Runtime environments of PyODPS DataFrame
When you use PyODPS DataFrame, code runs in two distinct environments: your local machine (the on-premises environment) and a MaxCompute executor in the cloud. Functions passed to map, apply, map_reduce, or custom aggregate operations run inside the MaxCompute executor — not locally. Understanding this boundary prevents import errors, package conflicts, and data access failures.
Execution model
PyODPS is a Python package, not a Python implementation. It runs in standard Python environments and behaves like any common Python interpreter.
Consider the following example:
from odps import ODPS, options
import numpy as np
o = ODPS(...)
df = o.get_table('pyodps_iris').to_df()
coeffs = [0.1, 0.2, 0.4]
def handle(v):
import numpy as np
return float(np.cosh(v)) * sum(coeffs)
options.df.supersede_libraries = True
val = df.sepal_length.map(handle).sum().execute(libraries=['numpy.zip', 'other.zip'])
print(np.sinh(val))The following diagram shows the systems involved when this code runs. Everything outside MaxCompute is the on-premises environment.
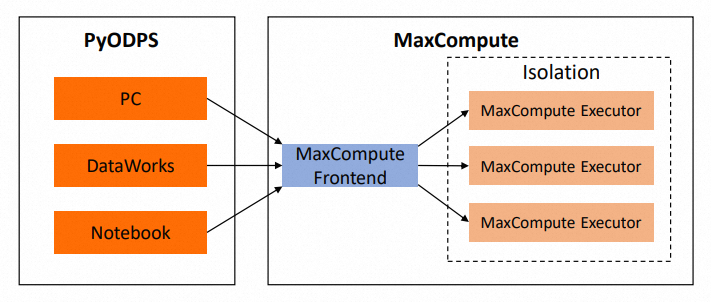
All code except the handle function body runs on the on-premises environment. The handle function is passed to map but is not called there — it is submitted to MaxCompute and executed remotely.
When handle is passed to map with the MaxCompute backend, PyODPS processes it in three phases:
The cloudpickle module extracts the closure and bytecode from the function.
PyODPS DataFrame uses the closure and bytecode to generate a Python user-defined function (UDF) and submits it to MaxCompute.
If you run jobs in MaxCompute by using SQL statements, the generated Python UDF is called, the bytecode and closure are unpickled, and the UDF is executed in a MaxCompute executor.
Execution boundary
Code location | Runs on |
Top-level imports and statements | On-premises environment |
Function body passed to | MaxCompute executor |
All code when using pandas backend | On-premises environment |
Constraints in a MaxCompute executor
The following constraints apply to any function body you pass to map, apply, map_reduce, or custom aggregate functions when the MaxCompute backend is active.
Local packages are not available. Only packages available in MaxCompute executors can be referenced inside the function body. In the example above, other.zip listed in libraries=['numpy.zip', 'other.zip'] must exist as a MaxCompute resource. Uploading it to MaxCompute is not enough if it is absent from the on-premises environment.
Import packages inside the function body. If you import a package outside the function and reference it inside, an error may occur. cloudpickle sends the reference to the on-premises package, but the package structure may not be compatible with the MaxCompute executor. Import the package inside the function body instead, as shown in the handle function in the example.
External variables are captured by value. If you reference a variable defined outside the function (such as coeffs in the example) and modify it inside the function body, the on-premises value is retained. The modification does not propagate back to the on-premises environment.
Code from other files must exist in the executor. If the function body references code from another file, the package containing that file must be available in the MaxCompute executor. If you prefer not to package it as a third-party resource, store all referenced personal code in the same file.
Third-party packages must be integrated with Python 2.7 (UCS-2). The uploaded third-party package must be integrated with Python 2.7, which uses UCS-2, in a MaxCompute executor.
No direct access to other MaxCompute tables. MaxCompute executors do not support connections to endpoints or Tunnel endpoints, and no PyODPS package is available inside the executor. You cannot use ODPS entry objects or PyODPS DataFrame to access other MaxCompute tables from within a function body, and you cannot pass these objects in from outside.
For small tables: pass the table as a DataFrame resource.
For large tables: use a table join instead.
Use third-party packages
How you use third-party packages depends on where your code runs.
Personal computer or on-premises server. Install the package for the required Python version using pip or your package manager.
Notebook. Contact your platform provider for instructions on installing packages.
DataWorks. Installing packages directly on the on-premises system is not supported in DataWorks. Instead, reference third-party packages by reading the file and running the exec command. For details, see Use a PyODPS node to reference a third-party package.
The directory structure shown in DataStudio is not the actual directory structure on the file system. Importing or opening a path displayed in DataStudio will fail.
After uploading resources in DataWorks, click Submit to make sure the resources are uploaded to MaxCompute.
To use a custom NumPy version, set
odps.df.supersede_libraries = Truein your code and specify the NumPy package name as the first entry in thelibrariesparameter when uploading the required wheel package.
Access data in other MaxCompute tables
How you access other MaxCompute tables depends on where your code runs.
On-premises environment (personal computer, on-premises server, Notebook, or DataWorks). Use on-premises code to access the table. If you can reach the endpoint, use PyODPS or PyODPS DataFrame. If you cannot reach the endpoint, contact your platform provider.
Inside `map`, `apply`, `map_reduce`, or custom aggregate functions. MaxCompute executors do not support endpoint or Tunnel endpoint connections, and no PyODPS package is available. You cannot use ODPS entry objects or PyODPS DataFrame to access other tables, and you cannot pass these objects in from outside.
For small tables: pass the table as a DataFrame resource.
For large tables: use a table join instead.
Pandas backend behavior
When you use the pandas backend, all code runs on the on-premises environment. Install all required packages locally.
When you switch from the pandas backend to MaxCompute for production, comply with the MaxCompute backend rules for package installation.