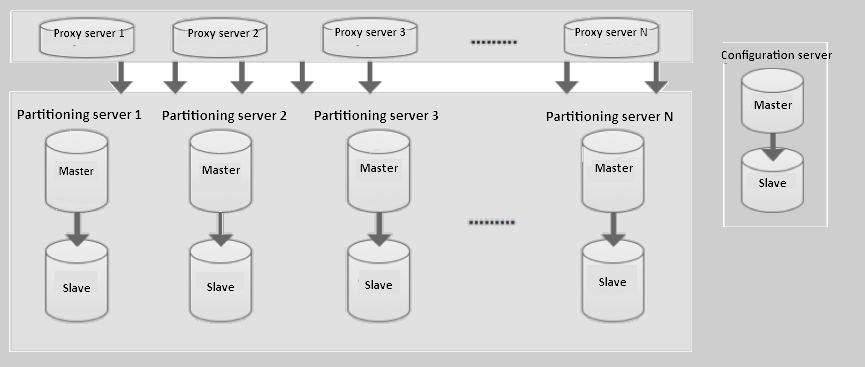
When your application sends a cache request, it goes to a proxy server. The proxy routes the request to the correct partitioning server based on the partitioning algorithm. The configuration server stores the cluster topology and partitioning policies, so the proxy always knows where each key lives.
Components
ApsaraDB for Memcache comprises three components: the proxy server, the partitioning server, and the configuration server.
Proxy server
The proxy server is the entry point for all cache requests. Each proxy server is a single node. A cluster can include multiple proxy servers, and the system handles load balance and failover across them automatically.
Partitioning server
Each partitioning server stores a partition of your cache data. Partitioning servers run in a dual-copy, master-slave architecture. If the master node fails, the system automatically triggers master-slave switchover to the replica, keeping the service available without manual intervention.
Configuration server
The configuration server stores the cluster configuration information and partitioning policies. It also runs in a dual-copy architecture to maintain high availability.
Usage notes
The number of proxy servers, partitioning servers, and configuration servers scales with the instance specification you purchase.
ApsaraDB for Memcache exposes a uniform domain for access. All cache reads and writes go through this domain. The proxy server, partitioning server, and configuration server are internal components and cannot be accessed directly.