MaxCompute provides two MapReduce programming interfaces with specific usage limits.
MaxCompute provides two MapReduce programming interfaces:
-
MaxCompute MapReduce: The native MaxCompute interface. Offers fast execution, rapid development, and no file system exposure.
-
MaxCompute Extended MapReduce (MR2): Supports more complex job scheduling with the same implementation as the native interface. Unlike traditional MapReduce, MR2 changes the underlying scheduling and I/O model to eliminate redundant I/O operations.
These interfaces are largely consistent in Terms, job submission, Inputs and outputs, and Resource usage, differing only in their Java SDKs. Hadoop MapReduce Tutorial.
MapReduce cannot read from or write to external tables.
MapReduce
Use cases
MapReduce supports the following use cases:
-
Search: web crawling, inverted indexing, and PageRank.
-
Web access log analysis:
-
Analyze user browsing and shopping behavior for personalized recommendations.
-
Analyze user access patterns.
-
-
Text analytics:
-
Word count (WordCount) and TF-IDF analysis on popular novels.
-
Citation analysis for academic papers and patents.
-
Wikipedia data analysis.
-
-
Big data mining: unstructured, spatiotemporal, and image data.
-
Machine learning: supervised learning, unsupervised learning, and classification algorithms such as decision trees and SVM.
-
Natural language processing (NLP):
-
Training and prediction on big data.
-
Word co-occurrence matrix construction, frequent itemset mining, and duplicate document detection.
-
-
Ad recommendations: click-through rate (CTR) and conversion rate (CVR) prediction.
How MapReduce works
MapReduce processes data in two phases: Map and then Reduce. You implement the processing logic for both phases within the MapReduce framework. The complete workflow is as follows:
-
Input: Split the input data into equal-sized blocks. Each block is fed to a separate Map worker for parallel processing.
-
Map: Each Map worker reads and processes data, then assigns a key to each output record. The key determines which Reduce worker receives the record.
NoteKeys and Reduce workers have a many-to-one relationship. Records with the same key go to the same Reduce worker, and a single Reduce worker can receive records with different keys.
-
Shuffle: Before the Reduce phase, the framework sorts data by key so that records with the same key are adjacent. If you specify a Combiner, the framework aggregates records with the same key. You can implement custom Combiner logic. Unlike classic MapReduce, MaxCompute requires that Combiner input and output parameters match those of Reduce. This process is also called Shuffle.
-
Reduce: Records with the same key are sent to the same Reduce worker. Each Reduce worker receives data from multiple Map workers and performs the Reduce operation on records grouped by key, producing a single output value per key.
-
Output the results.
This is a brief overview of the MapReduce framework. Terms.
The following WordCount example illustrates each MapReduce stage.
Suppose a text file a.txt contains one number per line and you want to count the occurrences of each number. Each number is a Word, and its occurrence count is the Count. The following diagram shows how MapReduce completes this task.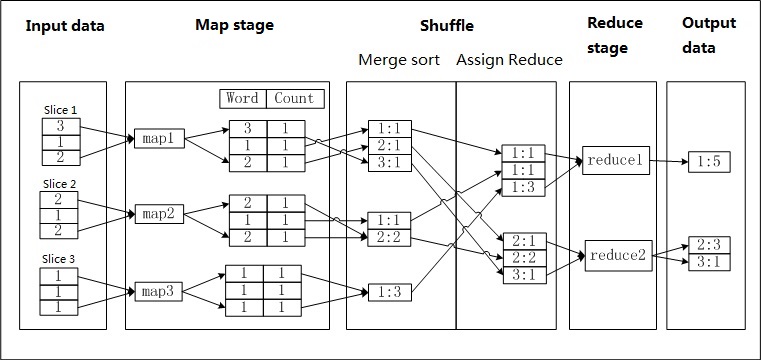
Procedure
-
Input: Split the text into blocks and feed each block to a Map worker.
-
Map: For each number read, set its Count to 1 and output a <Word, Count> pair, using the Word as the key.
-
Shuffle > Combine and sort: Sort each Map worker's output by key (Word), then run the Combiner to aggregate Counts for records with the same Word into a new <Word, Count> pair.
-
Shuffle > Distribute to Reduce: Send data to Reduce workers. Each Reduce worker re-sorts the received data by key.
-
Reduce: Each Reduce worker aggregates Counts for records with the same Word, using the same logic as the Combiner, and outputs the final result.
-
Output the results.
All data in MaxCompute is stored in tables. Therefore, MapReduce input and output can only be tables. Custom output formats and file system interfaces are not supported.
Limits
-
General MapReduce limits: Limitations.
-
For MapReduce limits on local runs, see Local run.
Extended MapReduce (MR2)
MR2 is largely consistent with MaxCompute MapReduce in how Map and Reduce functions are written. The main differences are in job execution. For examples, see Pipeline examples.
Background
Traditional MapReduce requires that output data from each round be stored in a distributed file system (such as HDFS or MaxCompute tables). A multi-job MapReduce pipeline writes intermediate data to disk after each job, but the subsequent Map task often only needs to read that data once for the Shuffle phase, resulting in redundant disk I/O.
MaxCompute supports more complex programming models. It can chain a Reduce directly after another Reduce without an intermediate Map step. This enables pipelines with any number of chained Reduce operations after Map, such as Map > Reduce > Reduce, eliminating unnecessary I/O.
Comparison with Hadoop Chain Mapper/Reducer
Hadoop Chain Mapper/Reducer supports similar chained Map or Reduce operations, but differs fundamentally from MaxCompute MR2.
Chain Mapper/Reducer builds on the traditional MapReduce model and only allows appending one or more Mapper operations after an existing Mapper or Reducer (no additional Reducers). This lets you reuse existing Mapper logic by splitting a Map or Reduce into multiple Mapper stages, but does not change the underlying scheduling or I/O model.